このページでは、機密データの検出サービスについて説明します。このサービスにより、機密データとリスクの高いデータが組織内のどこに保管されているかを特定できます。
概要
検出サービスを使用すると、機密データとリスクの高いデータが存在する場所を識別して、組織全体のデータを保護できます。検出スキャン構成を作成すると、Sensitive Data Protection によってリソースがスキャンされ、プロファイリングの対象範囲内のデータが特定されます。次に、データのプロファイルを生成します。検出構成がアクティブである限り、Sensitive Data Protection は、追加および変更するデータを自動的にプロファイリングします。組織全体、個々のフォルダ、個別のプロジェクトでデータ プロファイルを生成できます。
各データ プロファイルは、サポートされているリソースをスキャンして検出サービスが収集する分析情報とメタデータのセットです。分析情報には、予測された infoType と、データの計算されたデータリスクと機密性レベルが含まれます。これらの分析情報を使用し、データの保護、共有、使用について、情報に基づく意思決定を行います。
データ プロファイルは、さまざまな詳細レベルで生成されます。たとえば、BigQuery データをプロファイリングすると、プロジェクト、テーブル、列レベルでプロファイルが生成されます。
次の図は、列レベルのデータ プロファイルのリストを示しています。画像をクリックすると拡大します。

各データ プロファイルに含まれる分析情報とメタデータの一覧については、指標のリファレンスをご覧ください。
Google Cloud リソース階層の詳細については、リソース階層をご覧ください。
データ プロファイルの生成
データ プロファイルの生成を開始するには、検出スキャン構成(データプロファイル構成とも呼ばれます)を作成します。このスキャン構成では、検出オペレーションのスコープとプロファイリングするデータの種類を設定します。スキャン構成でフィルタを設定して、プロファイリングまたはスキップするデータのサブセットを指定できます。プロファイリング スケジュールを設定することもできます。
また、スキャン構成を作成する際には、使用する検査テンプレートも設定します。検査テンプレートには、Sensitive Data Protection でスキャンする必要がある機密データの種類(infoType とも呼ばれます)を指定します。
Sensitive Data Protection は、データ プロファイルを作成する際、スキャンの構成と検査テンプレートに基づいてデータを分析します。
機密データの保護では、データ プロファイル生成の頻度で説明されているようにデータが再プロファイリングされます。スケジュールの作成によって、スキャン構成でプロファイリング頻度をカスタマイズできます。検出サービスでデータを強制的に再プロファイリングするには、再プロファイリング オペレーションを強制するをご覧ください。
検出タイプ
このセクションでは、実行できる検出オペレーションの種類と、サポートされているデータリソースについて説明します。
BigQuery と BigLake の検出
BigQuery データをプロファイリングすると、プロジェクト、テーブル、列のレベルでデータ プロファイルが生成されます。BigQuery テーブルをプロファイリングした後、詳細な検査を実行して検出結果をさらに調査できます。
機密データの保護は、BigQuery Storage Read API によってサポートされている次のようなテーブルをプロファイリングします。
- 標準の BigQuery テーブル
- Table Snapshots
- Cloud Storage に保存されている BigLake テーブル
以下はサポートされていません。
- BigQuery Omni テーブル。
- 個々の行のシリアル化されたデータサイズが、BigQuery Storage Read API でサポートされているシリアル化されたデータの最大サイズ(128 MB)を超えているテーブル。
- BigLake 以外の外部テーブル(Google スプレッドシートなど)。
BigQuery データのプロファイリング方法については、以下をご覧ください。
BigQuery の詳細については、BigQuery のドキュメントをご覧ください。
Cloud SQL の検出
