このトピックでは、機密データの保護を使用してデータセットの k-匿名性を測定し、Looker Studio で可視化する方法を示します。そうすることで、リスクをより深く理解し、データの秘匿化や匿名化を行う場合に有用性のトレードオフを評価するのに役立ちます。
このトピックの焦点は、k-匿名性の再識別リスク分析指標の可視化ですが、同じ方法を使用して l-多様性指標を可視化することもできます。
このトピックでは、k-匿名性のコンセプトと、データセット内のレコードの再識別可能性を評価する上での有用性について熟知していることを前提としています。また、機密データの保護を使用して k-匿名性を計算する方法と、Looker Studio を使用する方法にいくらか慣れておくと役立ちます。
はじめに
データの処理や使用時に主体のプライバシーを保護するために、匿名化手法が役立つことがあります。ですが、データセットが十分に匿名化されていることを把握するためにはどうすればいいでしょうか。また、匿名化の結果生じたデータ損失が大きすぎないかどうかを把握するためにはどうすればいいでしょか。つまり、データドリブンの意思決定に役立てるために、再識別リスクとデータの有用性をどのように比較できるでしょうか。
データセットの k-匿名性の値の計算では、データセットのレコードの再識別可能性が評価されるため、こうした質問に答えるのに役立ちます。機密データの保護には、指定した準識別子に基づいてデータセットの k-匿名性の値を計算する組み込み機能が含まれています。これにより、特定の列または列の組み合わせを匿名化することで、再識別される可能性が高いデータセットが生成されるかどうかを迅速に評価できます。
データセットの例
以下は、大きなデータセットの例の最初の数行です。
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
このチュートリアルでは、準識別子に焦点を当てているため、user_id については説明しません。現実のシナリオでは、user_id が適切に秘匿化またはトークン化されていることを確認する必要があります。score はこのデータセット専用であり、攻撃者が他の方法で学習する可能性は低いため、分析には含めません。したがって、残りの age 列と title 列に焦点を当てることになります。攻撃者はこれらの列を使用して、他のデータソース経由で個人について知る可能性があります。データセットについて回答しようとしている質問は次のとおりです。
ageとtitleの 2 つの準識別子は、匿名化されたデータの全体的な再識別リスクにどのような影響を与えるか。- 匿名化変換の適用は、このリスクにどのような影響を与えるか。
age と title の組み合わせが少数のユーザーにマッピングされないようにする必要があります。たとえば、肩書が Programmer I で 69 歳のユーザーがデータセットに 1 人しかいないとします。攻撃者は、その情報を人口統計または他の利用可能な情報と相互参照し、その人物を特定してスコアの値を知ることができる可能性があります。この現象の詳細については、リスク分析のコンセプト トピックのエンティティ ID と k-匿名性の計算セクションをご覧ください。
ステップ 1: データセットに対する k-匿名性を計算する
まず、次の JSON を DlpJob リソースに送信して、データセットに対する k-匿名性を計算します。この JSON では、エンティティ ID を user_id 列に設定し、2 つの準識別子を age 列と title 列の両方として識別します。また、結果を新しい BigQuery テーブルに保存するように機密データの保護に指示しています。
JSON 入力:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}k-匿名性ジョブが完了すると、機密データの保護はジョブ結果を dlp-demo-2.dlp_testing.test_results という名前の BigQuery テーブルに送信します。
ステップ 2: 結果を Looker Studio に接続する
次に、ステップ 1 で作成した BigQuery テーブルを Google Looker Studio の新しいレポートに接続します。
Looker Studio を開きます。
