Mainframe Connector 會將排隊循序存取方法 (QSAM) 平面檔案轉碼為 Google Cloud 相容格式,並使用 qsam 指令執行反向作業。qsam 指令會執行下列轉碼作業:
qsam decode指令會將大型主機資料解碼為 Google Cloudqsam encode指令會將 Google Cloud 資料編碼至大型主機。
這些作業會執行對稱轉換,也就是將相同資料移至 Google Cloud和從 Google Cloud移出。您可以使用 COBOL 資料結構定義,在副本檔案中定義 QSAM 檔案的結構。您也可以使用 Mainframe Connector 轉碼器設定檔定義進階轉換。下圖詳細說明這些作業。
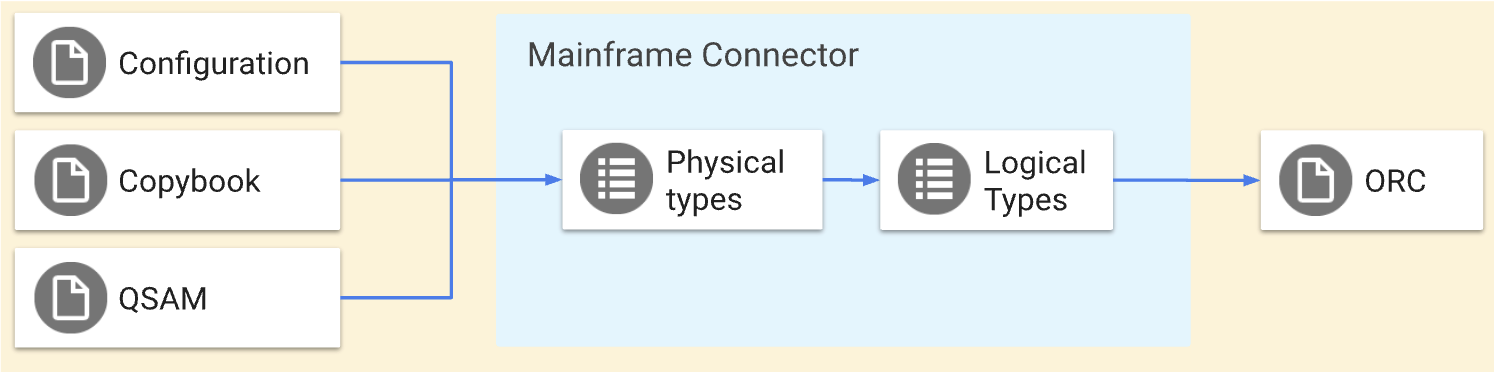
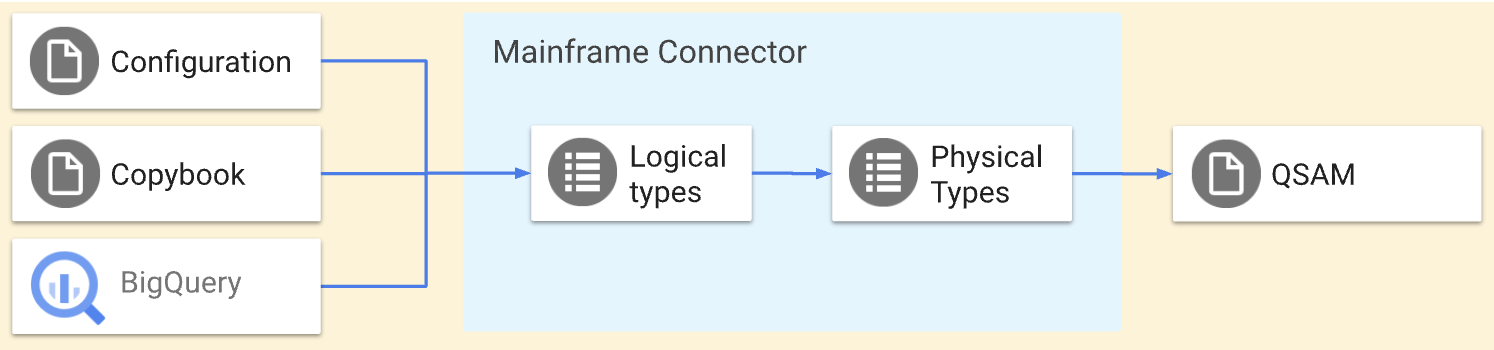
本頁面將概要說明如何使用 qsam decode 和 qsam encode 指令進行轉碼程序、大型主機資料的實體和邏輯類型,以及最佳化列直欄 (ORC) 和 BigQuery 類型對應。
實體類型
實體型別會定義磁碟上的欄位資料版面配置。實體型別會轉換為 Mainframe Connector 邏輯型別,然後對應至資料庫型別 (ORC 或 BigQuery)。
英數字元欄位
英數字元欄位用於處理英數字元字串。資料會視為一系列字元,並以特定編碼 (例如擴充二進位編碼十進位交換碼 (EBCDIC)) 儲存為字串。如果在英數字元欄位的編碼或解碼過程中發生任何錯誤,轉碼程序不會終止。系統不會停止轉碼程序,而是會在發生錯誤的位置放置編碼的 SUB 字元,並繼續轉碼程序。
