K-익명성은 레코드의 재식별성을 나타내는 데이터세트의 속성입니다. 데이터 세트에 있는 각 개인의 유사 식별자가 동일한 데이터 세트에 있는 최소 k – 1명의 다른 사람과 동일한 경우 해당 데이터 세트는 k-익명성을 가집니다.
데이터 세트의 하나 이상의 열 또는 필드를 기준으로 k-익명성 값을 계산할 수 있습니다. 이 주제에서는 Sensitive Data Protection을 사용하여 데이터 세트의 k-익명성 값을 계산하는 방법을 보여줍니다. 계속 진행하기 전에 k-익명성 또는 일반 위험 분석에 대한 자세한 내용은 위험 분석 개념 주제를 참조하세요.
시작하기 전에
계속하기 전에 다음 작업을 완료했는지 확인하세요.
- Google 계정으로 로그인합니다.
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다. 프로젝트 선택기로 이동
- Google Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- Sensitive Data Protection을 사용 설정합니다. Sensitive Data Protection 사용 설정
- 분석할 BigQuery 데이터 세트를 선택합니다. Sensitive Data Protection은 BigQuery 테이블을 스캔하여 k-익명성 측정항목을 계산합니다.
- 데이터 세트에서 식별자(해당되는 경우)와 하나 이상의 유사 식별자를 확인합니다. 자세한 내용은 위험 분석 용어 및 기법을 참조하세요.
k-익명성 계산
Sensitive Data Protection은 위험 분석 작업이 실행될 때마다 위험 분석을 수행합니다. 먼저Google Cloud 콘솔을 사용하거나 DLP API 요청을 전송하거나 Sensitive Data Protection 클라이언트 라이브러리를 사용하여 작업을 만들어야 합니다.
콘솔
Google Cloud 콘솔에서 위험 분석 만들기 페이지로 이동합니다.
입력 데이터 선택 섹션에서 테이블이 포함된 프로젝트의 프로젝트 ID, 테이블의 데이터세트 ID, 테이블 이름을 입력하여 스캔할 BigQuery 테이블을 지정합니다.
계산할 개인정보 보호 측정항목에서 k-익명성을 선택합니다.
작업 ID 섹션에서 작업에 커스텀 식별자를 제공하고 Sensitive Data Protection이 데이터를 처리할 리소스 위치를 선택할 수 있습니다. 완료되었으면 계속을 클릭합니다.
필드 정의 섹션에서 k-익명성 위험 작업의 식별자 및 유사 식별자를 지정합니다. Sensitive Data Protection은 이전 단계에서 지정한 BigQuery 테이블의 메타데이터에 액세스하고 필드 목록을 채우려고 시도합니다.
- 적절한 체크박스를 선택하여 필드를 식별자(ID) 또는 유사 식별자(QI)로 지정합니다. 0개 또는 1개의 식별자와 1개 이상의 유사 식별자를 선택해야 합니다.
- Sensitive Data Protection에서 필드를 채울 수 없으면 필드 이름 입력을 클릭하여 필드를 하나 이상 직접 입력하고 각 필드를 식별자나 유사 식별자로 설정합니다. 완료되었으면 계속을 클릭합니다.
작업 추가 섹션에서 위험 작업이 완료되면 수행할 작업(선택사항)을 추가할 수 있습니다. 사용 가능한 옵션은 다음과 같습니다.
- BigQuery에 저장: 위험 분석 스캔의 결과를 BigQuery 테이블에 저장합니다.
Pub/Sub에 게시: Pub/Sub 주제에 알림을 게시합니다.
이메일로 알림: 결과가 포함된 이메일을 전송합니다. 완료되면 만들기를 클릭합니다.
k-익명성 위험 분석 작업이 즉시 시작됩니다.
C#
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Go
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Java
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
PHP
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
REST
새로운 위험 분석 작업을 실행하여 k-익명성을 계산하려면 projects.dlpJobs 리소스에 요청을 보냅니다. 여기서 PROJECT_ID는 프로젝트 식별자를 나타냅니다.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
요청에는 다음 요소로 구성된 RiskAnalysisJobConfig 객체가 포함됩니다.
PrivacyMetric객체. 여기에서KAnonymityConfig객체를 포함하여 k-익명성을 계산하도록 지정합니다.BigQueryTable객체. 다음을 모두 포함하여 스캔할 BigQuery 테이블을 지정합니다.projectId: 테이블이 포함된 프로젝트의 프로젝트 IDdatasetId: 테이블의 데이터 세트 IDtableId: 테이블의 이름
작업 완료 시 실행할 작업을 나타내는 하나 이상의
Action객체 집합(주어진 순서에 따름). 각Action객체는 다음 작업 중 하나를 포함할 수 있습니다.SaveFindings객체: 위험 분석 스캔의 결과를 BigQuery 테이블에 저장합니다.JobNotificationEmails객체: 결과가 포함된 이메일을 보냅니다.
