复制功能是指创建 Cloud SQL 实例或本地数据库的副本,并将工作分流到副本。
简介
使用复制功能的主要原因是在不降低性能的情况下扩大数据库中的数据使用量。
其他原因包括:
- 在区域之间迁移数据
- 在平台之间迁移数据
- 将数据从本地数据库迁移到 Cloud SQL
此外,如果原始实例已损坏,则系统可能会提升副本。
在引用 Cloud SQL 实例时,用于复制的实例称为主实例,而副本则称为读取副本。主实例和读取副本都驻留在 Cloud SQL 中。
在引用本地数据库时,复制场景称为从外部服务器复制。在此场景中,用于复制的数据库是源数据库服务器。驻留在 Cloud SQL 中的副本称为 Cloud SQL 副本。在 Cloud SQL 中,还有一个表示源数据库服务器的实例,该实例称为源表示形式实例。
在灾难恢复场景中,您可以提升副本,以将其转换为主实例。这样,您就可以使用此主实例来替代服务中断的区域中的实例。您还可以提升副本来替换损坏的实例。
Cloud SQL 支持以下类型的副本:
通过强制使用连接器,您可以强制仅使用 Cloud SQL Auth 代理或 Cloud SQL 语言连接器连接到 Cloud SQL 实例。强制使用连接器后,Cloud SQL 会拒绝与数据库的直接连接。您无法为要求强制使用连接器的实例创建读取副本。同样,如果实例具有读取副本,则您无法对该实例要求强制使用连接器。
您还可以使用 Database Migration Service 从源数据库服务器持续复制到 Cloud SQL。注意:借助 Cloud SQL,用户可以使用 PostgreSQL 的逻辑复制功能管理自己的复制操作。Cloud SQL 不支持两个外部服务器之间的复制。
只读副本
您可以使用读取副本从 Cloud SQL 实例中分流工作。读取副本是主实例的精确副本。主实例上的数据和其他更改几乎在读取副本上实时更新。
读取副本是只读副本;您无法将数据写入其中。读取副本会处理查询、读取请求和分析流量,从而减少主实例的负载。
您可以使用副本的连接名称和 IP 地址直接连接到副本。如果您要使用专用 IP 地址连接到副本,则无需为副本创建其他 VPC 专用连接,因为连接是从主实例继承的。
如需了解如何创建只读副本,请参阅创建只读副本。如需了解如何管理只读副本,请参阅管理只读副本。
在主实例上使用 HA 时,最好将只读副本放在与主实例不同的可用区中。这种做法可确保只读副本在包含主实例的可用区中断服务时继续运行。如需了解详情,请参阅高可用性概览。
选择适当的机器类型
读取副本的 vCPU 数量和内存量可以与主实例不同。您应该监控实例上的指标(例如 CPU 和内存用量),以确保副本实例的大小适合其工作负载,特别是在副本实例小于主实例时。容量不足的副本实例更有可能出现性能不佳的情况,例如频繁的内存不足 (OOM) 事件。
读取副本上的存储空间容量
调整主实例的大小后,系统会根据需要调整其所有读取副本的大小,使其至少具有与更新后的主实例一样大的存储空间容量。
