Sensitive Data Protection을 사용하면 인프라 내에 존재하는 민감한 정보를 검색, 확인, 관리할 수 있습니다. Sensitive Data Protection을 사용하여 콘텐츠에서 민감한 정보를 스캔한 후 해당 데이터 인텔리전스로 수행할 작업을 선택할 수 있습니다. 이 주제에서는 BigQuery, Cloud SQL, Looker Studio와 같은 다른 Google Cloud 기능을 활용하여 다음을 수행하는 방법을 보여줍니다.
- Sensitive Data Protection 스캔 결과를 BigQuery에 직접 저장
- 인프라에서 민감한 정보 위치에 대한 보고서 생성
- 풍부한 SQL 분석을 실행하여 민감한 정보가 저장된 위치와 정보의 종류 파악
- 단일 집합 또는 결과 조합을 기준으로 알림 또는 작업을 자동으로 트리거
또한 이 주제에는 이러한 모든 사항을 수행하기 위해 Sensitive Data Protection을 다른 Google Cloud 기능과 함께 사용하는 방법의 전체 예시도 포함되어 있습니다.
저장소 버킷 스캔
먼저 데이터를 대상으로 스캔을 실행합니다. 다음은 Sensitive Data Protection을 사용하여 스토리지 저장소를 스캔하는 방법에 대한 기본 정보입니다. 클라이언트 라이브러리 사용을 포함한 스토리지 저장소 스캔에 대한 자세한 안내는 스토리지 및 데이터베이스에서 민감한 정보 조사를 참조하세요.
Google Cloud 스토리지 저장소에서 스캔 작업을 실행하려면 다음 구성 객체가 포함된 JSON 객체를 조합합니다.
InspectJobConfig: Sensitive Data Protection 스캔 작업을 구성하며 다음 요소로 구성됩니다.StorageConfig: 스캔할 스토리지 저장소.InspectConfig: 스캔 방법 및 검색 대상. 검사 템플릿을 사용하여 검사 구성을 정의할 수도 있습니다.Action: 작업 완료 시 실행할 태스크. 결과를 BigQuery 테이블에 저장하거나 Pub/Sub에 알림 게시하기 등이 포함될 수 있습니다.
이 예에서는 Cloud Storage 버킷에서 사람 이름, 전화번호, 미국 주민등록번호, 이메일 주소를 스캔합니다. 그런 다음 Sensitive Data Protection 출력 저장 전용 BigQuery 테이블로 결과를 보냅니다. 다음 JSON을 파일에 저장하거나 DlpJob Sensitive Data Protection 리소스의 create 메서드에 직접 보낼 수 있습니다.
JSON 입력:
POST https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs
{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"includeQuote":true
},
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
Cloud Storage 버킷 주소(gs://[BUCKET_NAME]/**) 다음에 별표 두 개(**)를 지정하면 스캔 작업이 반복적으로 수행됩니다. 별표 한 개(*)만 입력하면 지정된 디렉터리 레벨만 스캔하고 더 깊게 들어가지 않습니다.
출력은 주어진 데이터 세트 및 프로젝트 내의 지정된 테이블에 저장됩니다. 주어진 테이블 ID를 지정하는 후속 작업에서는 동일한 테이블에 결과를 추가합니다. 또한 스캔이 실행될 때마다 Sensitive Data Protection이 새 테이블을 만들도록 지정하려면 "tableId" 키를 생략하면 됩니다.
지정된 URL을 통해 projects.dlpJobs.create 메서드 요청에 이 JSON을 보내면 다음 응답이 표시됩니다.
JSON 출력:
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"PENDING",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
},
"createTime":"2018-11-19T21:09:07.926Z"
}
작업이 완료되면 주어진 BigQuery 테이블에 결과가 저장됩니다.
작업 상태를 가져오려면 projects.dlpJobs.get 메서드를 호출하거나 다음 URL로 GET 요청을 전송합니다. 이 경우 [PROJECT_ID]를 프로젝트 ID로, [JOB_ID]를 작업 생성 요청에 대한 Cloud Data Loss Prevention API의 응답에 지정된 작업 식별자로 바꿉니다(작업 식별자는 앞에 'i-'가 붙음).
GET https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs/[JOB_ID]
방금 만든 작업에서 이 요청은 다음 JSON을 반환합니다. 검사 세부정보 이후 스캔 결과의 요약이 반환됩니다. 스캔이 아직 완료되지 않은 경우 "state" 키에 "RUNNING"이 지정됩니다.
JSON 출력:
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
},
"result":{
"processedBytes":"536734051",
"totalEstimatedBytes":"536734051",
"infoTypeStats":[
{
"infoType":{
"name":"PERSON_NAME"
},
"count":"269679"
},
{
"infoType":{
"name":"EMAIL_ADDRESS"
},
"count":"256"
},
{
"infoType":{
"name":"PHONE_NUMBER"
},
"count":"7"
}
]
}
},
"createTime":"2018-11-19T21:09:07.926Z",
"startTime":"2018-11-19T21:10:20.660Z",
"endTime":"2018-11-19T22:07:39.725Z"
}
BigQuery에서 분석 실행
이제 Sensitive Data Protection 스캔의 결과가 포함된 새 BigQuery 테이블을 만들었으므로 다음 단계는 테이블에서 분석을 실행하는 것입니다.