| 圖片符號 | 圖片屬性 | 邏輯類型 |
|---|---|---|
| A、B、G、N、U、X、9 | DISPLAY、DISPLAY-1、NATIONAL、UTF-8 | 字串 |
示例
01 REC 02 STR PIC X(10) 02 NATIONAL PIC N(10) 02 UTF8 PIC U(1) USAGE UTF-8
編碼格式
英數字元欄位的編碼方式如下:
- X 個欄位預設為 EBCDIC 編碼
- 國家 (N) 欄位預設為 Unicode Transformation Format 16 位元 (UTF-16 BE) 編碼
- UTF8 欄位預設採用 Unicode Transformation Format-8 (UTF-8) 編碼
Mainframe Connector 支援大多數單一位元組字元集 (SBCS) 和雙位元組字元集 (DBCS) 編碼。您也可以視需要定義自己的自訂 SBCS 編碼。
二進位欄位 (COMPUTATIONAL)
二進位欄位會儲存為有正負號或無正負號的大端序整數。Mainframe Connector 一律會以邏輯方式將二進位欄位儲存為帶正負號的 64 位元整數。因此,未簽署的 long 輸入內容只能使用較低的 63 位元,否則轉碼程序會失敗。
| 圖片符號 | 圖片屬性 | 邏輯類型 |
|---|---|---|
| S、9 | COMP、COMPUTATIONAL | Long (帶正負號的 64 位元整數) |
示例
01 REC 02 INT PIC S9(8) COMP
十六進位浮點欄位 (COMP-1、COMP-2)