Cloud SQL データをプロファイリングすると、プロジェクト、テーブル、列のレベルでデータ プロファイルが生成されます。検出を開始する前に、プロファイリングする各 Cloud SQL インスタンスの接続情報を指定する必要があります。
Cloud SQL データのプロファイリング方法については、以下をご覧ください。
Cloud SQL の詳細については、Cloud SQL のドキュメントをご覧ください。
Cloud Storage の検出
Cloud Storage データをプロファイリングすると、データ プロファイルがバケットレベルで生成されます。機密データの保護は、検出されたファイルをファイルクラスタにグループ化し、各クラスタの概要を提供します。
Cloud Storage データをプロファイリングする方法については、以下をご覧ください。
Cloud Storage の詳細については、Cloud Storage のドキュメントをご覧ください。
Vertex AI の Discovery
Vertex AI データセットをプロファイリングすると、トレーニング データが保存されている場所(Cloud Storage または BigQuery)に応じて、ファイル ストア データ プロファイルまたはテーブル データ プロファイルが生成されます。
詳しくは以下をご覧ください。
Vertex AI の詳細については、Vertex AI のドキュメントをご覧ください。
Amazon S3 の検出
S3 データをプロファイリングすると、データ プロファイルはバケットレベルで生成されます。機密データの保護は、検出されたファイルをファイルクラスタにグループ化し、各クラスタの概要を提供します。
詳細については、Amazon S3 データの機密データの検出をご覧ください。
Cloud Run の環境変数
検出サービスは、Cloud Run functions と Cloud Run サービスのリビジョン環境変数にシークレットが存在することを検出し、検出結果を Security Command Center に送信できます。データ プロファイルは生成されません。
詳細については、環境変数のシークレットを Security Command Center に報告するをご覧ください。
データ プロファイルの構成と表示に必要なロール
以下のセクションでは、必要なユーザーロールを目的別に分類して説明します。組織の設定方法に応じて、異なるユーザーに異なるタスクを実行させることができます。たとえば、データ プロファイルを構成しているユーザーと、定期的にモニタリングしているユーザーは異なる場合があります。
組織レベルまたはフォルダレベルでデータ プロファイルを操作するために必要なロール
これらのロールを使用すると、組織レベルまたはフォルダレベルでデータ プロファイルを構成および表示できます。
これらのロールが組織レベルの適切なユーザーに付与されていることを確認してください。または、 Google Cloud 管理者は、関連する権限のみを持つカスタムロールを作成できます。
| 目的 | 事前定義ロール | 関連する権限 |
|---|---|---|
| 検出スキャン構成を作成してデータ プロファイルを表示する | DLP 管理者(roles/dlp.admin)
|
|
| サービス エージェント コンテナとして使用されるプロジェクトを作成する1 | プロジェクト作成者(roles/resourcemanager.projectCreator) |
|
| 検出へのアクセス権を付与する2 | 次のいずれかになります。
|
|
| データ プロファイルの表示(読み取り専用) | DLP データ プロファイル読み取り(roles/dlp.dataProfilesReader) |
|
DLP 読み取り(roles/dlp.reader) |
|
1 プロジェクト作成者(roles/resourcemanager.projectCreator)のロールが付与されていなくても、スキャン構成を作成できますが、使用するサービス エージェント コンテナは既存のプロジェクトにする必要があります。
2 組織管理者(roles/resourcemanager.organizationAdmin)またはセキュリティ管理者(roles/iam.securityAdmin)のロールを付与されていなくても、スキャン構成を作成できます。スキャン構成を作成した後、これらのロールのいずれかを持つ組織内のユーザーがサービス エージェントに検出アクセス権を付与する必要があります。
