本页面介绍 Spanner 在生产环境中的配额和限制。配额和限制在 Google Cloud 控制台中可以互换使用。
配额和限制值随时可能更改。
用于检查和修改配额的权限
如需查看配额,您必须拥有 serviceusage.quotas.get Identity and Access Management (IAM) 权限。
如需更改您的配额,您必须拥有 serviceusage.quotas.update 权限。默认情况下,以下预定义角色包含此权限:Owner、Editor 和 Quota Administrator。
基本 IAM 角色 Owner 和 Editor 以及预定义的 Quota Administrator 角色中默认包含这些权限。
查看您的配额
如需检查您项目中资源的当前配额,请使用Google Cloud 控制台:
增加您的配额
随着您的 Spanner 使用量逐步增加,您可以相应地增加配额。如果您预计后续用量会显著增加,则应提前几天提出申请,以确保您的配额足够使用。
您可能还需要增加使用方配额替换值。如需了解详情,请参阅创建使用方配额替换值。
您可以使用 Google Cloud 控制台增加当前 Spanner 实例配置节点限制。
转到配额页面。
在服务下拉列表中选择 Spanner API。
如果看不到 Spanner API,则表示尚未启用 Spanner API。如需了解详情,请参阅启用 API。
选择要更改的配额。
点击修改配额。
在显示的配额更改面板中,输入新的配额限制。
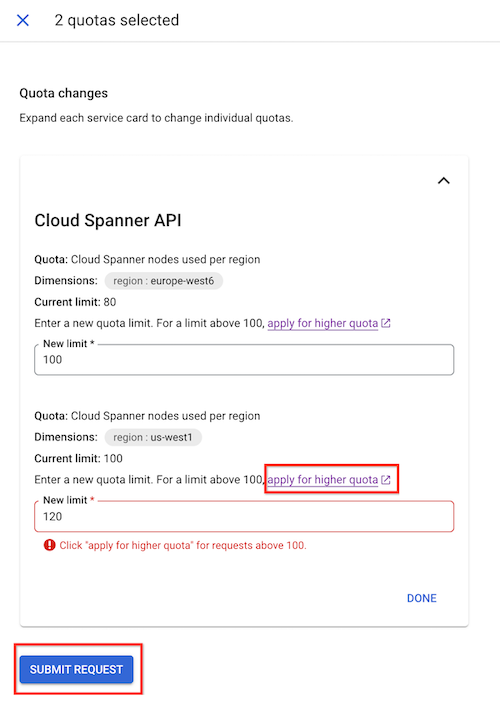
点击完成,然后点击提交请求。
如果您无法手动将节点限制增加到所需限制,请点击申请更高配额。填写此表单,以向 Spanner 团队提交请求。您将在提交申请后的 48 小时内收到回复。
增加自定义实例配置的配额
您可以为自定义实例配置增加节点配额。
通过检查基本实例配置的节点限制,检查自定义实例配置的节点限制。
如果您不知道或不记得自定义实例配置的基本配置,请使用 show instance configurations detail 命令。
如果自定义实例配置所需的节点限制小于 85,请按照前面增加配额部分中的说明操作。使用 Google Cloud 控制台增加与自定义实例配置关联的基本实例配置的节点限制。
如果自定义实例配置所需的节点限制超过 85,请填写为 Spanner 节点申请增加配额表单。在表单中指定您的自定义实例配置的 ID。
节点限制
| 值 | 限制 |
|---|---|
| 每个实例配置的节点数 |
默认限制因项目和实例配置而异。如需更改项目配额限制或申请提高限制,请参阅增加配额。 |
实例限制
| 值 | 限制 |
|---|---|
| 实例 ID 长度 | 2 到 64 个字符 |
免费试用实例限制
Spanner 免费试用实例具有以下额外限制。如需提高或移除这些限制,请将您的免费试用实例升级为付费实例。
| 值 | 限制 |
|---|---|
| 存储空间容量 | 10 GiB |
| 数据库限制 | 最多可创建 5 个数据库 |
| 不支持的功能 | 备份和恢复 |
| SLA | 无 SLA |
| 试阅期 | 90 天免费试用期 |
地理分区限制
| 值 | 限制 |
|---|---|
| 每个实例的分区数上限 | 20 |
| 您的分区中每个节点的放置行数上限 | 1 亿 |
保存的查询限制
| 值 | 限制 |
|---|---|
| 每个项目的保存的查询数上限(包括其他 Google Cloud 产品的保存的查询) | 10000 |
| 每个查询的大小上限 | 1 MiB |
实例配置限制
| 值 | 限制 |
|---|---|
| 每个项目的自定义实例配置数上限 | 100 |
| 自定义实例配置 ID 长度 | 8 至 64 个字符 自定义实例配置 ID 必须以 |
数据库限制
| 值 | 限制 |
|---|---|
| 每个实例的数据库数 |
|
| 每个数据库的角色数 | 100 |
| 数据库 ID 长度 | 2 到 30 个字符 |
| 存储空间使用量1 |
在大多数区域级、双区域和多区域 Spanner 实例配置中,每个节点的存储容量均可增加至 10 TiB。如需了解详情,请参阅提高性能和存储空间。 如果您使用分层存储,则每个节点最多可以使用 10 TiB 的组合存储空间(SSD 和 HDD)。 备份会单独存储,不计入此限制。如需了解详情,请参阅存储空间利用率指标。 请注意,Spanner 会按实例内实际使用的存储空间收费,而不是按其总可用存储空间收费。 |