完全支援十六進位浮點 (HFP) 欄位。 Mainframe Connector 會使用單精度和雙精度格式,處理 HFP 欄位。
| 圖片符號 | 圖片屬性 | 邏輯類型 |
|---|---|---|
| COMP-1、COMP-2 | Double (64 位元帶正負號的浮點數) |
示例
01 REC 03 HFP-SINGLE COMP-1. 03 HFP-DOUBLE COMP-2.
封裝十進位欄位 (COMP-3)
系統完全支援封裝十進位欄位,在轉碼過程中,Mainframe Connector 會根據指定的精確度和比例,選取效能最佳的邏輯類型。
| 圖片符號 | 圖片屬性 | 邏輯類型 |
|---|---|---|
| S、9、V | COMP-3 | Long (帶正負號的 64 位元整數)、BigInteger、Decimal64、BigDecimal |
示例
01 REC 02 DEC PIC S9(2)V9(8) COMP-3
分區十進位欄位 (DISPLAY)
系統完全支援分區十進位欄位。在轉碼過程中,Mainframe Connector 會根據指定的精確度和比例,選取效能最佳的邏輯類型。
| 圖片符號 | 圖片屬性 | 邏輯類型 |
|---|---|---|
| S、9、V | 多媒體廣告聯播網 | Long (帶正負號的 64 位元整數)、BigInteger、Decimal64、BigDecimal |
示例
01 REC 02 DEC PIC S9(2)V9(8) DISPLAY
清單 (OCCURS)
清單是相同類型元素的有序集合。 Mainframe Connector 支援下列類型的清單:
固定清單
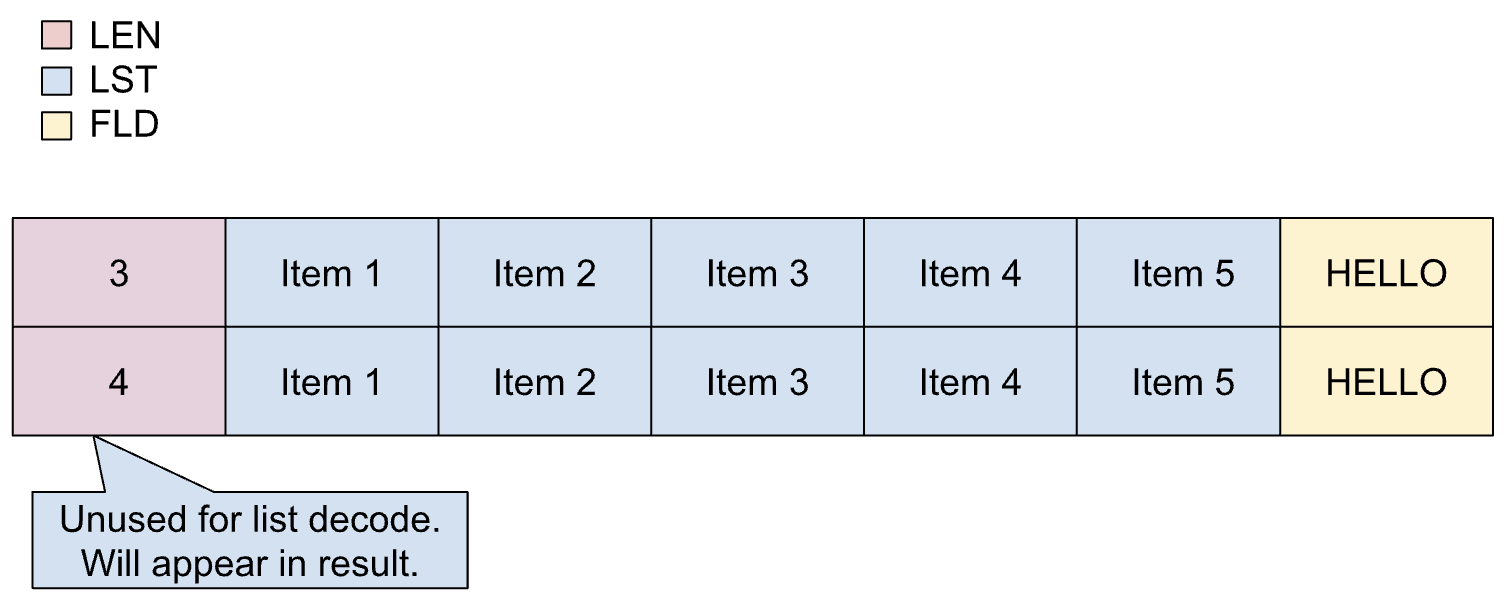
如果事先知道清單中的確切項目數量 (項目計數),且這個數量一律維持不變,則可使用固定清單。固定清單中的項目大小不一。
副本中的固定清單定義如下:
01 REC.
02 LIST OCCURS 5 TIMES PIC X(1).
02 FLD PIC X(5).
下圖顯示固定清單的版面配置,其中包含 5 個項目。
動態清單
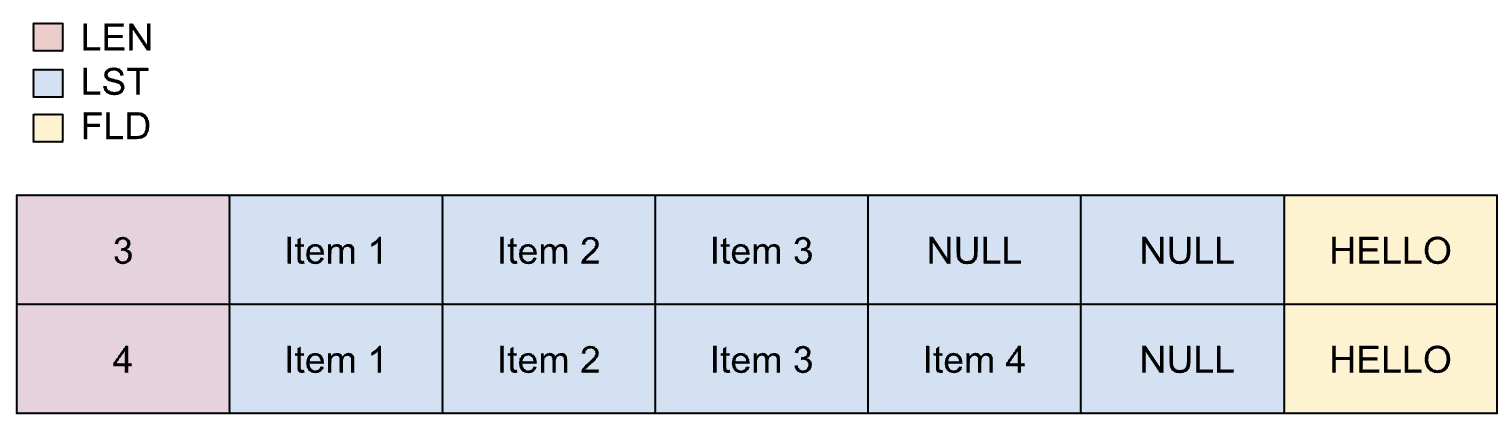
如果事先知道清單中項目的數量上限,請使用動態清單。不過,實際的項目數量不明,且取決於另一個欄位。動態清單中的項目大小不一。
動態清單的屬性如下:
- 長度欄位可轉換為整數,不會失去精確度。
- 長度欄位必須在範圍內。
- 轉碼程序不會強制執行最低項目數。
副本中的動態清單定義如下:
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS 1 TO 5 TIMES