プロジェクト レベルでデータ プロファイルを操作するために必要なロール
これらのロールを使用すると、プロジェクト レベルでデータ プロファイルを構成、表示できます。
これらのロールがプロジェクト レベルの適切なユーザーに付与されていることを確認してください。または、 Google Cloud 管理者は、関連する権限のみを持つカスタムロールを作成できます。
| 目的 | 事前定義ロール | 関連する権限 |
|---|---|---|
| データ プロファイルの構成と表示 | DLP 管理者(roles/dlp.admin)
|
|
| データ プロファイルの表示(読み取り専用) | DLP データ プロファイル読み取り(roles/dlp.dataProfilesReader) |
|
DLP 読み取り(roles/dlp.reader) |
|
検出スキャンの構成
検出スキャン構成(検出構成またはスキャン構成とも呼ばれます)では、Sensitive Data Protection でデータをプロファイリングする方法が指定されます。設定には次の項目が含まれています。
- 検出オペレーションのスコープ(組織、フォルダ、プロジェクト)
- プロファイリングするリソースのタイプ
- 使用する検査テンプレート
- スキャン頻度
- 検出に含めるか除外するかを指定できるデータのサブセット
- 検出後に機密データの保護で行うアクション(プロファイルを公開する Google Cloud サービスなど)
- 検出オペレーションに使用するサービス エージェント
検出スキャン構成を作成する方法については、次のページをご覧ください。
BigQuery データの検出
Cloud SQL データの検出
Cloud Storage データの検出
Vertex AI データの検出
Cloud Run 環境変数のシークレットを Security Command Center に報告する(プロファイルは生成されない)
スキャン構成のスコープ
スキャン構成は次のレベルで作成できます。
- 組織
- フォルダ
- プロジェクト
- 単一のデータリソース
組織レベルとフォルダレベルで、2 つ以上のアクティブなスキャン構成で同じプロジェクトがスコープにある場合、そのプロジェクトのプロファイルを生成できるスキャン構成は機密データの保護によって決定されます。詳細については、このページのスキャン構成のオーバーライドをご覧ください。
プロジェクト レベルのスキャン構成では、常にターゲット プロジェクトをプロファイリングでき、親フォルダや組織のレベルで他の構成と競合することはありません。
単一リソースのスキャン構成は、単一のデータリソースでのプロファイリングの探索とテストを支援することを目的としています。
スキャン構成の場所
スキャン構成を初めて作成するときに、機密データの保護がそれを保存する場所を指定します。それ以降に作成するスキャン構成は、すべて、同じリージョンに保存されます。
たとえば、フォルダ A のスキャン構成を作成して us-west1 リージョンに保存すると、後で他のリソースに対して作成するスキャン構成もそのリージョンに保存されます。
プロファイリングするデータのメタデータはスキャン構成と同じリージョンにコピーされますが、データ自体は移動またはコピーされません。詳細については、データ所在地に関する検討事項をご覧ください。
検査テンプレート
検査テンプレートは、データをスキャンする際に機密データの保護が探す情報の種類(または infoType)を指定します。テンプレートでは、組み込み infoType とオプションのカスタム infoType を組み合わせて使用します。
また、確度レベルを指定して、機密データの保護が一致とみなす対象を絞り込むこともできます。ルールセットを追加して、望ましくない結果を除外すること、別の検出結果を含めることが可能です。
デフォルトでは、スキャンの構成で使用されている検査テンプレートに変更を加えると、その変更は将来のスキャンにのみ適用されます。このアクションで、データの再プロファイリング オペレーションが発生することはありません。
検査テンプレートの変更によって影響を受けるデータの再プロファイリング オペレーションをトリガーする場合は、スキャン構成でスケジュールを追加または更新し、検査テンプレートが変更されたときにデータを再プロファイリングするオプションをオンにします。詳細については、データ プロファイル生成の頻度をご覧ください。
