Mainframe Connector 使用 qsam 命令将排队的顺序存取方法 (QSAM) 平面文件转码为 Google Cloud 兼容格式,反之亦然。qsam 命令可执行以下转码操作:
qsam decode命令将大型主机数据解码为 Google Cloudqsam encode命令将 Google Cloud 数据编码到大型主机。
这些操作执行的是对称转换,也就是说,它们会以相同的方式将数据移入和移出 Google Cloud。您可以使用 COBOL 数据结构定义在 copybook 文件中定义 QSAM 文件的结构。您还可以使用 Mainframe Connector 转码器配置文件定义高级转换。以下图表详细介绍了这些操作。
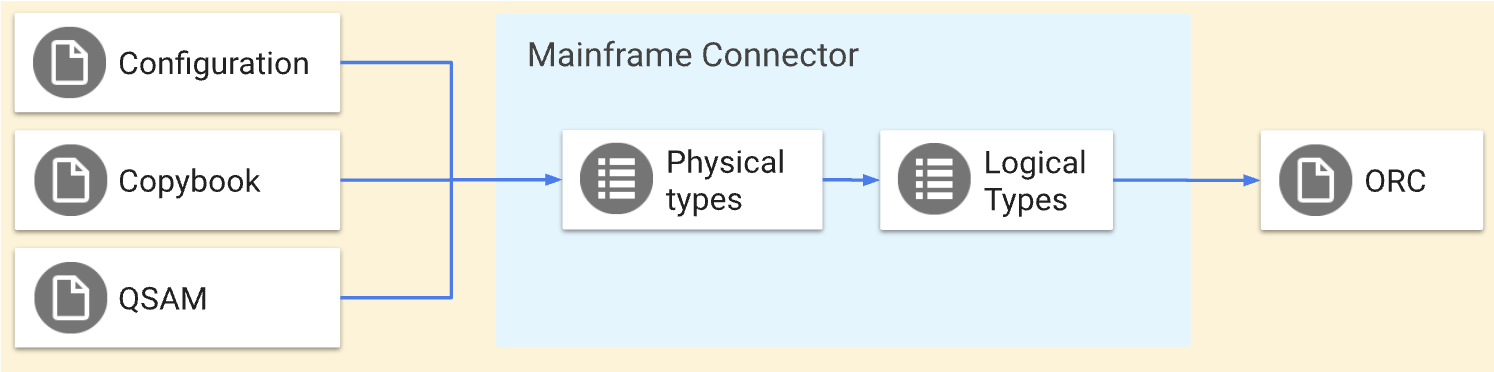
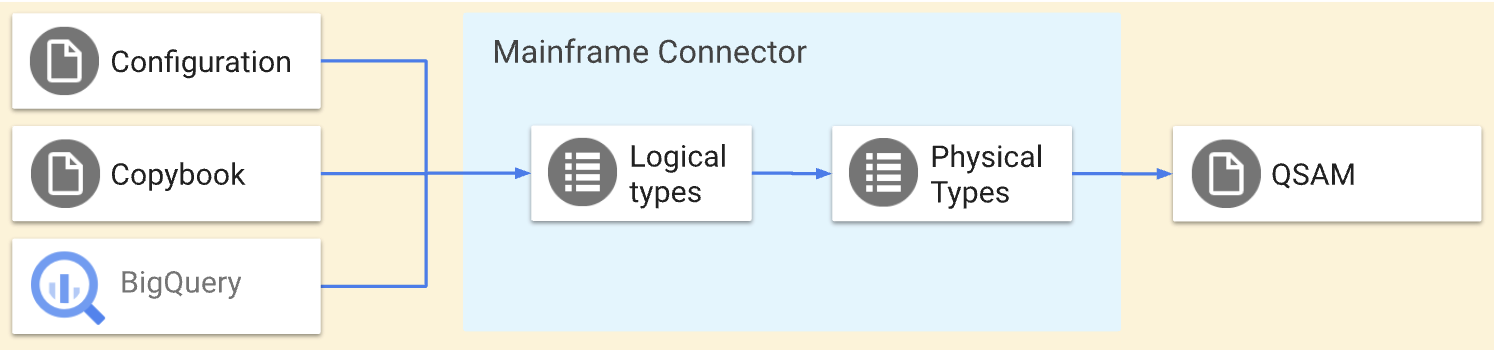
本页简要介绍了使用 qsam decode 和 qsam encode 命令的转码流程、大型机数据的物理类型和逻辑类型,以及优化列式行 (ORC) 类型和 BigQuery 类型映射。
实体类型
物理类型用于定义字段数据在磁盘上的布局方式。物理类型会转换为 Mainframe Connector 逻辑类型,然后可以映射到数据库类型(ORC 或 BigQuery)。
字母数字字段