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
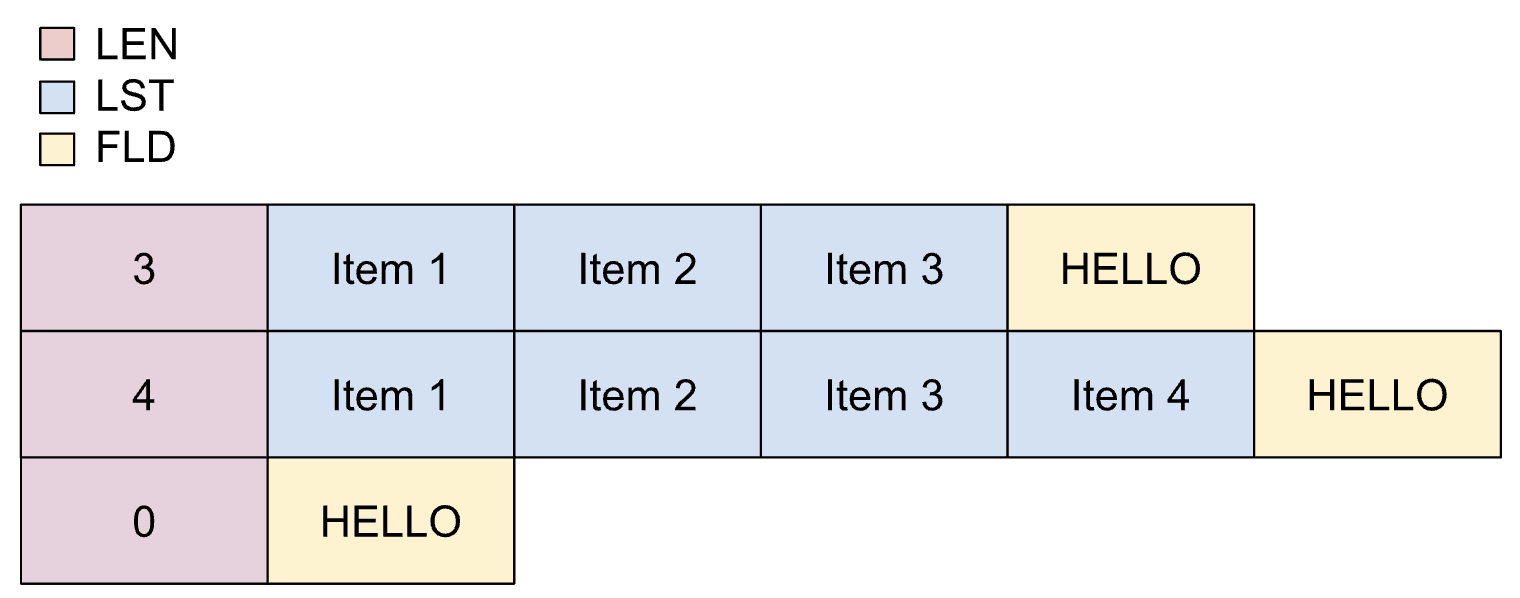
下圖顯示動態清單的版面配置,最多可顯示五個項目。
已封裝的動態清單
如果清單中項目的數量上限取決於另一個欄位,且項目已封裝,則會使用封裝的動態清單。
封裝動態清單的屬性如下:
- 長度欄位可轉換為整數,不會失去精確度。
- 長度欄位必須在範圍內。
- 轉碼程序不會強制執行最低項目數。
副本中的封裝動態清單定義如下:
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS UNBOUNDED