プロファイリングするデータがある各リージョンに検査テンプレートが必要です。複数のリージョンで 1 つのテンプレートを使用する場合は、global リージョンに保存されているテンプレートを使用します。組織のポリシーで global リージョンに検査テンプレートを作成できない場合は、リージョンごとに専用の検査テンプレートを設定する必要があります。詳細については、データ所在地に関する検討事項をご覧ください。
検査テンプレートは、機密データの保護プラットフォームの中核的なコンポーネントです。データ プロファイルは、すべての機密データの保護サービスで使用できるものと同じ検査テンプレートを使用します。検査テンプレートの詳細については、テンプレートをご覧ください。
サービス エージェント コンテナとサービス エージェント
組織またはフォルダのスキャン構成を作成する際は、機密データの保護ではサービス エージェント コンテナを指定する必要があります。サービス エージェント コンテナは、組織レベルとフォルダレベルのプロファイリング オペレーションに関連する請求を追跡するために機密データの保護が使用するプロジェクトです。 Google Cloud
サービス エージェント コンテナには、サービス エージェントが含まれています。これは、機密データの保護がユーザーの代わりにデータをプロファイリングするために使用します。サービス エージェントは、機密データの保護や他の API で認証を行うために必要とされます。サービス エージェントには、データへのアクセスとプロファイリングに必要なすべての権限が不可欠です。サービス エージェントの ID は次の形式です。
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
ここでは、PROJECT_NUMBER はサービス エージェント コンテナの数値識別子です。
サービス エージェント コンテナを設定するときに、既存のプロジェクトを選択できます。選択したプロジェクトにサービス エージェントが含まれている場合、機密データの保護はそのサービス エージェントに対して必要な IAM 権限を付与します。プロジェクトにサービス エージェントがない場合、機密データの保護は 1 つ作成し、それにデータ プロファイリングの権限を自動的に付与します。
または、機密データの保護にサービス エージェント コンテナとサービス エージェントを自動的に作成させることもできます。機密データの保護によって、データ プロファイリングの権限がサービス エージェントに自動的に付与されます。
両方の場合で、機密データの保護がサービス エージェントへのデータ プロファイリングのアクセス権の付与に失敗すると、スキャン構成の詳細を表示する際に、エラーが表示されます。
プロジェクト レベルのスキャン構成の場合は、サービス エージェント コンテナは必要ありません。プロファイリングするプロジェクトが、サービス エージェント コンテナの目的を達成します。プロファイリング オペレーションを実行するには、機密データの保護はそのプロジェクト固有のサービス エージェントを使用します。
組織レベルまたはフォルダレベルでのデータ プロファイリングへのアクセス
組織レベルまたはフォルダレベルで、プロファイリングを構成すると、機密データの保護はデータ プロファイリング・アクセスをサービス エージェントに自動的に付与しようとします。ただし、IAM ロールを付与する権限がない場合、機密データの保護はユーザーの代わりにこのアクションを行うことはできません。 Google Cloud 管理者など、組織でこれらの権限を持つユーザーは、サービス エージェントにデータ プロファイリングへのアクセス権を付与する必要があります。
データ プロファイル生成の頻度
特定のリソースの検出スキャン構成を作成した後、Sensitive Data Protection によって最初のスキャンが実施され、スキャン構成の範囲内でデータがプロファイリングされます。
初回スキャン後、Sensitive Data Protection はプロファイリングされたリソースを継続的にモニタリングします。リソースに追加されたデータは、追加直後に自動的にプロファイリングされます。
デフォルトの再プロファイリング頻度
デフォルトの再プロファイリング頻度は、スキャン構成の検出タイプによって異なります。