Google Cloud 콘솔의 왼쪽, 빅데이터 아래에서 BigQuery를 클릭합니다. 프로젝트와 데이터 세트를 연 다음 생성된 새 테이블을 찾습니다.
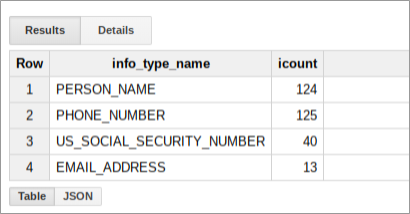
이 테이블에서 SQL 쿼리를 실행하여 데이터 버킷 내에서 Sensitive Data Protection이 찾은 정보에 대해 더 자세히 알아볼 수 있습니다. 예를 들어 자리표시자를 적절한 실제 값으로 바꿔 다음을 실행하여 infoType별로 모든 스캔 결과의 수를 계산합니다.
SELECT
info_type.name,
COUNT(*) AS iCount
FROM
`[PROJECT_ID].[DATASET_ID].[TABLE_ID]`
GROUP BY
info_type.name
이 쿼리의 결과는 해당 버킷에 대한 결과의 요약으로, 다음과 같은 형태가 됩니다.
Looker Studio에서 보고서 작성하기
Looker Studio를 사용하여 BigQuery 테이블을 기반으로 하는 커스텀 보고서를 만들 수 있습니다. 이 섹션에서는 Looker Studio에서 BigQuery에 저장된 Sensitive Data Protection 발견 항목을 기반으로 하는 간단한 테이블 보고서를 만듭니다.
- Looker Studio를 열고 새 보고서를 시작합니다.
- 새 데이터 소스 만들기를 클릭합니다.
- 커넥터 목록에서 BigQuery를 클릭합니다. 필요한 경우 승인을 클릭하여 Looker Studio에서 BigQuery 프로젝트로 연결하도록 승인합니다.
- 이제 검색할 테이블을 선택한 다음 프로젝트의 위치에 따라 내 프로젝트 또는 공유 프로젝트를 클릭합니다. 페이지의 목록에서 프로젝트, 데이터 세트, 테이블을 찾습니다.
- 연결을 클릭하여 보고서를 실행합니다.
- 보고서에 추가를 클릭합니다.
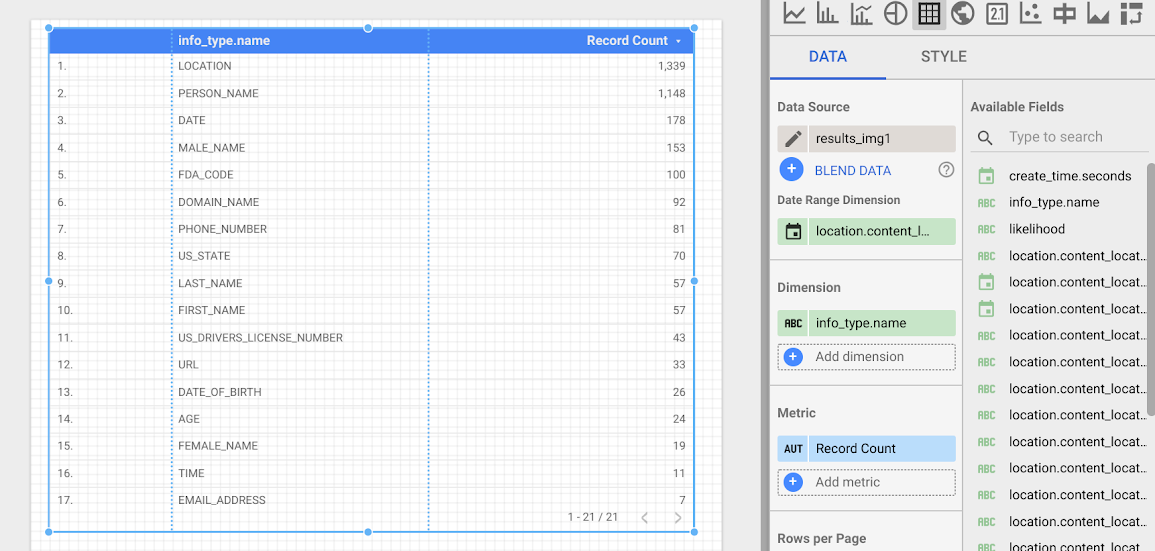
이제 각 infoType의 빈도를 표시하는 테이블을 만듭니다. info_type.name 필드를 측정기준으로 선택합니다. 결과 테이블은 다음과 비슷하게 표시됩니다.
다음 단계
여기서 살펴본 내용은 Looker Studio와 Sensitive Data Protection의 출력을 사용한 시각화의 시작일 뿐입니다. 다른 차트 요소와 상세보기 필터를 추가하여 대시보드와 보고서를 만들 수 있습니다. Looker Studio에서 사용할 수 있는 항목에 대한 자세한 내용은 Looker Studio 제품 개요를 참고하세요.