字母数字字段用于处理字母数字字符串。数据被视为一系列字符,并以特定编码(例如扩展的二进制编码十进制交换码 [EBCDIC])的字符串形式存储。如果在对字母数字字段进行编码或解码期间出现任何错误,转码过程不会终止。而是会在发生错误的位置放置一个 SUB 字符(用于表示编码),然后继续进行转码。
| 图片符号 | 图片属性 | 逻辑类型 |
|---|---|---|
| A、B、G、N、U、X、9 | DISPLAY、DISPLAY-1、NATIONAL、UTF-8 | 字符串 |
示例
01 REC 02 STR PIC X(10) 02 NATIONAL PIC N(10) 02 UTF8 PIC U(1) USAGE UTF-8
编码格式
字母数字字段的编码方式如下:
- X 个字段默认采用 EBCDIC 编码
- 国家 (N) 字段默认采用 Unicode 转换格式 16 位 (UTF-16 BE) 编码
- UTF8 字段默认采用 Unicode 转换格式 8 (UTF-8) 编码
Mainframe Connector 支持大多数单字节字符集 (SBCS)、双字节字符集 (DBCS) 编码。如果需要,您还可以定义自己的自定义 SBCS 编码。
二元字段(计算型)
二进制字段存储为有符号或无符号的大端序整数。Mainframe Connector 始终以逻辑方式将二进制字段存储为带符号的 64 位整数。因此,无符号 long 输入必须仅使用低 63 位,否则转码过程会失败。
| 图片符号 | 图片属性 | 逻辑类型 |
|---|---|---|
| S、9 | COMP、计算 | Long(有符号 64 位整数) |