当读取副本的机器类型内存少于主实例时对 max_connections 标志的影响
在 PostgreSQL 实例上,如果您未将 max_connections 标志设置为您选择的值,则 Cloud SQL 会根据实例的内存量自动设置此标志。如需了解详情,请参阅支持的标志。PostgreSQL 要求 max_connections 的值在读取副本上始终至少与其在主实例上一样大。因此,如果读取副本的内存小于其主实例,并且您尚未设置 max_connections 标志,则它可能会根据主实例的大小继承更大的 max_connections 值。在这种情况下,如果您依赖 max_connections 设置来限制与副本实例的连接数,则它可能会过载,因为该值相对于实例的机器类型来说太高了。要避免这种情况,您可以执行以下任何操作:
- 将副本实例大小调整为更大的机器类型。
- 配置客户端应用,将其限制为小于
max_connections值的一定数量的连接。 - 将主实例和副本上的
max_connections标志设置为适当的值。
使用读取副本的哈希索引操作
对于 PostgreSQL 9.6,哈希索引操作不使用预写式日志记录。在 PostgreSQL 10 下,Cloud SQL 只有一个可用的版本。相关说明请参阅 PostgreSQL 版本页面上的黄色警告框。这也适用于 Cloud SQL 读取副本。
由于哈希索引更新不会传播到低于 PostgreSQL 9.6 的读取副本,因此副本无法使用它们。如需解决此问题,您可以避免使用读取副本或升级到主要 PostgreSQL 版本(10 或更高版本)。
跨区域读取副本
您可以利用跨区域复制功能,在与主实例不同的区域中创建只读副本。创建跨区域只读副本的方式与创建区域内副本的方式相同。
使用跨区域副本具有以下优势:
- 在更接近应用所在区域的位置提供副本,从而提高读取性能。
- 提供更高的灾难恢复能力,可防范区域性故障。
- 可让您将数据从一个区域迁移到另一个区域。
如需详细了解跨区域副本,请参阅提升副本以实现区域性迁移或灾难恢复。
级联读取副本
通过级联复制功能,您可以在相同或不同区域中的一个读取副本下创建另一个读取副本。以下场景是使用级联副本的应用场景:
- 灾难恢复:您可以使用读取副本的级联层次结构来模拟主实例及其读取副本的拓扑。在服务中断期间,您选择的读取副本将提升为主实例,并且新主实例下的读取副本会继续复制并可供使用。
- 性能提升:通过将复制工作分流到多个读取副本来减轻主实例的负担。
- 扩缩读取:您可以有更多副本来分担读取负载。
- 费用降低:通过在其他区域中将单个级联副本与跨区域复制结合使用,您可以减少网络费用。
术语
- 级联副本:自身可以具有副本的读取副本。
- 级层:您可以在级联副本层次结构中创建多个级层的副本。例如,如果您向一个实例添加 4 个副本,则这 4 个副本处于同一级层。
- 同级实例:从同一主实例复制的多个副本。同级对象在副本层次结构中处于同一级层。一个副本最多支持 8 个同级对象。