备份和恢复限制
| 值 | 限制 |
|---|---|
| 每个数据库正在进行的“创建备份”操作数 | 1 |
| 每个实例正在进行的“恢复数据库”操作数(在恢复的数据库实例中,而不是在备份中) | 10 |
| 备份的最长保留时间 | 1 年(包括闰年多出的一天) |
架构限制
架构对象
| 值 | 限制 |
|---|---|
| 同一实例中所有数据库内的架构对象总数 | 默认限制因实例配置而异2 |
DDL 语句
| 值 | 限制 |
|---|---|
| 单个架构更改的 DDL 语句大小 | 10 MiB |
数据库整个架构的 DDL 语句大小(由 GetDatabaseDdl 返回) |
10 MiB |
图表
| 值 | 限制 |
|---|---|
| 每个数据库的属性图表 | 16 |
| 属性图表名称长度 | 1 到 128 个字符 |
表
| 值 | 限制 |
|---|---|
| 每个数据库的表数 | 5,000 |
| 表名称长度 | 1 到 128 个字符 |
| 每个表的列数 | 1024 |
| 列名称长度 | 1 到 128 个字符 |
| 每个单元格的数据大小上限 | 10 MiB |
STRING 单元格的大小 |
2,621,440 个 Unicode 字符 |
| 表键中的列数 | 16 包括与任何父表共享的键列 |
| 表交错深度 | 7 包含子表的顶层表的深度为 1。 包含孙表的顶层表的深度为 2,后续嵌套表的深度会相应增加。 |
| 每行主键或索引键的大小上限 | 8 KiB 包括构成相应键的所有列的大小 |
| 每行非键列的总大小 | 1,600 MiB 包括表中每行的所有非键列的大小 |
索引
| 值 | 限制 |
|---|---|
| 每个数据库的索引数 | 10000 |
| 每个表的索引数 | 128 |
| 索引名称长度 | 1 到 128 个字符 |
| 索引键中的列数 | 16 编入索引的列的数量(STORING 列除外)加上基表中主键列的数量 |
视图
| 值 | 限制 |
|---|---|
| 每个数据库的视图数 | 5,000 |
| 视图名称长度 | 1 到 128 个字符 |
| 嵌套深度 | 10 对于引用其他视图的视图,其嵌套深度为 1。对于引用其他视图并且该视图又引用另外视图的视图,其嵌套深度为 2,以此类推。 |
位置组
| 值 | 限制 |
|---|---|
| 每个数据库的存放区域群组数上限 | 16 个(1 个默认存放区域群组和 15 个可选的其他存放区域群组) |
ssd_to_hdd_spill_timespan 选项中所需的时长下限 |
1 小时 |
ssd_to_hdd_spill_timespan 选项中允许的时长上限 |
365 天 |
查询限制
| 值 | 限制 |
|---|---|
一个 GROUP BY 子句中的列数 |
1000 |
IN 运算符中的值 |
10000 |
| 函数调用次数 | 1000 |
| 联接 | 20 |
| 嵌套函数调用次数 | 75 |
嵌套 GROUP BY 子句数量 |
35 |
| 嵌套子查询表达式数量 | 25 |
| 嵌套子选择语句数 | 60 |
| 图表查询生成的联接 | 100 |
| 参数 | 950 |
| 查询语句长度 | 1 百万个字符 |
STRUCT 个字段 |
1000 |
| 子查询表达式子项数 | 50 |
| 查询中的 union 数 | 200 |
| 图表量化路径遍历的深度 | 100 |
创建、读取、更新和删除数据的限制
| 值 | 限制 |
|---|---|
| 提交大小(包括索引和变更数据流) | 100 MiB |
| 每个会话的并发读取数 | 100 |
| 每次提交包含的变更数(包括索引)3 | 80,000 |
| 批量写入请求中每个变更组的变更数 | 80,000 |
| 每个数据库的并发分区 DML 语句数 | 20,000 |
管理限制
| 值 | 限制 |
|---|---|
| 管理操作的请求大小4 | 1 MiB |
| 管理操作的速率限制5 | 每位用户每个项目每秒 5 次 (按 100 秒计算得到的平均值) |
请求限制
| 值 | 限制 |
|---|---|
| 请求大小(提交除外)6 | 10 MiB |
变更数据流限制
| 值 | 限制 |
|---|---|
| 每个数据库的变更数据流 | 10 |