KAnonymityConfig객체 내에서 다음을 지정합니다.quasiIds[]: k-익명성을 계산할 때 스캔하고 사용할 하나 이상의 유사 식별자(FieldId객체). 여러 개의 유사 식별자를 지정하는 경우 하나의 복합 키로 간주됩니다. 구조체 및 반복 데이터 유형은 지원되지 않지만 중첩 필드는 그 자체가 구조체이거나 반복 필드에 중첩되지 않는 한 지원됩니다.entityId: 선택사항인 식별자 값. 설정되면 k-익명성을 계산할 때 각각의 고유한entityId에 해당하는 모든 행을 그룹화해야 합니다. 일반적으로entityId는 고객 ID 또는 사용자 ID와 같이 순 사용자를 나타내는 열입니다.entityId가 유사 식별자 값이 서로 다른 여러 행에 나타나는 경우 이러한 행은 조인을 통해 해당 항목을 위한 유사 식별자로 사용되는 멀티 세트를 형성합니다. 항목 ID에 대한 자세한 내용은 위험 분석 개념 항목의 항목 ID 및 k-익명성 계산을 참조하세요.
DLP API에 요청을 전송하면 위험 분석 작업이 시작됩니다.
완료된 위험 분석 작업 나열
현재 프로젝트에서 실행된 위험 분석 작업의 목록을 볼 수 있습니다.
Console
Google Cloud 콘솔에서 실행 중이고 이전에 실행된 위험 분석 작업을 나열하려면 다음을 수행합니다.
Google Cloud 콘솔에서 Sensitive Data Protection을 엽니다.
페이지 상단의 작업 및 작업 트리거 탭을 클릭합니다.
위험 작업 탭을 클릭합니다.
위험 작업 목록이 표시됩니다.
프로토콜
실행 중이고 이전에 실행된 위험 분석 작업을 나열하려면 projects.dlpJobs 리소스에 GET 요청을 보냅니다. 작업 유형 필터(?type=RISK_ANALYSIS_JOB)를 추가하면 응답의 범위를 위험 분석 작업으로 좁힙니다.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