示例
01 REC 02 INT PIC S9(8) COMP
十六进制浮点数字段(COMP-1、COMP-2)
十六进制浮点数 (HFP) 字段完全受支持。 Mainframe Connector 同时使用单精度和双精度格式来表示 HFP 字段。
| 图片符号 | 图片属性 | 逻辑类型 |
|---|---|---|
| COMP-1、COMP-2 | Double(64 位有符号浮点数) |
示例
01 REC 03 HFP-SINGLE COMP-1. 03 HFP-DOUBLE COMP-2.
打包十进制字段 (COMP-3)
完全支持打包的十进制字段。在转码过程中,Mainframe Connector 会根据指定的精度和比例选择性能最高的逻辑类型。
| 图片符号 | 图片属性 | 逻辑类型 |
|---|---|---|
| S、9、V | COMP-3 | Long(有符号 64 位整数)、BigInteger、Decimal64、BigDecimal |
示例
01 REC 02 DEC PIC S9(2)V9(8) COMP-3
分区十进制字段 (DISPLAY)
完全支持分区十进制字段。在转码过程中,Mainframe Connector 会根据指定的精度和比例选择性能最高的逻辑类型。
| 图片符号 | 图片属性 | 逻辑类型 |
|---|---|---|
| S、9、V | 展示广告系列 | Long(有符号 64 位整数)、BigInteger、Decimal64、BigDecimal |