- BigQuery プロファイリング: テーブルごとに 30 日間待機し、スキーマ、テーブル行、検査テンプレートに変更がある場合はテーブルを再プロファイリングします。
- Cloud SQL プロファイリング: テーブルごとに 30 日間待機し、スキーマまたは検査テンプレートに変更がある場合はテーブルを再プロファイリングします。
- Vertex AI プロファイリング: データセットごとに 30 日間待機し、検査テンプレートに変更がある場合はデータセットを再プロファイリングします。
ファイル ストアのプロファイリング: Google Cloud または他のクラウド内のファイル ストアごとに 30 日間待機し、検査テンプレートに変更がある場合はファイル ストアを再プロファイリングします。
Sensitive Data Protection では、ファイル ストレージ バケットまたはコンテナをファイルストアという用語で参照します。
再プロファイリングの頻度のカスタマイズ
スキャン構成では、データの異なるサブセットに 1 つ以上のスケジュールを作成して、再プロファイリングの頻度をカスタマイズできます。
次の頻度でプロファイルの再作成を行うことができます。
- 再プロファイリングしない: 最初のプロファイルが生成された後、再プロファイリングしません。
- 毎日再プロファイリングする: 24 時間待ってから再プロファイリングします。
- 毎週再プロファイリングする: 7 日間待ってから再プロファイリングします。
- 毎月再プロファイリングする: 30 日間待ってから再プロファイリングします。
スケジュールに基づくプロファイルの再作成
スキャン構成では、データが変更されたかどうかにかかわらず、データのサブセットを定期的に再プロファイリングするかどうかを指定できます。設定する頻度には、プロファイリング オペレーションの間に経過する時間の長さを指定します。たとえば、頻度を週に 1 回に設定した場合、Sensitive Data Protection は、前回プロファイリングされた日から 7 日後にデータリソースをプロファイリングします。
更新時の再プロファイリング
スキャン構成で、再プロファイリング オペレーションをトリガーできるイベントを指定できます。このようなイベントの例として、検査テンプレートの更新などがあります。
これらのイベントを選択すると、設定したスケジュールで、Sensitive Data Protection がデータを再プロファイリングする前に更新が蓄積されるのを待機する最長時間が指定されます。指定した期間内に、スキーマの変更や検査テンプレートの変更などの該当する変更がない場合、データは再プロファイリングされません。次に該当する変更が発生すると、影響を受けるデータは次回の機会で再プロファイリングされます。これは、さまざまな要因(使用可能なマシン容量や購入したサブスクリプション ユニットなど)によって決まります。その後、Sensitive Data Protection は、設定されたスケジュールに従って更新が再び蓄積されるのを待機し始めます。
たとえば、スキャン構成でスキーマ変更時に毎月再プロファイリングするように設定されているとします。データ プロファイルは 0 日目に最初に作成されました。30 日までにスキーマが変更されていないため、データは再プロファイリングされません。35 日目に最初のスキーマ変更が行われます。Sensitive Data Protection は、更新されたデータを次の機会に再プロファイリングします。その後、スキーマの更新が蓄積されるのを 30 日間待ってから、更新されたデータを再プロファイリングします。
再プロファイリングの開始から、オペレーションが完了するまでに最大 24 時間かかる場合があります。遅延が 24 時間を超え、サブスクリプション料金モードの場合は、その月の残りの容量があるかどうかを確認します。
シナリオの例については、データ プロファイリングの料金の例をご覧ください。
検出サービスでデータを強制的に再プロファイリングするには、再プロファイリング オペレーションを強制するをご覧ください。
パフォーマンスのプロファイリング
データのプロファイルにかかる時間は、以下を含む、いくつかの要因によって異なります。
- プロファイリングされるデータリソースの数
- データリソースのサイズ
- テーブルの場合、列数
- テーブルの場合、列のデータ型
