Best Practices für die Skalierung von Cloud Service Mesh in GKE
In dieser Anleitung werden Best Practices zum Beheben von Skalierungsproblemen für verwaltete Cloud Service Mesh-Architekturen in Google Kubernetes Engine beschrieben. Das Hauptziel dieser Empfehlungen ist es, die optimale Leistung, Zuverlässigkeit und Ressourcennutzung für Ihre Microservices-Anwendungen zu gewährleisten, wenn sie wachsen.
Informationen zu den Einschränkungen der Skalierbarkeit finden Sie unter Skalierbarkeitslimits für Cloud Service Mesh.
Die Skalierbarkeit von Cloud Service Mesh in GKE hängt vom effizienten Betrieb der beiden Hauptkomponenten ab: der Datenebene und der Steuerungsebene. In diesem Dokument geht es hauptsächlich um die Skalierung der Datenebene.
Skalierungsprobleme der Steuerungsebene und der Datenebene erkennen
In Cloud Service Mesh können Skalierungsprobleme entweder in der Steuerungsebene oder in der Datenebene auftreten. So können Sie herausfinden, welche Art von Skalierungsproblem vorliegt:
Symptome von Skalierungsproblemen der Steuerungsebene
Langsamer Dienstaufbau: Es dauert lange, bis neue Dienste oder Endpunkte erkannt und verfügbar werden.
Konfigurationsverzögerungen:Änderungen an Traffic-Management-Regeln oder Sicherheitsrichtlinien brauchen lange, bis sie übernommen werden.
Erhöhte Latenz bei Steuerungsebenenvorgängen:Vorgänge wie das Erstellen, Aktualisieren oder Löschen von Cloud Service Mesh-Ressourcen werden langsam oder reagieren nicht.
Fehler im Zusammenhang mit Traffic Director:In Cloud Service Mesh-Logs oder Steuerungsebenenmesswerten können Fehler auftreten, die auf Probleme mit der Konnektivität, der Ressourcenerschöpfung oder der API-Drosselung hinweisen.
Auswirkungen:Probleme mit der Steuerungsebene wirken sich in der Regel auf das gesamte Mesh aus und führen zu einer weit verbreiteten Leistungsminderung.
Symptome von Skalierungsproblemen auf der Datenebene
Erhöhte Latenz bei der Kommunikation zwischen Diensten:Anfragen an einen In-Mesh-Dienst weisen eine höhere Latenz oder Zeitüberschreitungen auf, aber die CPU- und Arbeitsspeichernutzung in den Containern des Dienstes ist nicht erhöht.
Hohe CPU- oder Speicherauslastung in Envoy-Proxys:Eine hohe CPU- oder Speicherauslastung kann darauf hindeuten, dass die Proxys die Traffic-Last nicht bewältigen können.
Lokalisierte Auswirkungen:Probleme mit der Datenebene wirken sich in der Regel auf bestimmte Dienste oder Arbeitslasten aus, je nach Traffic-Mustern und Ressourcennutzung der Envoy-Proxys.
Datenebene skalieren
Um die Datenebene zu skalieren, können Sie die folgenden Methoden ausprobieren:
- Horizontales Pod-Autoscaling (HPA) konfigurieren
- Envoy-Proxykonfiguration optimieren
- Überwachen und optimieren
Horizontales Pod-Autoscaling (HPA) für Arbeitslasten konfigurieren
Verwenden Sie horizontales Pod-Autoscaling (HPA), um Arbeitslasten basierend auf der Ressourcenauslastung dynamisch mit zusätzlichen Pods zu skalieren. Beachten Sie beim Konfigurieren von HPA Folgendes:
Mit dem Parameter
--horizontal-pod-autoscaler-sync-periodkönnen Siekube-controller-manager, um die Polling-Rate des HPA-Controllers anzupassen. Die Standard-Polling-Rate beträgt 15 Sekunden. Sie sollten sie verringern, wenn Sie mit schnelleren Traffic-Spitzen rechnen. Weitere Informationen dazu, wann HPA mit GKE verwendet werden sollte, finden Sie unter Horizontales Pod-Autoscaling.Das Standardskalierungsverhalten kann dazu führen, dass eine große Anzahl von Pods gleichzeitig bereitgestellt oder beendet wird, was zu einem Anstieg der Ressourcennutzung führen kann. Verwenden Sie Skalierungsrichtlinien, um die Rate zu begrenzen, mit der Pods bereitgestellt werden können.