수신하는 응답에는 현재 및 이전 위험 분석 작업의 JSON 표현이 포함됩니다.
k-익명성 작업 결과 보기
Google Cloud 콘솔의 Sensitive Data Protection에는 완료된 k-익명성 작업의 시각화 기능이 기본 제공됩니다. 이전 섹션의 안내를 따른 후 위험 분석 작업 목록에서 결과를 확인할 작업을 선택합니다. 작업이 성공적으로 실행되었다고 가정하면 위험 분석 세부정보 페이지 상단에 다음과 같이 표시됩니다.
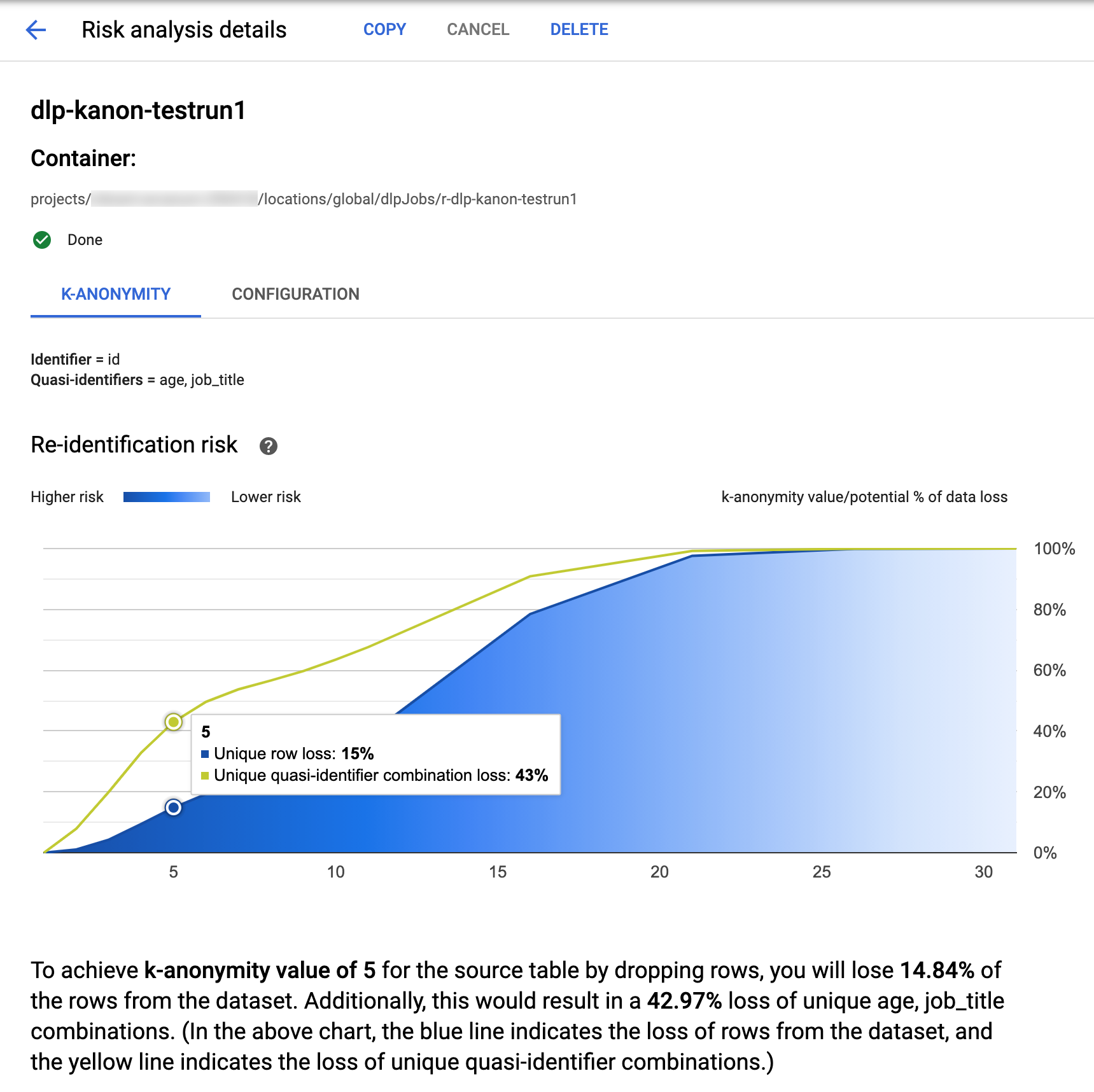
페이지 상단에 작업 ID를 포함한 k-익명성 위험 작업에 대한 정보가 나와 있으며 컨테이너에는 리소스 위치가 표시됩니다.
k-익명성 계산 결과를 보려면 K-익명성 탭을 클릭합니다. 위험 분석 작업의 구성을 보려면 구성 탭을 클릭합니다.
K-익명성 탭에는 먼저 항목 ID(있는 경우)와 k-익명성을 계산하는 데 사용되는 유사 식별자가 나열됩니다.
위험 차트
재식별 위험 차트의 y축은 고유 행과 고유 유사 식별자 조합에 대한 데이터 손실의 잠재적 비율이며 x축은 k-익명성 값입니다. 차트의 색상도 위험 가능성도 나타냅니다. 파란색이 어두울수록 위험이 높으며 밝을 수록 위험이 적습니다.
k-익명성 값이 높으면 재식별 위험이 줄어듭니다. 그러나 k-익명성 값을 높이려면 총 행의 높은 비율과 높은 고유 유사 식별자 조합을 삭제해야 할 수 있으며 이는 데이터의 유용성을 낮춥니다. 특정 k-익명성 값의 특정 잠재적 백분율 손실 값을 보려면 차트 위로 마우스 커서를 가져가세요. 스크린샷과 같이 차트에 도움말이 표시됩니다.
특정 k-익명성 값에 대한 자세한 내용을 보려면 해당 데이터 포인트를 클릭합니다. 차트 아래에 자세한 설명이 표시되고 샘플 데이터 테이블이 페이지 아래쪽에 표시됩니다.
위험 샘플 데이터 표
위험 작업 결과 페이지의 두 번째 구성요소는 샘플 데이터 테이블입니다. 지정된 대상 k-익명성 값에 대한 유사 식별자 조합을 표시합니다.