- 叶副本:自身没有任何副本的读取副本。 在多级复制层次结构中,叶副本处于最后一个级层。
- 提升:用于将处于层次结构中任意级层的副本转换为主实例的操作。提升后,副本的级联副本层次结构会保留。
配置级联副本
级联副本让您可以将读取副本添加到任何现有副本。您最多可以添加 4 个级层的副本,包括主实例。将副本提升到级联副本层次结构的顶层后,它将成为主实例,并且其级联副本会继续复制。
如需规划配置,您需要设定有关读取副本要执行的操作的目标。接下来的两个部分介绍了适用于灾难恢复和多区域复制场景的配置。
灾难恢复
如需了解级联副本如何帮助您在服务中断期间快速恢复,请考虑以下复制场景:
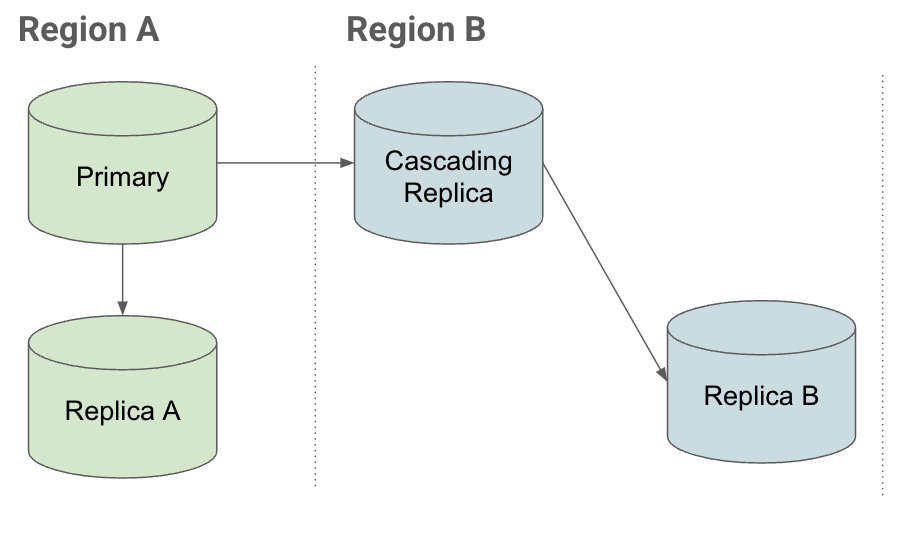
配置
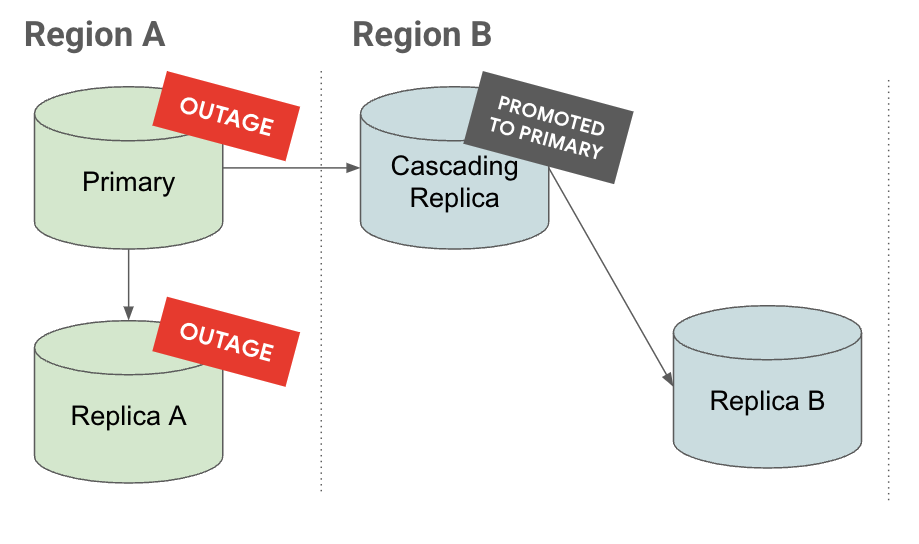
服务中断
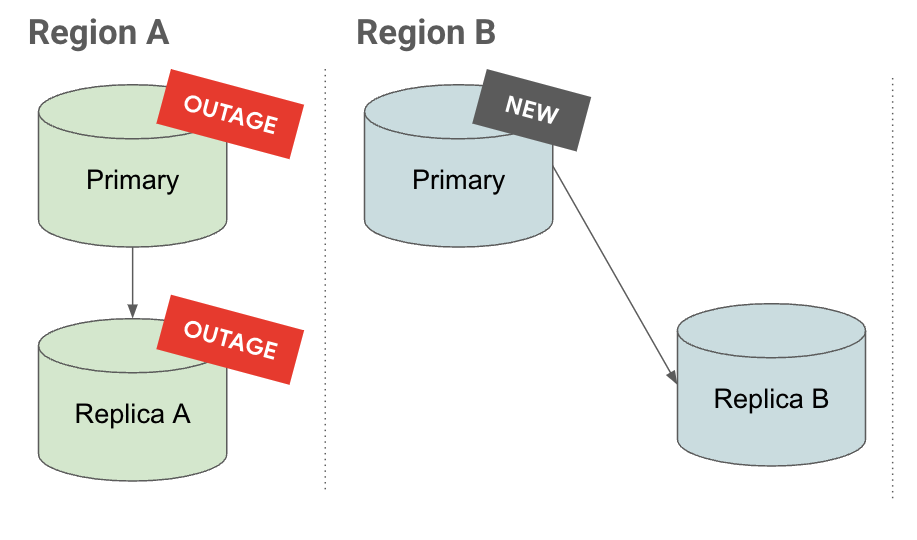
提升
如果您要在灾难恢复配置中使用区域 B 中的实例,并且
- 将同一区域中的副本附加到主实例(副本 A)
- 将其他区域中的副本(级联副本)附加到主实例。
您可以在区域 B 中的级联副本下创建读取副本。
在服务中断标签页上,如果区域 A 发生服务中断,则级联副本会提升为主实例。级联副本下面已有读取副本,从而减少了恢复时间目标 (RTO)。
在提升标签页上,您可以看到级联副本提升后,其副本也会提升并继续在其下复制。
多区域复制
级联副本的另一个使用场景是以经济实惠的方式将读取容量分布到第二个区域。您可以创建从副本 B 复制的级联副本 C 和 D。客户端可以在副本 B、C 和 D 之间分布读取查询,以减少每个副本的负载。跨区域网络流量的费用仅会在主实例到副本 B 时产生一次。从 B 到 C 和 D 的复制使用免费的区域内网络传输。
您可以将级联副本用于多区域复制来创建最多包含 4 个实例的层次结构:
主实例 A → 副本 B → 副本 C 和副本 D
限制
- 您无法删除其下包含副本的副本。如需删除副本,您必须从叶副本开始,然后向上通过层次结构。
- 系统不支持循环区域依赖。如需将级联副本的副本存放在与主实例相同的区域,该级联副本自身也必须位于同一区域。
逻辑复制
借助 Cloud SQL,您可以使用 PostgreSQL 的逻辑复制功能配置自己的复制解决方案。逻辑复制是一种灵活的解决方案,支持以下各项:
- 从主实例到副本的标准复制
- 仅特定表或行的选择性复制
- PostgreSQL 主要版本之间的复制
- 到非 PostgreSQL 数据库的复制
- 变更数据捕获 (CDC) 工作流,其中的所有数据库更改都会流式传输到使用方
如需了解详情,请参阅设置逻辑复制。该页面包含以下信息:
- 内置逻辑复制
- pglogical 扩展程序
复制功能的使用场景
以下使用场景适用于每种复制类型。
| 名称 | 主要 | 副本 | 优势和用例 | 更多信息 |
|---|---|---|---|---|
| 读取副本 | Cloud SQL 实例 | Cloud SQL 实例 |