Verwenden Sie EXIT_ON_ZERO_ACTIVE_CONNECTIONS, um zu vermeiden, dass Verbindungen während des Herunterskalierens getrennt werden.
Weitere Informationen zu HPA finden Sie in der Kubernetes-Dokumentation unter Horizontales Pod-Autoscaling.
Envoy-Proxykonfiguration optimieren
Zur Optimierung der Envoy-Proxy-Konfiguration sollten Sie die folgenden Empfehlungen berücksichtigen:
Ressourcenlimits
Sie können Ressourcenanforderungen und ‑limits für Envoy-Sidecars in Ihren Pod-Spezifikationen definieren. Dadurch werden Ressourcenkonflikte vermieden und eine konsistente Leistung gewährleistet.
Sie können auch Standardressourcenlimits für alle Envoy-Proxys in Ihrem Mesh mit Ressourcenanmerkungen konfigurieren.
Die optimalen Ressourcenlimits für Ihre Envoy-Proxys hängen von Faktoren wie Trafficvolumen, Komplexität der Arbeitslast und GKE-Knotenressourcen ab. Überwachen und optimieren Sie Ihr Service Mesh kontinuierlich, um eine optimale Leistung zu erzielen.
Wichtiger Hinweis:
- Dienstqualität (Quality of Service, QoS): Wenn Sie sowohl Anfragen als auch Limits festlegen, haben Ihre Envoy-Proxys eine vorhersehbare Dienstqualität.
Dienstabhängigkeiten eingrenzen
Sie können das Abhängigkeitsdiagramm Ihres Mesh reduzieren, indem Sie alle Abhängigkeiten über die Sidecar API deklarieren. Dadurch werden Größe und Komplexität der Konfiguration, die an eine bestimmte Arbeitslast gesendet wird, begrenzt. Das ist für größere Meshs von entscheidender Bedeutung.
Das folgende Beispiel zeigt den Traffic-Graphen für die Beispielanwendung „Online Boutique“.
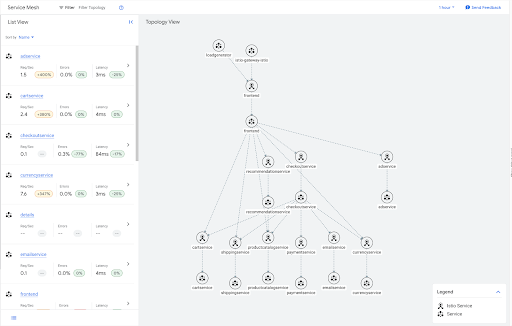
Viele dieser Dienste sind Blätter im Diagramm und benötigen daher keine Informationen zum ausgehenden Traffic für die anderen Dienste im Mesh. Sie können eine Sidecar-Ressource anwenden, um den Geltungsbereich der Sidecar-Konfiguration für diese Leaf-Dienste einzuschränken, wie im folgenden Beispiel gezeigt.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: leafservices
namespace: default
spec:
workloadSelector:
labels:
app: cartservice
app: shippingservice
app: productcatalogservice
app: paymentservice
app: emailservice
app: currencyservice
egress:
- hosts:
- "~/*"
Weitere Informationen zum Bereitstellen dieser Beispielanwendung finden Sie unter Beispielanwendung „Online Boutique“.
Ein weiterer Vorteil der Sidecar-Bereichseinschränkung ist die Reduzierung unnötiger DNS-Abfragen. Durch die Festlegung von Dienstabhängigkeiten wird sichergestellt, dass ein Envoy-Sidecar nur DNS-Abfragen für Dienste ausführt, mit denen es tatsächlich kommunizieren wird, und nicht für jeden Cluster im Service Mesh.
Bei allen groß angelegten Bereitstellungen, bei denen Probleme mit großen Konfigurationsgrößen in den Sidecars auftreten, wird die Bereichsbegrenzung von Dienstabhängigkeiten dringend für die Mesh-Skalierbarkeit empfohlen.
Überwachen und optimieren
Nachdem Sie die anfänglichen Ressourcenlimits festgelegt haben, ist es wichtig, Ihre Envoy-Proxys zu überwachen, um sicherzustellen, dass sie optimal funktionieren. Verwenden Sie GKE-Dashboards, um die CPU- und Arbeitsspeichernutzung zu überwachen und die Ressourcenlimits nach Bedarf anzupassen.