示例
01 REC 02 DEC PIC S9(2)V9(8) DISPLAY
列表 (OCCURS)
列表是相同类型元素的有序集合。 Mainframe Connector 支持以下类型的列表:
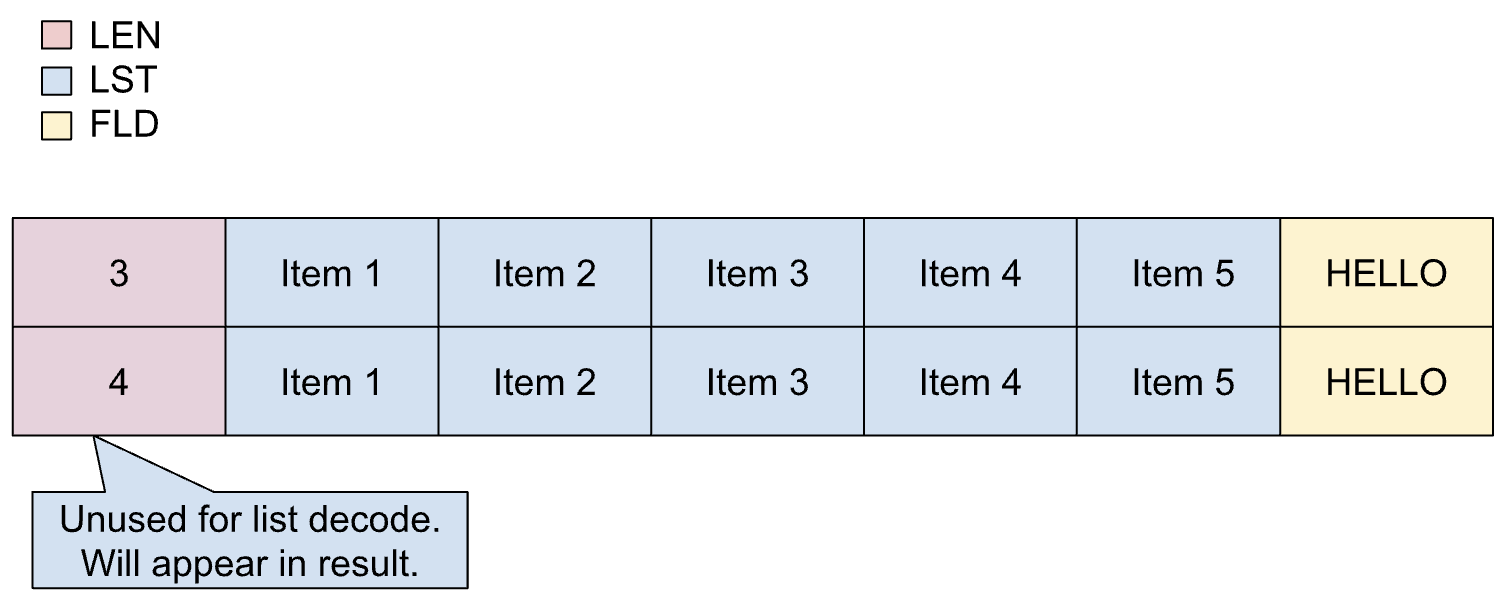
固定列表
如果预先知道列表中的确切项数(项计数),并且此数量始终保持不变,则使用固定列表。固定列表中的项可以是可变大小。
在 copybook 中,固定列表的定义如下:
01 REC.
02 LIST OCCURS 5 TIMES PIC X(1).
02 FLD PIC X(5).
下图显示了项数为 5 的固定列表的布局。
动态列表
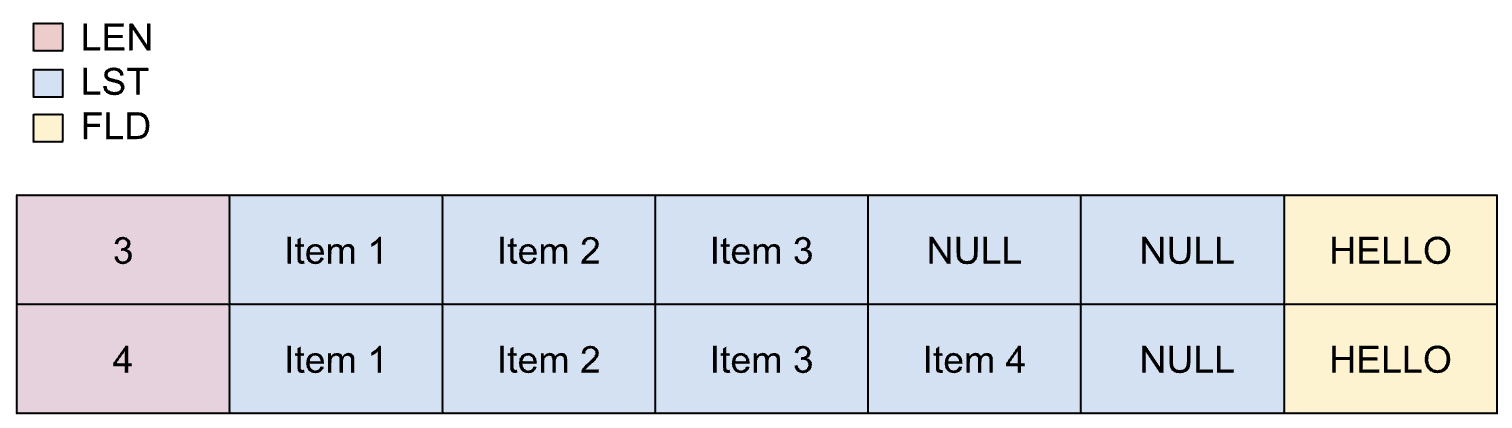
如果预先知道列表中的最大项数,则使用动态列表。不过,实际的商品数量未知,取决于另一个字段。动态列表中的项目大小可变。
动态列表的属性如下:
- 长度字段可以转换为整数,而不会损失精度。
- 长度字段必须在 scope 中。
- 在转码过程中,系统不会强制执行最低商品数量。
在 copybook 中,动态列表的定义如下:
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS 1 TO 5 TIMES
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