|
|
| 跨区域读取副本 | Cloud SQL 实例 | Cloud SQL 实例 |
|
|
| 逻辑复制 | 任何 PostgreSQL 独立实例或主实例 | 任何 PostgreSQL 实例或外部使用方 |
|
结算
- 读取副本按与标准 Cloud SQL 实例相同的费率计费。系统不会对数据复制操作收费。
- 跨区域读取副本的价格与在同一区域中创建新 Cloud SQL 实例时的价格相同。请参阅 Cloud SQL 实例价格并选择相应的区域。除了与实例关联的常规费用之外,跨区域副本还会因从主实例发送到副本实例的复制日志而产生跨区域数据传输费用,如网络出站流量价格中所述。
Cloud SQL 读取副本的快速参考信息
| 主题 | 讨论 |
|---|---|
| 备份 | 您不能为副本配置备份。 |
| 核心和内存 | 读取副本使用的核心数和内存量可能与主实例不同。 |
| 删除主实例 | 您必须先将主实例的所有读取副本提升为独立实例或删除它们,然后才能删除主实例。 |
| 删除副本 | 删除副本对主实例的状态没有影响。 |
| 停用预写式日志记录 | 您必须先提升或删除主实例的所有读取副本,然后才能停用主实例上的预写式日志。 |
| 故障切换 | 仅当副本是灾难恢复副本时,主实例才能故障切换到副本。在服务中断期间,读取副本无法以任何方式进行故障切换。 |
| 高可用性 | 读取副本使您可以在副本上启用高可用性。 |
| 负载均衡 | Cloud SQL 不会在各副本之间提供负载均衡。您可以选择为 Cloud SQL 实例实现负载均衡。您还可以使用连接池在具有负载均衡设置的各副本之间分配查询,以提高性能。 |
| 维护期 | 读取副本与主实例共享维护窗口。副本遵循主实例的维护设置,包括维护窗口、重新安排和拒绝维护期。在维护期间,Cloud SQL 会先更新所有读取副本,然后再更新主实例。 |
| 多个读取副本 | Cloud SQL 支持级联副本。因此,您最多可以为一个主实例创建 10 个副本,并创建这些副本的副本,最多可达四层,包括主实例在内。 |
| 专用 IP | 如果您要使用专用 IP 地址连接到副本,则无需为副本创建其他 VPC 专用连接,因为它是从主实例继承的。 |
| 恢复主实例 | 当副本存在时,您无法恢复副本的主实例。在通过备份来恢复实例或对实例执行时间点恢复之前,您必须先提升或删除实例的所有副本。 |
| 设置 | 主实例的设置会传播到副本,包括 postgres 用户的密码及对用户表的更改。 |
| 停止副本 | 您不能对副本执行 stop 操作。您可以对它执行 restart、delete 或 disable replication 操作,但不能像停止主实例那样对其执行停止操作。 |
| 升级副本 | 读取副本随时可能出现升级中断。 |
| 用户表 | 您不能对副本进行更改。所有用户更改都必须在主实例上完成。 |
后续步骤
- 了解如何创建只读副本。
- 了解如何配置实例以实现高可用性。
- 了解高级灾难恢复 (DR)