Um festzustellen, ob für einen Envoy-Proxy höhere Ressourcenlimits erforderlich sind, müssen Sie seinen Ressourcenverbrauch unter normalen und Spitzen-Traffic-Bedingungen beobachten. Achten Sie auf Folgendes:
Hohe CPU-Auslastung:Wenn die CPU-Auslastung von Envoy das Limit regelmäßig erreicht oder überschreitet, kann es sein, dass die Verarbeitung von Anfragen schwierig ist. Dies kann zu einer erhöhten Latenz oder zu verworfenen Anfragen führen. Erhöhen Sie das CPU-Limit.
In diesem Fall ist es vielleicht naheliegend, horizontal zu skalieren. Wenn der Sidecar-Proxy die Anfragen jedoch nicht so schnell wie der Anwendungscontainer verarbeiten kann, kann es am besten sein, die CPU-Limits anzupassen.
Hohe Speichernutzung:Wenn die Speichernutzung von Envoy sich dem Limit nähert oder es überschreitet, kann es sein, dass Verbindungen getrennt werden oder OOM-Fehler (Out-of-Memory) auftreten. Erhöhen Sie das Speicherlimit, um diese Probleme zu vermeiden.
Fehlerlogs:Prüfen Sie die Envoy-Logs auf Fehler im Zusammenhang mit Ressourcenerschöpfung, z. B. upstream connect error, disconnect or reset before headers oder too many open files. Diese Fehler können darauf hinweisen, dass der Proxy mehr Ressourcen benötigt. Weitere Fehler im Zusammenhang mit Skalierungsproblemen finden Sie in der Dokumentation zur Fehlerbehebung bei der Skalierung.
Leistungsmesswerte:Überwachen Sie wichtige Leistungsmesswerte wie Anfragelatenz, Fehlerraten und Durchsatz. Wenn Sie eine Leistungsverschlechterung feststellen, die mit einer hohen Ressourcennutzung zusammenhängt, müssen Sie möglicherweise die Limits erhöhen.
Wenn Sie aktiv Ressourcenlimits für Ihre Data-Plane-Proxys festlegen und überwachen, können Sie dafür sorgen, dass Ihr Service Mesh in GKE effizient skaliert wird.
Steuerungsebene skalieren
In diesem Abschnitt werden die Einstellungen beschrieben, die Sie anpassen müssen, um die Steuerungsebene zu skalieren.
Discovery-Auswahlen
„Discovery selectors“ ist ein Feld in der MeshConfig, mit dem Sie die Namespaces angeben können, die Steuerungsebenen bei der Berechnung von Konfigurationsupdates für Sidecars berücksichtigen.
Standardmäßig überwacht Cloud Service Mesh alle Namespaces im Cluster. Dies kann ein Engpass für große Cluster sein, in denen nicht alle Ressourcen beobachtet werden müssen.
Verwenden Sie discoverySelectors, um die Rechenlast auf der Steuerungsebene zu reduzieren, indem Sie die Anzahl der Kubernetes-Ressourcen (z. B. Dienste, Pods und Endpunkte) begrenzen, die beobachtet und verarbeitet werden.
Bei Verwendung der TRAFFIC_DIRECTOR-Steuerungsebene werden in Cloud Service Mesh nur Google Cloud Ressourcen wie Backend-Dienste und Netzwerkendpunktgruppen für Kubernetes-Ressourcen in Namespaces erstellt, die in discoverySelectors angegeben sind.
Weitere Informationen finden Sie in der Istio-Dokumentation unter Discovery selectors.
Resilienz aufbauen
Sie können die folgenden Einstellungen anpassen, um die Resilienz Ihres Service Mesh zu verbessern:
Ausreißererkennung
Die Ausreißererkennung überwacht Hosts in einem Upstream-Dienst und entfernt sie aus dem Load-Balancing-Pool, wenn ein bestimmter Fehlerschwellenwert erreicht wird.
- Wichtige Konfiguration:
outlierDetection: Einstellungen, die die Bereinigung von fehlerhaften Hosts aus dem Load-Balancing-Pool steuern.
- Vorteile:Es wird ein intakter Satz von Hosts im Load-Balancing-Pool aufrechterhalten.
Weitere Informationen finden Sie in der Istio-Dokumentation unter Outlier Detection.
Neuversuche
Vorübergehende Fehler werden durch automatisches Wiederholen fehlgeschlagener Anfragen behoben.