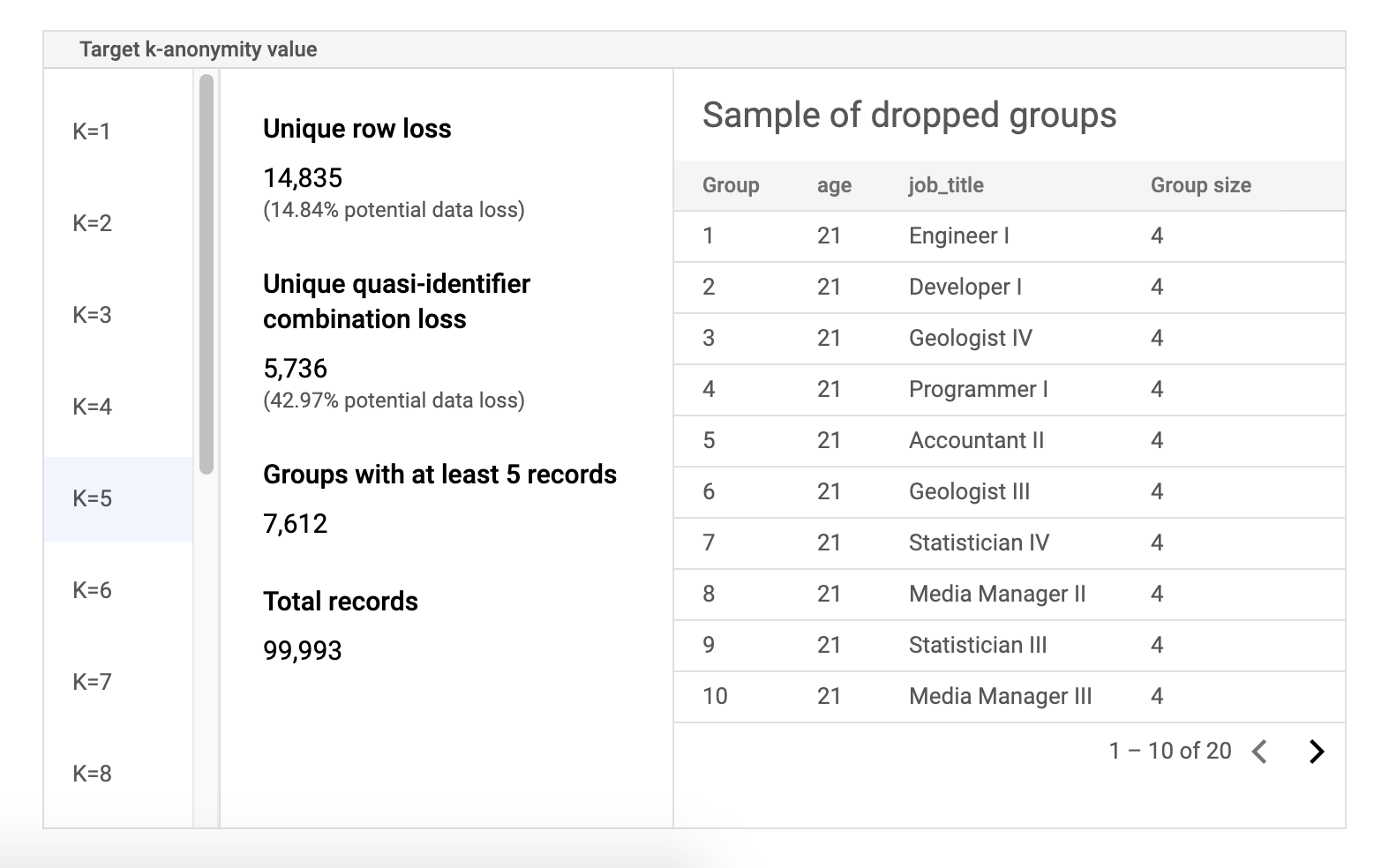
테이블의 첫 번째 열에는 k-익명성 값이 나열됩니다. k-익명성 값을 클릭하면 값을 얻기 위해 삭제되어야 할 해당 샘플 데이터가 표시됩니다.
두 번째 열은 고유한 행 및 유사 식별자 조합의 잠재적 데이터 손실과 최소 k 레코드가 있는 그룹 수와 총 레코드 수를 표시합니다.
마지막 열에는 유사 식별자 조합을 공유하는 그룹의 샘플과 해당 조합에 존재하는 레코드 수가 표시됩니다.
REST를 사용하여 작업 세부정보 검색
REST API를 사용하여 k-익명성 위험 분석 작업의 결과를 검색하려면 다음 GET 요청을 projects.dlpJobs 리소스에 보냅니다. PROJECT_ID를 프로젝트 ID로 바꾸고 JOB_ID를 결과를 가져올 작업 식별자로 바꿉니다.
작업 ID는 작업 시작 시 반환되었으며 모든 작업을 나열하여 검색할 수도 있습니다.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
요청은 작업 인스턴스가 포함된 JSON 객체를 반환합니다. 분석 결과는 AnalyzeDataSourceRiskDetails 객체의 "riskDetails" 키 내에 있습니다. 자세한 내용은 DlpJob 리소스의 API 참조를 확인하세요.
코드 샘플: 항목 ID를 사용하여 k-익명성 계산
이 예시에서는 엔티티 ID를 사용하여 k-익명성을 계산하는 위험 분석 작업을 만듭니다.
항목 ID에 대한 자세한 내용은 항목 ID 및 k-익명성 계산을 참고하세요.
C#
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Go
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Java
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
PHP
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
민감한 정보 보호의 클라이언트 라이브러리를 설치하고 사용하는 방법은 민감한 정보 보호 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.