一般化とは、他とは明らかに区別できる値を受け取って、それをより一般的な、特徴の少ない値に抽象化するプロセスです。一般化は、データの有用性を維持しながらも、データの識別可能性を低くするための試みです。
データのタイプに応じて、さまざまなレベルの一般化を適用できます。どの程度の一般化が必要となるかを計測するには、データセットや実世界の人口を対象として、機密データの保護のリスク分析手法にあるような手法を使用できます。
よく使われる一般化手法の 1 つとして、バケット化が 機密データの保護でサポートされています。バケット化では、攻撃者が機密情報を識別情報に関連付けるリスクを最小限に抑えられるよう、レコードを複数の小さなバケットにグループ化します。こうすると、意味と有用性を維持できると同時に、使用頻度が非常に低い個別の値を曖昧化できます。
バケット化のシナリオ 1
数値のバケット化のシナリオとして、あるデータベースにユーザーの満足度スコア(0~100 の範囲)が格納されているとします。このデータベースは、以下のような内容です。
| user_id | score |
|---|---|
| 1 | 100 |
| 2 | 100 |
| 3 | 92 |
| … | … |
このデータをスキャンすると、値の中には、ほとんどユーザーに使用されないものがあることがわかります。実際、いくつかのスコアは 1 人のユーザーにのみマッピングされます。たとえば、ユーザーの大半は値 0、25、50、75、または 100 を選択していますが、95 を選んだユーザーは 5 人、92 を選んだユーザーは 1 人だけです。未加工データを保持する代わりに、これらの値を複数グループに一般化して、ごくわずかな件数しか含まないグループの存在を排除できます。データの使用方法によっては、このようにデータを一般化することで、個人情報の再特定化を防ぐために役立ちます。
このような外れ値データの行を削除するという方法もありますが、バケット化を使用して、データの有用性を維持するよう試みることもできます。この例では、以下のようにすべての値をバケット化します。
- 0〜25: "Low"
- 26〜75: "Medium"
- 76〜100: "High"
機密データの保護におけるバケット化は、匿名化に使用できる多数のプリミティブ変換のうちの 1 つです。以下の JSON 構成は、このバケット化シナリオを DLP API で実装する方法を示しています。この JSON を、content.deidentify メソッドに対するリクエストに含めることができます。
C#
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Go
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Java
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Node.js
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
PHP
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Python
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
REST
...
{
"primitiveTransformation":
{
"bucketingConfig":
{
"buckets":
[
{
"min":
{
"integerValue": "0"
},
"max":
{
"integerValue": "25"
},
"replacementValue":
{
"stringValue": "Low"
}
},
{
"min":
{
"integerValue": "26"
},
"max":
{
"integerValue": "75"
},
"replacementValue":
{
"stringValue": "Medium"
}
},
{
"min":
{
"integerValue": "76"
},
"max":
{
"integerValue": "100"
},
"replacementValue":
{
"stringValue": "High"
}
}
]
}
}
}
...
バケット化のシナリオ 2
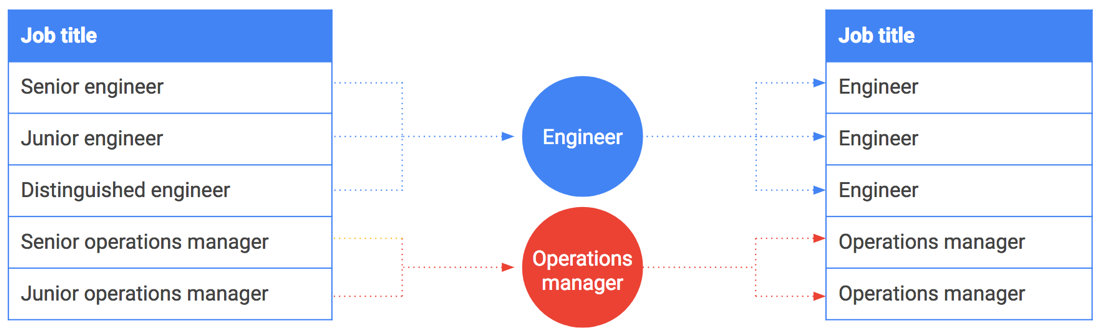
文字列や列挙値にも、バケット化を適用することができます。一例として、給与データを共有し、データに役職を含める必要があるとします。ただし、CEO や上級エンジニアなどの一部の役職は、1 人または少数の個人に結び付けられる可能性があります。このような役職から、その肩書を持つ従業員を簡単に識別できます。
バケット化は、この例でも役立ちます。正確な役職を含める代わりに、役職を一般化してバケット化します。たとえば、「シニア エンジニア」、「ジュニア エンジニア」、「上級エンジニア」を一般化すると、単なる「エンジニア」にバケット化されます。以下の表に、特定の役職を役職ファミリーにバケット化する方法を示します。
その他のシナリオ
以上の例では、構造化データに変換を適用しました。さらに、非構造化の例でバケット化を使用することもできます(ただし定義済みまたはカスタム infoType で値を分類できる場合)。以下に、いくつかのシナリオの例を挙げます。
- 日付を分類して、年の範囲ごとにバケット化する
- 名前を分類して、最初の文字(A~M、N~Z)に基づくグループごとにバケット化する
リソース
一般化とバケット化について詳しくは、テキスト コンテンツ内の機密データの匿名化をご覧ください。
API ドキュメントについては、以下をご覧ください。
projects.content.deidentifyメソッドBucketingConfig変換(カスタム範囲に基づく値のバケット化)FixedSizeBucketingConfig変換(固定サイズ範囲に基づく値のバケット化)