本主題將說明如何使用 Sensitive Data Protection 測量資料集的k-anonymity,然後使用視覺化方式呈現在 Looker Studio 中。如此一來,您也可以更充分瞭解風險,並協助評估如要將資料遮蓋或去識別化時,可能必須在實用性上做哪些取捨。
雖然本主題的重點是呈現 k-anonymity 重新識別風險分析指標,但您也可以使用相同方法,以視覺化方式呈現 l-diversity 指標。
本主題假設您已熟悉 k-anonymity 的概念,及其用於評估資料集內記錄重新識別性的實用性。此外,您也應至少稍微瞭解如何使用 Sensitive Data Protection 計算 k-anonymity,以及如何使用 Looker Studio。
簡介
去識別化技術可以協助您在處理或使用資料時,有效保護當事人的隱私權。但是,您要如何得知資料集是否做了充分的去識別化呢?還有,如何察覺去識別化作業是否造成資料損失過多,而不適合您的用途?也就是說,您可以如何比較重新識別風險與資料的實用性,進而做出資料導向的決策呢?
計算資料集的 k-anonymity 值,有助於藉由評估資料集記錄是否能重新識別,來解答上述問題。Sensitive Data Protection 內建的功能可讓您根據指定的準識別項,計算資料集的 k-anonymity 值。這可以協助您快速評估將某一資料欄或某組資料欄去識別化,將使資料集能被重新識別的機率增加還是減少。
範例資料集
以下是某個大型範例資料集的前幾行。
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
為符合本教學課程的目的,user_id 將不在此說明,因為我們重點是在準識別項上。在現實生活中,您會希望確保 user_id 經過正確遮蓋或代碼化。score 資料欄專用於這個資料集,而攻擊者不太可能會利用其他方式來得知此內容,因此您不會將此納入分析範圍。其他 age 和 title 資料欄才是您的重點,因為攻擊者可能會透過其他資料來源知悉某一個人的資料。對於資料集,您要找出以下問題的解答:
- 這兩個準識別項 (
age和title) 對去識別化資料的整體重新識別風險有何影響? - 運用去識別化轉換會如何影響這個風險?
您應確保 age 和 title 的組合不會對應到少數使用者。舉例來說,假設在資料集中只有一位使用者職稱為「程式設計師 I」且年齡是 69。攻擊者可能可以利用人口統計或其他可用資訊,交叉參照以上資訊,猜出這個人是誰,並得到分數值。如要進一步瞭解這項現象,請參閱「實體 ID 和計算 k 匿名性」一節的風險分析概念主題。
步驟 1:對資料集計算 k-anonymity
首先,將下列 JSON 傳送至 DlpJob 資源,使用 Sensitive Data Protection 對資料集計算 k-anonymity。在這個 JSON 中,您將實體 ID 設為 user_id 欄,並將 age 和 title 欄識別為兩個準 ID。此外,也要指示 Sensitive Data Protection 將結果儲存到新的 BigQuery 表格中。
JSON 輸入:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}當 k-anonymity 工作處理完畢後,Sensitive Data Protection 就會將工作結果傳送到名為 dlp-demo-2.dlp_testing.test_results 的 BigQuery 表格。
步驟 2:將結果連結至 Looker Studio