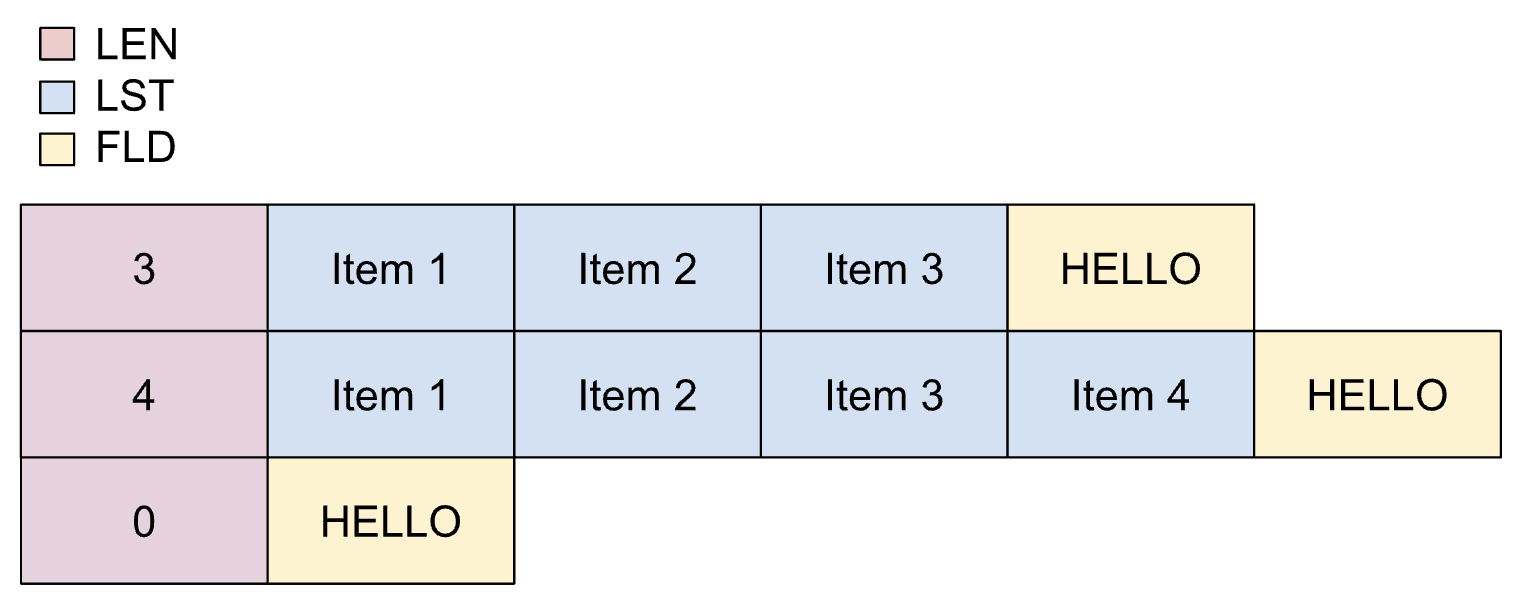
下图显示了动态列表的布局,其中最多包含 5 个项。
打包的动态列表
当列表中的最大项数取决于另一个字段,并且项是打包的,则使用打包的动态列表。
打包动态列表的属性如下:
- 长度字段可以转换为整数,而不会损失精度。
- 长度字段必须在 scope 中。
- 在转码过程中,系统不会强制执行最低商品数量。
在 copybook 中,打包动态列表的定义如下:
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS UNBOUNDED
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
下图显示了打包动态列表的布局。
重定义 (REDEFINE)
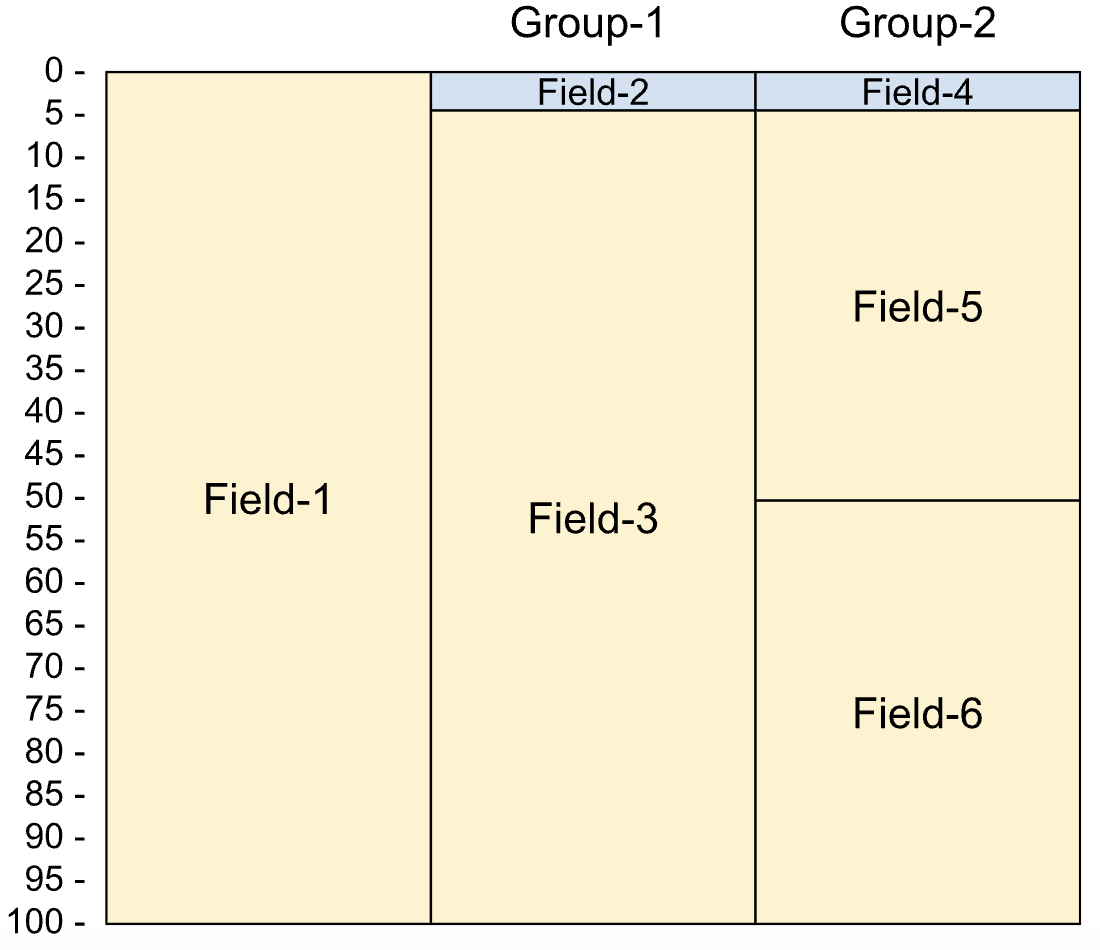
重定义是一项 COBOL 功能,可让同一数据有多种解码可能性。在解码过程中,重新定义会显示为结果表中的附加列,并且数据会被多次解码。
重定义的属性如下:
- 对同一底层数据的重新定义不是同级字段,因此不在彼此的作用域内。
- 重新定义的字段在解码底层字段时解码,而不是在声明时解码。底层字段还决定了重新定义的字段的范围。
- 所有重新定义的字段必须具有相同的大小,并且必须具有固定的大小。这意味着您无法在重新定义的字段中使用可变长度的文本字段和打包的动态列表。
在 copybook 中,重定义定义如下:
01 Rec.
05 Field-1 PIC X(100).
05 Group-1 REDEFINES Field-1.
10 Field-2 PIC 9(5) comp-3.
10 Field-3 PIC X(96).
05 Group-2 REDEFINES Field-1.
10 Field-4 PIC 9(4) comp-4.
10 Field-5 PIC X(50).
10 Field-6 PIC X(46).
下图显示了重新定义的字段的布局。
您可以通过多种方式使用重定义,包括以下最常见的方式:
以两种不同的方式查看相同的数据:这是重新定义的最常见用途。在编码过程中,填充数据的顺序是不确定的,因此您必须确保 BigQuery 中的数据在导出时保持完整性。
示例
01 REC. 02 FULL-NAME PIC X(12). 02 NAME REDEFINES FULL-NAME. 05 FIRST-NAME PIC X(6). 05 LAST-NAME PIC X(6).使用带标记的联合:当您只需要任何记录的一种数据解读(具体取决于某个字段)时,带标记的联合是一种常用的重新定义方式。您可以使用 null 指标将不需要的解读标记为 null。这还可以防止由于 null 指标具有延迟评估而导致它们无法被解析。标记的联合的属性如下:
- 如果定义了多个重新定义,则编码过程会失败。
- 仅实现了相等性检查和非相等性检查。
示例
01 REC. 05 TYPE PIC X(5). 05 DATA PIC X(100). 05 VARIANT-1 REDEFINES DATA. 10 Field-2 PIC 9(4) comp-3. 10 Field-3 PIC X(96). 05 VARIANT-2 REDEFINES DATA. 10 Field-4 PIC 9(4) comp-5. 10 Field-5 PIC X(50). 10 Field-6 PIC X(46).您可以使用以下示例来实现标记的联合:
{ "field_override": [ { "field": "VARIANT-1", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR1" } } }, { "field": "VARIANT-2", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR2" } } } ], "transformations": [ { "field": "DATA", "transformation": { "exclude": {}} } ] }
逻辑类型
为了将数据转码为多种格式或从多种格式转码数据,Mainframe Connector 会将所有数据转换为基于逻辑类型的中间表示形式 (IR)。输入和输出格式定义了如何将数据转换为任何逻辑类型以及如何从任何逻辑类型转换数据。下表列出了 Mainframe Connector 支持的所有逻辑类型。
| 逻辑类型 | 说明 |
|---|---|
| BigDecimal | 表示任意标度和精度的十进制数。 |
| BigInteger | 表示任意大小的整数。 |
| 字节 | 表示大小可变的字节数组。 |
| 日期 | 表示与特定时区无关的日期。 |
| Decimal64 | 表示范围可容纳在任何规模的 64 位有符号整数中的小数。 |
| 双精度型 | 表示 IEEE 浮点运算标准 (IEEE 754) 中所述的双精度浮点数。 |
| 列表 | 表示特定类型的商品列表。该列表可以包含任意数量的项。 |
| 长 | 表示有符号 64 位数字。 |
| 录制 | 表示类型各异的固定字段序列。 |
| 字符串 | 表示与任何特定编码无关的 Unicode 字符字符串。任何有效的 Unicode 代码点都可以表示。不过,某些字符可能无法在所有编码过程中进行编码。逻辑字符串的长度可变。 |
| 时间戳 | 表示与特定时区无关的时间戳。 |
ORC 类型映射
下表提供了 Mainframe Connector 逻辑类型与 ORC 类型之间的映射。
| 逻辑类型 | ORC 类型 |
|---|---|
| BigDecimal | decimal |
| BigInteger | decimal |
| 字节 | 二进制 blob |
| 日期 | 日期 |
| Decimal64 | decimal64 |
| 双精度型 | float64 |
| 列表 | list |
| 长 | 64 位整数 (bigint) |
| 录制 | 结构体 |
| 字符串 | UTF-8 编码的字符串 |
| 时间戳 | 时间戳(不含本地时区) |
BigQuery 类型映射
下表提供了大型主机连接器逻辑类型与 BigQuery 数据类型之间的映射。
| 逻辑类型 | BigQuery 数据类型 | 评论 |
|---|---|---|
| BigDecimal | NUMERIC | |
| BigInteger | NUMERIC | |
| 字节 | BYTES | |
| 日期 | DATE | |
| Decimal64 | NUMERIC | |
| 双精度型 | FLOAT64 | |
| 列表 | ARRAY | 系统不支持嵌套列表和映射列表。 |
| 长 | INT64 | |
| 录制 | STRUCT | 如果联合只有一个变体,则会转换为可为 NULL 的字段。
否则,联合会转换为包含可为 Null 的字段列表的记录。
可为 Null 的字段具有 field_0、field_1 等后缀。在读取数据时,系统仅向其中一个字段分配值。 |
| 字符串 | STRING | |
| 时间戳 | TIMESTAMP |
字段范围
如果某个字段属于以下任一情况,则会被视为另一个字段的有效范围:
- 在需要它的字段之前定义的同级字段。
- 父记录中在需要该字段的字段之前定义的字段。