したがって、過去の検査またはプロファイリングのタスクにおける機密データの保護のパフォーマンスは、将来のプロファイリング タスクでのパフォーマンスを示すものではありません。
データ プロファイルの保持
機密データの保護は、データ プロファイルの最新バージョンを 13 か月間保持します。Sensitive Data Protection がデータリソースを再プロファイリングすると、そのデータリソースの既存のプロファイルが新しいプロファイルに置き換えられます。
次のシナリオの例では、BigQuery のデフォルトのプロファイリング頻度が有効になっていることを前提としています。
1 月 1 日に、機密データの保護がテーブル A のプロファイリングをします。テーブル A は 1 年以上変更されないため、再プロファイリングされません。この場合、機密データの保護は、テーブル A のデータ プロファイルを 13 か月間保持してから削除します。
1 月 1 日に、機密データの保護がテーブル A のプロファイリングをします。その月内に、組織内の誰かがそのテーブルのスキーマを更新します。この変更により、翌月、機密データの保護はテーブル A を自動的に再プロファイリングします。新しく生成されたデータ プロファイルは、1 月に作成されたデータ プロファイルを上書きします。
データのプロファイリングに対する Sensitive Data Protection の課金方法については、検出の料金をご覧ください。
データ プロファイルを無期限に保持する場合、または行われた変更の記録を保持する場合は、プロファイリングを構成するときに、データ プロファイルを BigQuery に保存することを検討してください。プロファイルを保存する BigQuery データセットを選択し、そのデータセットのテーブル有効期限ポリシーを管理します。
スキャン構成のオーバーライド
スキャン構成は、スコープと検出タイプの組み合わせごとに 1 つだけ作成できます。たとえば、BigQuery データ プロファイリング用の組織レベルのスキャン構成と、シークレット検出用の組織レベルのスキャン構成は 1 つだけ作成できます。同様に、BigQuery データ プロファイリング用のプロジェクト レベルのスキャン構成と、シークレット検出用のプロジェクト レベルのスキャン構成は 1 つだけ作成できます。
スコープ内に同じプロジェクトと検出タイプがあるスキャン構成が 2 つ以上有効になっている場合、次のルールが適用されます。
- 組織レベルとフォルダレベルのスキャン構成のうち、プロジェクトに最も近いものがプロジェクトの検出を実行できます。このルールは、同じ検出タイプのプロジェクト レベルのスキャン構成が存在する場合でも適用されます。
- 機密データの保護は、プロジェクト レベルのスキャン構成を組織レベルおよびフォルダレベルの構成とは独立して扱います。プロジェクト レベルで作成したスキャン構成は、親フォルダや親組織用に作成したスキャン構成をオーバーライドすることはできません。
アクティブなスキャン構成が 3 つある次の例について考えてみます。これらのスキャン構成はすべて BigQuery データ プロファイリング用であるとします。
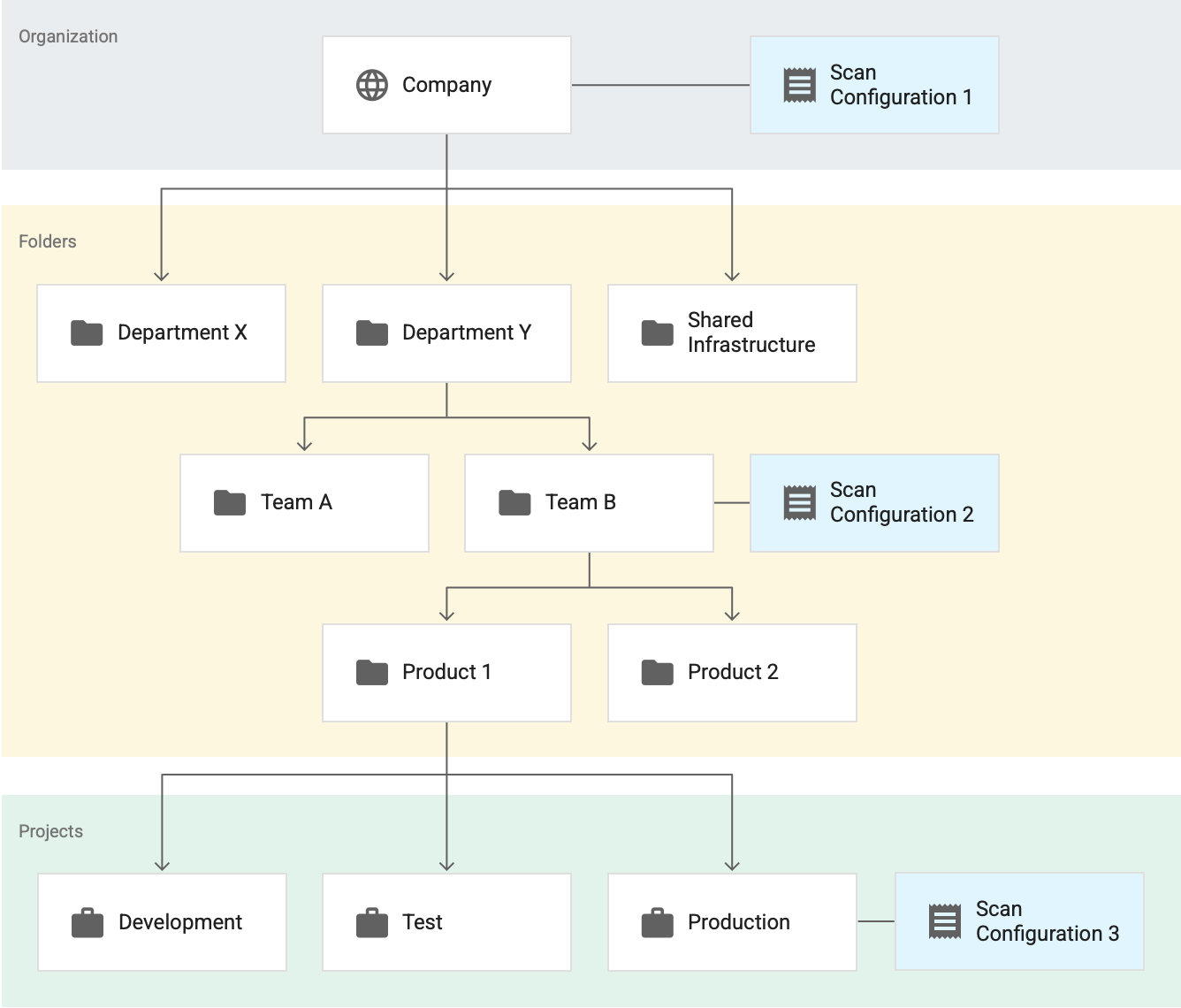
ここで、スキャン構成 1 は組織全体に適用され、スキャン構成 2 は チーム B フォルダに適用され、スキャン構成 3 は本番環境プロジェクトに適用されます。この例では、次のようになります。
- 機密データの保護は、スキャン構成 1 に従って、チーム B フォルダ下にないプロジェクトのすべてのテーブルをプロファイリングします。
- 機密データの保護は、チーム B フォルダのプロジェクト内のすべてのテーブル(本番環境内のテーブルを含む)をスキャン構成 2 に従ってプロファイリングします。
- 機密データの保護は、スキャン構成 3 に従って プロダクション プロジェクトのすべてのテーブルをプロファイリングします。
この例では、機密データの保護によって本番環境プロジェクト用の 2 つのプロファイルのセットが次の各スキャン構成用に 1 セットずつ生成されます。
- スキャン構成 2
- スキャン構成 3
ただし、同じプロジェクトに対して 2 つのプロファイル セットがあっても、ダッシュボードにはそのすべてが一緒に表示されることはありません。表示しているリソース(組織、フォルダ、プロジェクト)とリージョンで生成されたプロファイルのみが表示されます。