接下來,您要將步驟 1 所產生的 BigQuery 表格連接到 Looker Studio 中的新報表。
開啟 Looker Studio。
依序點選「建立」 >「報表」。
在「將資料新增至報表」窗格的「連結至資料」下方,按一下「BigQuery」。您可能需要授權 Looker Studio 存取 BigQuery 資料表。
在欄選擇器中,選取「我的專案」。然後選擇專案、資料集和資料表。完成後,按一下「新增」。如果看到「您即將在這份報表中加入資料」的通知,請按一下「加入報表」。
k-anonymity 掃描結果就會加到新的 Looker Studio 報表中。在下一個步驟中,您將會建立圖表。
步驟 3:建立圖表
如要插入及設定圖表,請按照下列步驟操作:
- 在 Looker Studio 中,如果出現值表格,請選取並按下 Delete 鍵移除。
- 在「插入」選單中,按一下「組合圖」。
- 在畫布上按一下,然後在您要顯示圖表的地方畫一個矩形。
接著,在「資料」分頁下方設定圖表資料,讓圖表顯示改變值區的大小和值範圍會產生的影響:
- 指向下列標題下方的每個欄位,然後按一下 X,清除這些欄位,如下所示:
- 日期範圍維度
- 尺寸
- 指標
- 排序
- 清除所有欄位後,將「upper_endpoint」欄位從「Available fields」(可用欄位) 欄拖曳到「Dimension」(維度) 標題。
- 將「upper_endpoint」欄位拖曳到「Sort」(排序) 標題,然後選取「Ascending」(遞增)。
- 將「bucket_size」和「bucket_value_count」欄位拖曳到「指標」標題。
- 指向「bucket_size」bucket_size指標左側的圖示,編輯圖示 便會出現。
按一下「編輯」圖示,然後執行下列操作:
- 在「Name」(名稱) 欄位中輸入
Unique row loss。 - 在「Type」(類型) 下方,選擇「Percent」(百分比)。
- 在「比較計算」下方,選擇「總計百分比」。
- 在「累計計算」下方,選擇「累計加總」。
- 在「Name」(名稱) 欄位中輸入
- 對「bucket_value_count」指標重複執行上一個步驟,但在「Name」(名稱) 欄位中輸入
Unique quasi-identifier combination loss。
完成後,資料欄應顯示如下:
最後,設定圖表,針對兩個指標顯示折線圖:
- 在視窗右側窗格中,按一下「樣式」分頁標籤。
- 針對數列 #1 和數列 #2,選擇「線條」。
- 如要查看最後的圖表,請按一下視窗右上角的「查看」按鈕。
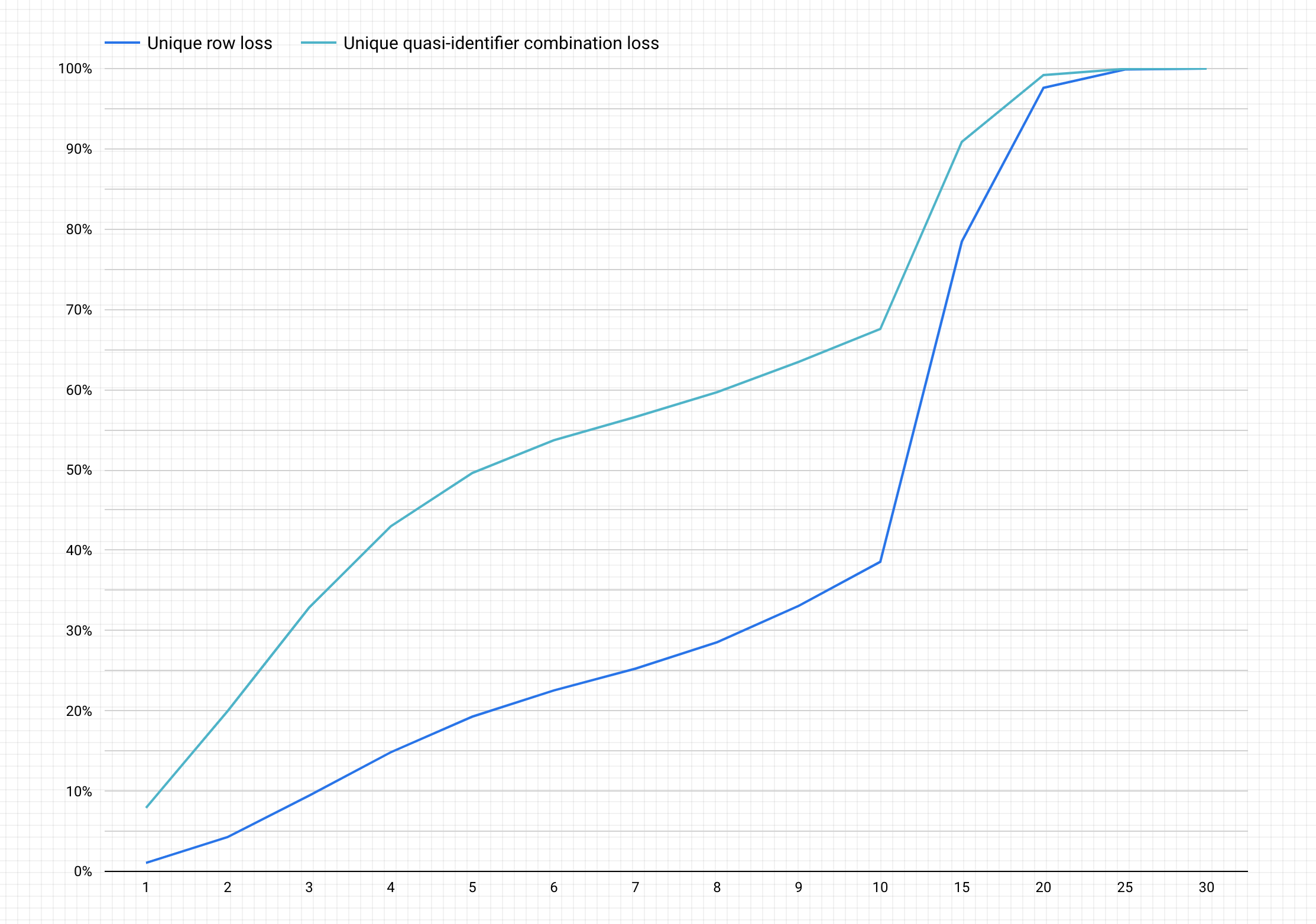
完成上述步驟後,圖表範例如下。
解釋圖表
在產生的圖表上,y 軸會繪製出為達到 x 軸上的 k-anonymity 值,可能損失的資料百分比 (包括不重複資料列和不重複準識別項組合)。
k-anonymity 值越高,表示重新識別的風險越低。不過,如要達到更高的 k-anonymity 值,您需要移除更高百分比的總資料列和更高比例的準識別項組合,這可能會降低資料的實用性。
幸好捨棄資料不是唯一選擇,您還可以採取其他做法來降低重新識別的風險。其他去識別化技術可以在損失和實用性之間取得較好的平衡。舉例來說,如要解決 k-anonymity 值偏高和這個資料集相關的資料損失問題,您可以試著將年齡或職稱進行特徵分塊,藉此降低年齡/職稱組合的獨特性。比方說,您可以嘗試將年齡分為 20-25、25-30、30-35 等範圍的特徵分塊。如要進一步瞭解如何操作,請參閱「一般化與特徵分塊」和「將文字內容中的機密資料去識別化」等文。