| 监控任何给定非键列的变更数据流数7 | 3 |
| 每个变更数据流数据分区的并发读取器数8 | 20 |
Data Boost 限制
| 值 | 限制 |
|---|---|
| 在 us-central1 中,每个项目的并发 Data Boost 请求数 | 1000 9 |
| 其他区域每个项目的并发 Data Boost 请求数 | 400 9 |
预拆分 API 限制
| 值 | 限制 |
|---|---|
| 每个 API 请求添加的拆分点 | 100 |
| 拆分点 API 请求大小 | 1 MiB |
| 为实例中的所有数据库按节点添加的拆分点 | 50 |
| 每个节点每分钟添加或更新的拆分点 | 10 |
| 每个节点每天添加或更新的拆分点 | 200 |
备注
1. 为了保证数据库访问的高可用性和低延时,Spanner 根据实例的计算容量定义了存储限制:
- 对于小于 1 个节点(1,000 个处理单元)的实例,Spanner 会为数据库中每 100 个处理单元分配 1,024.0 GiB 数据。
- 对于 1 个节点及更大的实例,Spanner 会为每个节点分配 10 GiB 数据。
例如,要为 1,500 GiB 数据库创建实例,需要将其计算容量设置为 200 个处理单元。此计算容量将使实例保持在限制以下,直到数据库增长到 2,048.0 GiB 以上。数据库达到此大小后,您需要再添加 100 个处理单元以允许数据库增长。否则,对该数据库执行的写入操作可能会被拒绝。如需了解详情,请参阅数据库存储空间利用率建议。
为了获得平稳顺畅的扩容体验,请在数据库大小达到限制之前添加计算容量。
2. 计入架构对象包括 DDL 中所述的所有对象类型,例如表、列、索引、序列等。架构对象限制在实例级别强制执行,且取决于实例可用的处理单元。
- 对于一个节点或更大的实例,默认限制为 100 万个对象。
- 对于小于一个节点(1,000 个处理单元)的实例,该限制会根据实例大小成比例减少。 例如,对于具有 100 个处理单元的实例,限制为 10 万个架构对象。
如需检查数据库的架构对象数和实例的对象限制,请在 Metrics Explorer 中查找指标 spanner.googleapis.com/instance/schema_objects 和 spanner.googleapis.com/instance/schema_object_count。
如需详细了解监控,请参阅使用 Cloud Monitoring 监控实例。
如果您达到限制,Spanner 会阻止您执行超出限制的操作,例如:
- 修改数据库的架构(例如,添加索引)。
- 在实例中创建新数据库。
- 从备份中将数据库恢复到同一实例中。在这种情况下,您可以在相同配置的不同实例中恢复备份,或者使用相同配置创建新实例,然后在新实例中恢复备份。
3. 在为插入和更新操作计算更改数时,需要乘以受影响的列数,且主键列始终会受影响。例如,如果向五个列中插入值,则插入一条新记录的操作会被计为五项更改。如果记录具有两个主键列,则更新该记录中的三列也可能会被计为五项变更。无论受影响的列有多少个,删除操作和删除某个范围的操作都计为一项更改。无论交错式子行有多少个,从具有 ON DELETE
CASCADE 注释的父表中删除一行也计为一项更改。有一个例外,如果对要删除的行定义了二级索引,系统将单独计算二级索引的更改。例如,如果一个表有 2 个二级索引,则删除该表中的一系列行会计为该表的 1 项更改,外加对删除的每一行的 2 项更改,因为二级索引中的行可能分散在键空间,使得 Spanner 无法对二级索引调用单个删除范围的操作。二级索引包含外键和支持性索引。
如需查找事务的变更计数,请参阅检索事务的提交统计信息。
变更数据流不会添加任何计入此限制的变更。
4. 针对管理操作请求的限制不适用于提交、备注 9 中列出的请求和架构更改。
5. 此速率限制适用于对 Admin API 的所有调用,其中包括对针对实例、数据库或备份的长时间运行的操作进行轮询的调用。
6. 此限制适用于以下操作请求:创建数据库、更新数据库、读取、流式读取、执行 SQL 查询以及执行流式 SQL 查询。
7. 隐式监控整个表或数据库的变更数据流会监控该表或数据库中的每一列,因此会计入此限制。
8. 此限制适用于同一变更数据流分区的并发读取器,无论读取器是 Dataflow 流水线还是直接 API 查询。
9. 默认限制因项目和区域而异。如需了解详情,请参阅监控和管理 Data Boost 配额用量。