Google Cloudのリソース階層の詳細については、リソース階層をご覧ください。
データ プロファイルのスナップショット
各データ プロファイルには、スキャン構成のスナップショットと、その生成に使用された検査テンプレートが含まれています。このスナップショットを使用して、特定のデータ プロファイルの生成に使用した設定を確認できます。
データ所在地に関する検討事項
データ所在地に関する考慮事項は、Google Cloud データまたは他のクラウド プロバイダのデータのどちらをスキャンするかによって異なります。
Google Cloud データのデータ所在地に関する考慮事項
このセクションは、 Google Cloudリソースの機密データ検出にのみ適用されます。他のクラウド プロバイダのリソースに関連するデータ所在地に関する考慮事項については、このページの他のクラウド プロバイダのデータに関するデータ所在地に関する考慮事項をご覧ください。
機密データの保護は、データ所在地をサポートするように設計されています。データ所在地の要件に従う必要がある場合は、次の点を検討してください。
リージョン検査テンプレート
このセクションは、 Google Cloudリソースの機密データ検出にのみ適用されます。他のクラウド プロバイダのリソースに関連するデータ所在地に関する考慮事項については、このページの他のクラウド プロバイダのデータに関するデータ所在地に関する考慮事項をご覧ください。
機密データの保護は、データが保存されているリージョンと同じリージョンでデータを処理します。つまり、データが現在のリージョンから離れることはありません。
また、検査テンプレートは、そのテンプレートと同じリージョンにあるデータをプロファイリングするためにのみ使用できます。たとえば、us-west1 リージョンに保存されている検査テンプレートを使用するように検出を構成すると、機密データの保護はそのリージョン内のデータのみをプロファイリングできます。
データがあるリージョンごとに専用の検査テンプレートを設定できます。global リージョンに保存されている検査テンプレートを指定した場合、機密データの保護は、そのテンプレートを専用の検査テンプレートのないリージョンのデータに使用します。
次の表にシナリオの例を示します。
| シナリオ | サポート |
|---|---|
us リージョンの検査テンプレートを使用して、us リージョンのデータをスキャンします。 |
サポート対象 |
us リージョンの検査テンプレートを使用して、global リージョンのデータをスキャンします。 |
非対応 |
global リージョンの検査テンプレートを使用して、us リージョンのデータをスキャンします。 |
サポート対象 |
us-east1 リージョンの検査テンプレートを使用して、us リージョンのデータをスキャンします。 |
非対応 |
us リージョンの検査テンプレートを使用して、us-east1 リージョンのデータをスキャンします。 |
非対応 |
asia リージョンの検査テンプレートを使用して、us リージョンのデータをスキャンします。 |
非対応 |
データ プロファイルの構成
このセクションは、 Google Cloudリソースの機密データ検出にのみ適用されます。他のクラウド プロバイダのリソースに関連するデータ所在地に関する考慮事項については、このページの他のクラウド プロバイダのデータに関するデータ所在地に関する考慮事項をご覧ください。
機密データの保護は、データ プロファイルを作成する際、スキャン構成と検査テンプレートのスナップショットを作成し、各テーブル データ プロファイルまたはファイル ストア データ プロファイルに保存します。global リージョンの検査テンプレートを使用するように検出を構成すると、機密データの保護はプロファイリングするデータを含む任意のリージョンにテンプレートをコピーします。同様に、スキャン構成もこれらのリージョンにコピーされます。
次の例について考えます。プロジェクト A にテーブル 1 が含まれています。テーブル 1 は us-west1 リージョンにあります。スキャン構成は us-west2 リージョンにあり、検査テンプレートは global リージョンにあります。