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
下圖顯示封裝動態清單的版面配置。
重新定義 (REDEFINES)
重新定義 是 COBOL 功能,可讓相同資料有多種解碼方式。在解碼過程中,重新定義會以結果表格中的額外資料欄形式顯示,且資料會多次解碼。
重新定義的屬性如下:
- 相同基礎資料的重新定義並非同層級欄位,因此彼此不在範圍內。
- 重新定義的欄位會在基礎欄位解碼時解碼,而不是在宣告時解碼。基礎欄位也會決定重新定義欄位的範圍。
- 所有重新定義的欄位都必須大小相同,且必須是固定大小。也就是說,您無法在重新定義的欄位中使用可變長度的文字欄位和封裝動態清單。
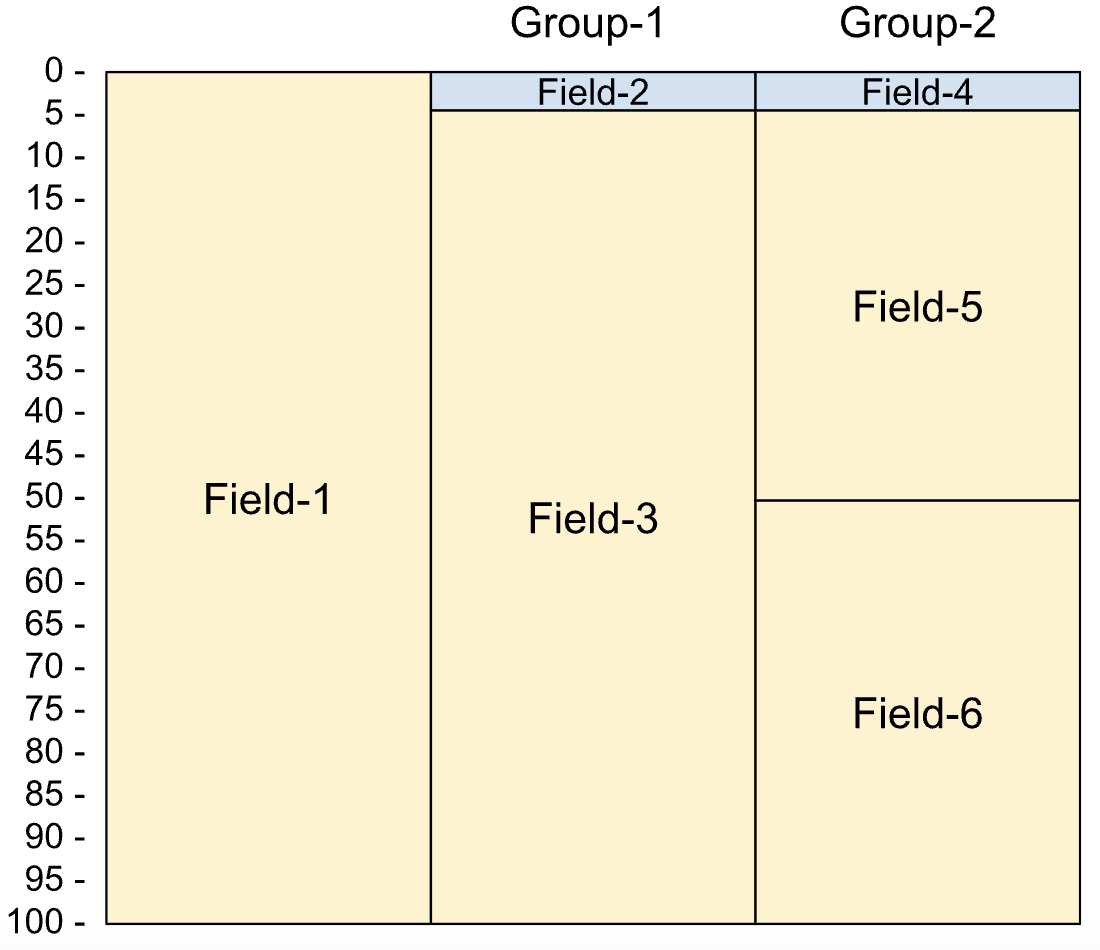
副本中的重新定義如下:
01 Rec.
05 Field-1 PIC X(100).
05 Group-1 REDEFINES Field-1.
10 Field-2 PIC 9(5) comp-3.
10 Field-3 PIC X(96).
05 Group-2 REDEFINES Field-1.
10 Field-4 PIC 9(4) comp-4.
10 Field-5 PIC X(50).
10 Field-6 PIC X(46).
下圖顯示重新定義的欄位版面配置。
重新定義有多種用途,以下是最常見的用途:
以兩種不同方式查看相同資料:這是最常見的重新定義使用方式。在編碼過程中,資料的填入順序未定義,因此您必須確保匯出時 BigQuery 中的資料保持完整性。
示例
01 REC. 02 FULL-NAME PIC X(12). 02 NAME REDEFINES FULL-NAME. 05 FIRST-NAME PIC X(6). 05 LAST-NAME PIC X(6).使用標記聯集:當您只需要任何記錄的其中一種資料解讀方式 (取決於某個欄位) 時,標記聯集是使用重新定義的常見方式。您可以使用空值指標,將不需要的解讀標示為空值。這樣一來,系統就不會因指標為空值而剖析這些值, 進而延遲評估。已加上標記的聯集屬性如下:
- 如果定義多個重新定義,編碼程序就會失敗。
- 系統只會實作等式和非等式檢查。
示例
01 REC. 05 TYPE PIC X(5). 05 DATA PIC X(100). 05 VARIANT-1 REDEFINES DATA. 10 Field-2 PIC 9(4) comp-3. 10 Field-3 PIC X(96). 05 VARIANT-2 REDEFINES DATA. 10 Field-4 PIC 9(4) comp-5. 10 Field-5 PIC X(50). 10 Field-6 PIC X(46).您可以參考下列範例實作標記聯集:
{ "field_override": [ { "field": "VARIANT-1", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR1" } } }, { "field": "VARIANT-2", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR2" } } } ], "transformations": [ { "field": "DATA", "transformation": { "exclude": {}} } ] }
邏輯類型
如要將資料轉碼為多種格式,Mainframe Connector 會將所有資料轉換為以邏輯型別為基礎的中間表示法 (IR)。輸入和輸出格式定義資料如何轉換為任何邏輯型別,以及如何從任何邏輯型別轉換資料。下表列出 Mainframe Connector 支援的所有邏輯型別。
| 邏輯類型 | 說明 |
|---|---|
| BigDecimal | 代表任何小數位數和有效位數的十進位數字。 |
| BigInteger | 代表任何大小的整數。 |
| 位元組 | 代表可變大小的位元組陣列。 |
| 日期 | 代表與特定時區無關的日期。 |
| Decimal64 | 代表小數,範圍可容納任何比例的 64 位元帶正負號整數。 |
| 雙精度值 | 表示雙精確度浮點數,如 IEEE 浮點運算標準 (IEEE 754) 所述。 |
| 清單 | 代表特定類型的項目清單。清單可包含任意數量的項目。 |
| 長 | 代表帶正負號的 64 位元數字。 |
| 錄製 | 代表一系列固定欄位,但類型各不相同。 |
| 字串 | 代表與任何特定編碼無關的 Unicode 字元字串。可表示任何有效的 Unicode 碼點。不過,部分字元可能無法在所有編碼程序中編碼。邏輯字串 長度不一。 |
| 時間戳記 | 代表與特定時區無關的時間戳記。 |
ORC 類型對應
下表列出 Mainframe Connector 邏輯型別與 ORC 型別的對應關係。
| 邏輯類型 | ORC 類型 |
|---|---|
| BigDecimal | decimal |
| BigInteger | decimal |
| 位元組 | 二進位大型物件 |
| 日期 | 日期 |
| Decimal64 | decimal64 |
| 雙精度值 | float64 |
| 清單 | list |
| 長 | 64 位元整數 (bigint) |
| 錄製 | 結構體 |
| 字串 | UTF-8 編碼字串 |
| 時間戳記 | 時間戳記 (不含當地時區) |
BigQuery 類型對應
下表列出 Mainframe Connector 邏輯型別與 BigQuery 資料型別的對應關係。
| 邏輯類型 | BigQuery 資料類型 | 註解 |
|---|---|---|
| BigDecimal | NUMERIC | |
| BigInteger | NUMERIC | |
| 位元組 | BYTES | |
| 日期 | DATE | |
| Decimal64 | NUMERIC | |
| 雙精度值 | FLOAT64 | |
| 清單 | ARRAY | 不支援巢狀清單與對應清單。 |
| 長 | INT64 | |
| 錄製 | STRUCT | 當 union 只有一個變體時,系統會將其轉換為 NULLABLE 欄位。
否則,會將 union 轉換為含有 NULLABLE 欄位清單的 RECORD。
NULLABLE 欄位的後置字串為 field_0、field_1。系統讀取資料時,只會為其中一個欄位指派值。 |
| 字串 | STRING | |
| 時間戳記 | TIMESTAMP |
欄位範圍
如果欄位符合下列任一條件,即視為另一個欄位的適用範圍:
- 在需要該欄位之前定義的同層級欄位。
- 父項記錄中的欄位,定義在需要該欄位的欄位之前。