- Wichtige Konfiguration:
attempts: Anzahl der Wiederholungsversuche.perTryTimeout: Zeitlimit pro Wiederholungsversuch. Legen Sie diesen Wert kürzer als das Gesamttimeout fest. Damit wird festgelegt, wie lange Sie bei jedem einzelnen Wiederholungsversuch warten.retryBudget: Maximale Anzahl gleichzeitiger Wiederholungsversuche.
- Vorteile:Höhere Erfolgsraten für Anfragen, geringere Auswirkungen von zeitweiligen Fehlern.
Zu berücksichtigende Faktoren:
- Idempotenz:Achten Sie darauf, dass der Vorgang, der wiederholt wird, idempotent ist. Das bedeutet, dass er ohne unbeabsichtigte Nebenwirkungen wiederholt werden kann.
- Maximale Anzahl an Wiederholungen:Beschränken Sie die Anzahl der Wiederholungen (z.B. maximal 3 Wiederholungen), um Endlosschleifen zu vermeiden.
- Schutzschaltungen:Integrieren Sie Wiederholungsversuche mit Schutzschaltungen, um Wiederholungsversuche zu verhindern, wenn ein Dienst wiederholt fehlschlägt.
Weitere Informationen finden Sie in der Istio-Dokumentation unter Wiederholungen.
Zeitlimits
Verwenden Sie Zeitlimits, um die maximale Zeit für die Verarbeitung von Anfragen festzulegen.
- Wichtige Konfiguration:
timeout: Zeitüberschreitung bei Anfragen für einen bestimmten Dienst.idleTimeout: Zeit, die eine Verbindung inaktiv bleiben kann, bevor sie geschlossen wird.
- Vorteile:Verbesserte Systemreaktionsfähigkeit, Verhinderung von Ressourcenlecks, Schutz vor schädlichem Traffic.
Zu berücksichtigende Faktoren:
- Netzwerklatenz:Berücksichtigen Sie die erwartete Umlaufzeit (Round Trip Time, RTT) zwischen Diensten. Planen Sie einen Puffer für unerwartete Verzögerungen ein.
- Dienstabhängigkeitsdiagramm:Bei verketteten Anfragen muss das Zeitlimit eines aufrufenden Dienstes kürzer sein als das kumulative Zeitlimit seiner Abhängigkeiten, um kaskadierende Fehler zu vermeiden.
- Arten von Vorgängen:Lang andauernde Aufgaben erfordern möglicherweise deutlich längere Zeitüberschreitungen als das Abrufen von Daten.
- Fehlerbehebung:Bei Zeitüberschreitungen sollte eine geeignete Logik zur Fehlerbehebung ausgelöst werden (z.B. Wiederholung, Fallback, Circuit Breaker).
Weitere Informationen finden Sie in der Istio-Dokumentation unter Timeouts.
Überwachen und optimieren
Beginnen Sie mit den Standardeinstellungen für Zeitüberschreitungen, Ausreißererkennung und Wiederholungsversuche und passen Sie sie dann nach und nach an Ihre spezifischen Dienstanforderungen und beobachteten Traffic-Muster an. Sehen Sie sich beispielsweise reale Daten dazu an, wie lange Ihre Dienste in der Regel für eine Antwort benötigen. Passen Sie dann die Zeitüberschreitungen an die spezifischen Merkmale der einzelnen Dienste oder Endpunkte an.
Telemetrie
Verwenden Sie Telemetrie, um Ihr Service Mesh kontinuierlich zu überwachen und seine Konfiguration anzupassen, um Leistung und Zuverlässigkeit zu optimieren.
- Messwerte:Verwenden Sie umfassende Messwerte, insbesondere Anfragevolumen, Latenz und Fehlerraten. Einbindung in Cloud Monitoring für Visualisierung und Benachrichtigungen.
- Verteiltes Tracing:Aktivieren Sie die Integration des verteilten Tracings mit Cloud Trace, um detaillierte Informationen zu Anfrageflüssen in Ihren Diensten zu erhalten.
- Logging:Konfigurieren Sie Zugriffsprotokollierung, um detaillierte Informationen zu Anfragen und Antworten zu erfassen.
Weitere Informationen
- Weitere Informationen zu Cloud Service Mesh finden Sie in der Übersicht zu Cloud Service Mesh.
- Allgemeine SRE-Anleitungen (Site Reliability Engineering) zur Skalierbarkeit finden Sie in den Kapiteln Überlastung bewältigen und Kaskadierende Fehler beheben im Google SRE-Buch.