[作成] > [レポート] をクリックします。
[データのレポートへの追加] ペインの [データに接続する] で、[BigQuery] をクリックします。場合によっては、Looker Studio に BigQuery テーブルへのアクセスを許可する必要があります。
列選択ツールで、[マイ プロジェクト] を選択します。次に、プロジェクト、データセット、テーブルを選択します。選択が完了したら、[追加] をクリックします。[このレポートにデータを追加しようとしています] という通知が表示されたら、[レポートに追加] をクリックします。
これで、k-匿名性スキャン結果が新しいLooker Studio レポートに追加されました。次のステップでは、グラフを作成します。
ステップ 3: グラフを作成する
グラフを挿入して構成するには、次のようにします。
- Looker Studio に値の表が表示されたら、それを選択し、Delete キーを押して削除します。
- [挿入] メニューで、[複合グラフ] をクリックします。
- グラフを表示するキャンバスをクリックして長方形を描画します。
次に、バケットのサイズと値の範囲を変更する効果がグラフに示されるように、[データ] タブでグラフデータを構成します。
- 次のように、各フィールドにカーソルを合わせ、 X をクリックして、次の見出しにあるフィールドをクリアします。

- 期間のディメンション
- ディメンション
- 指標
- 並べ替え
- すべてのフィールドをクリアして、[upper_endpoint] フィールドを [Available fields] 列から [ディメンション] 見出しにドラッグします。
- [upper_endpoint] フィールドを [並べ替え] 見出しにドラッグし、[昇順] を選択します。
- [bucket_size] フィールドと [bucket_value_count] フィールドの両方を [指標] 見出しにドラッグします。
- bucket_size 指標の左にあるアイコンを指定すると、編集アイコンが表示されます。編集アイコンをクリックして、次の操作を行います。
- [名前] フィールドに「
Unique row loss」と入力します。 - [タイプ] で [割合(%)] を選択します。
- [Comparison calculation] で [全体に対する割合] を選択します。
- [関数] で [実行中の合計] を選択します。
- [名前] フィールドに「
- bucket_value_count 指標について、前の手順を繰り返します。[名前] フィールドに
Unique quasi-identifier combination lossと入力します。
完了すると、列は次のように表示されます。
最後に、両方の指標の折れ線グラフを表示するようにグラフを構成します。
- ウィンドウの右側にあるペインの [スタイル] タブをクリックします。
- 系列 #1 と系列 #2 の両方で、[折れ線] を選択します。
- 最後のグラフを単独で表示するには、ウィンドウの右上隅にある [ビュー] ボタンをクリックします。
以下は、前の手順の完了後のグラフの例です。
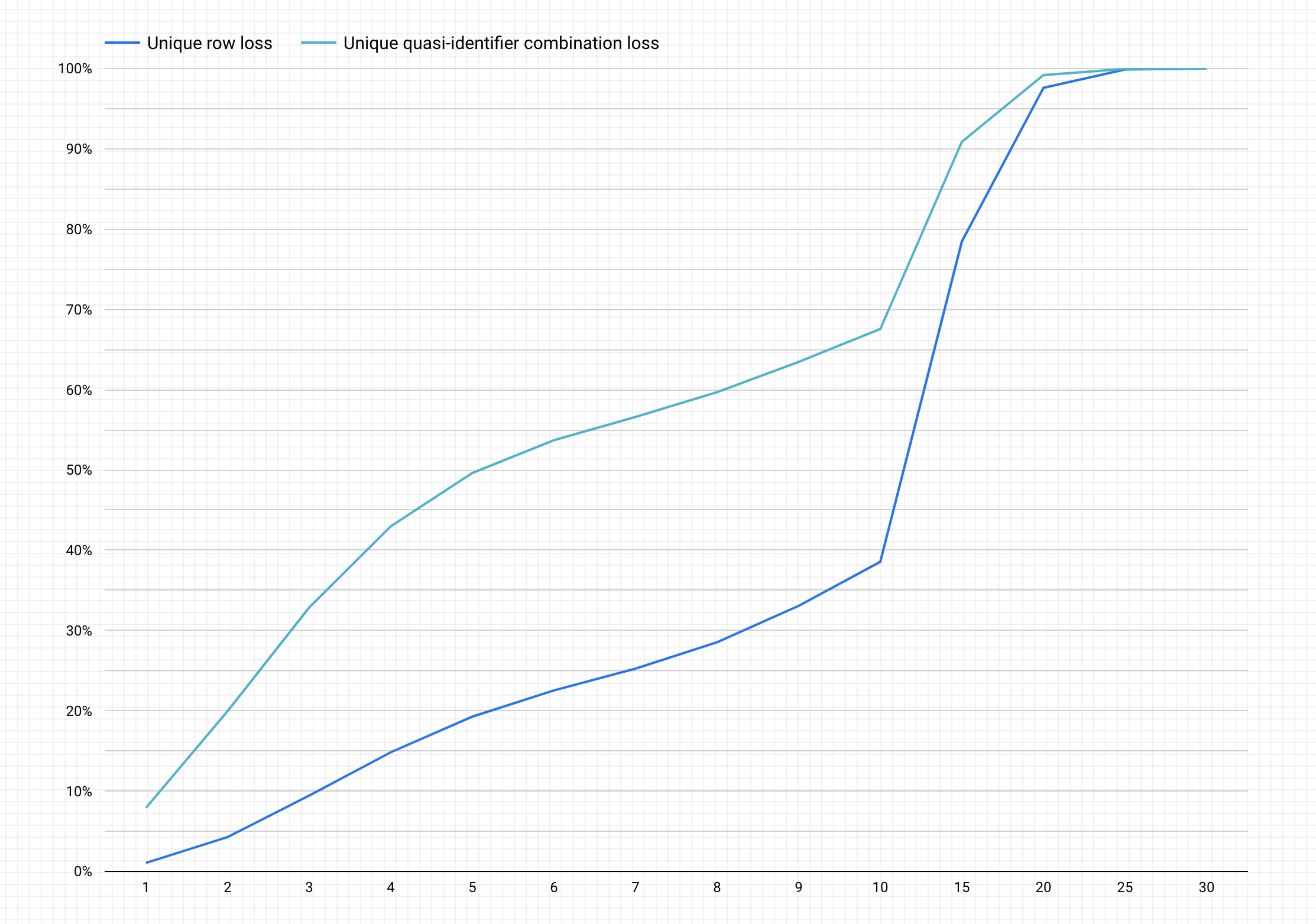
グラフの解釈
生成されたチャートは、特定の行と準識別子の組み合わせでデータが失われる可能性(%)を y 軸とし、k-匿名性の値を x 軸としてプロットしたグラフです。
k-匿名性の値が高いほど、再識別リスクは低くなります。ただし、より高い k-匿名性の値を実現するためには、行や一意の準識別子の組み合わせをより多く削除する必要があり、これによりデータの有用性が低下する可能性があります。
幸い、データを削除することだけが、再識別リスク軽減の選択肢ではありません。他の匿名化手法を使用すると、損失と有用性のより良いバランスをとることができます。たとえば、より高い k-匿名性の値とこのデータセットに関連する種類のデータ損失に対処するには、年齢と役職の組み合わせの一意性を削減するために、年齢や役職をバケット化できます。たとえば、20〜25、25〜30、30〜35 などの範囲で年齢をバケット化してみることができます。実施方法の詳細については、一般化とバケット化とテキスト コンテンツ内の機密データの匿名化をご覧ください。