機密データの保護は、プロジェクト A をスキャンする際、テーブル 1 のデータ プロファイルを作成し、us-west1 リージョンに保存します。テーブル 1 のテーブル データ プロファイルには、プロファイリング オペレーションで使用されるスキャン構成と検査テンプレートのコピーが含まれています。
検査テンプレートが他のリージョンにコピーされないようにするには、そうした他のリージョン内のデータをスキャンするように機密データの保護を構成しないでください。
データ プロファイルのリージョン ストレージ
このセクションは、 Google Cloudリソースの機密データ検出にのみ適用されます。他のクラウド プロバイダのリソースに関連するデータ所在地に関する考慮事項については、このページの他のクラウド プロバイダのデータに関するデータ所在地に関する考慮事項をご覧ください。
機密データの保護は、データが存在するリージョンまたはマルチリージョンでデータを処理し、生成されたデータ プロファイルを同じリージョンまたはマルチリージョンに保存します。
Google Cloud コンソールでデータ プロファイルを表示するには、まずデータ プロファイルが存在するリージョンを選択する必要があります。複数のリージョンにデータがある場合は、リージョンを切り替えて、各プロファイル セットを表示する必要があります。
サポートされていないリージョン
このセクションは、 Google Cloudリソースの機密データ検出にのみ適用されます。他のクラウド プロバイダのリソースに関連するデータ所在地に関する考慮事項については、このページの他のクラウド プロバイダのデータに関するデータ所在地に関する考慮事項をご覧ください。
Sensitive Data Protection でサポートされていないリージョンにデータがある場合、検出サービスはこれらのデータリソースをスキップし、データ プロファイルを表示するときにエラーが表示されます。
マルチリージョン
Sensitive Data Protection では、マルチリージョンはリージョンの集合ではなく、1 つのリージョンとして扱われます。たとえば、us マルチリージョンと us-west1 リージョンは、データ所在地に関する限り 2 つの別々のリージョンとして扱われます。
ゾーンリソース
Sensitive Data Protection はリージョン サービスとマルチリージョン サービスであり、ゾーンは区別されません。Cloud SQL インスタンスなどのサポートされているゾーンリソースの場合、データは現在のリージョンで処理されますが、必ずしも現在のゾーンで処理されるわけではありません。たとえば、Cloud SQL インスタンスが us-central1-a ゾーンに保存されている場合、機密データの保護はデータ プロファイルを処理して us-central1 リージョンに保存します。
Google Cloud ロケーションの一般的な情報については、地域とリージョンをご覧ください。
他のクラウド プロバイダのデータのデータ所在地に関する考慮事項
他のクラウド プロバイダのデータをプロファイリングする場合は、次の点を考慮してください。
- データ プロファイルは、検出スキャン構成とともに保存されます。一方、 Google Cloud データをプロファイリングする場合、プロファイルはプロファイリングするデータと同じリージョンに保存されます。
- 検査テンプレートを
globalリージョンに保存する場合、検出スキャン構成を保存するリージョンで、そのテンプレートのインメモリ コピーが読み取られます。 - データは変更されません。データのインメモリ コピーは、検出スキャン構成を保存するリージョンで読み取られます。ただし、Sensitive Data Protection は、パブリック インターネットに到達した後にデータが通過する場所について保証しません。データは SSL で暗号化されます。
コンプライアンス
機密データの保護がデータを処理し、コンプライアンス要件を満たすのに役立てる方法については、データ セキュリティをご覧ください。
次のステップ
ID とセキュリティに関するブログ記事の機密データの保護を使用した BigQuery の自動データリスク管理を読む。
データ プロファイリング費用を見積もる方法を確認する。
機密データの保護でデータのプロファイリング時にデータのリスクと機密性レベルを計算する方法について学習する。
検出結果を修正する方法を学習する。
データ プロファイラに関する問題のトラブルシューティングを行う方法を学習する。