Mainframe Connector は、qsam コマンドを使用して、キューに入れられた順次アクセス方式(QSAM)フラット ファイルを Google Cloud 互換形式にコード変換します。qsam コマンドは、次のトランスコード オペレーションを実行します。
qsam decodeコマンドは、メインフレーム データを Google Cloudにデコードします。qsam encodeコマンドは、 Google Cloud データをメインフレームにエンコードします。
これらのオペレーションは対称変換を実行します。つまり、同じデータを Google Cloudとの間で移動します。COBOL データ構造定義を使用して、コピーブック ファイルで QSAM ファイルの構造を定義できます。Mainframe Connector トランスコーダ構成ファイルを使用して、高度な変換を定義することもできます。次の図は、これらのオペレーションの詳細を示しています。

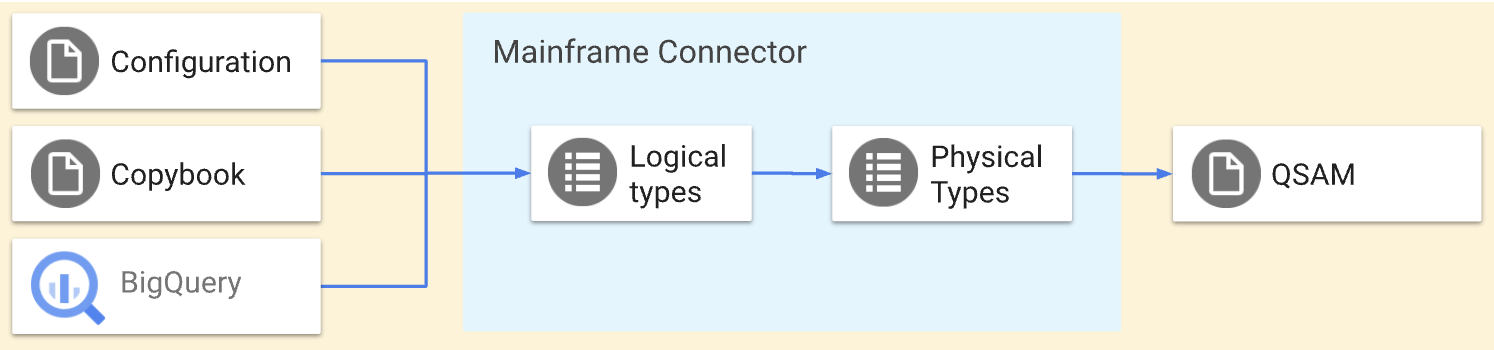
このページでは、qsam decode コマンドと qsam encode コマンドを使用したコード変換プロセス、メインフレーム データの物理型と論理型、Optimized Row Columnar(ORC)と BigQuery の型のマッピングの概要について説明します。
物理タイプ
物理タイプは、フィールド データがディスクにどのようにレイアウトされるかを定義します。物理型は Mainframe Connector の論理型に変換され、データベース型(ORC または BigQuery)にマッピングできます。
英数字フィールド
英数字フィールドは、英数字の文字列を処理するために使用されます。データは一連の文字として扱われ、特定のエンコード(拡張バイナリ コード 10 進数交換コード(EBCDIC)など)の文字列として保存されます。英数字フィールドのエンコードまたはデコード中にエラーが発生しても、トランスコード処理は終了しません。代わりに、エンコードの SUB 文字がエラーが発生した場所に配置され、トランスコード プロセスが続行されます。
| 画像記号 | 画像属性 | 論理型 |
|---|---|---|
| A、B、G、N、U、X、9 | DISPLAY、DISPLAY-1、NATIONAL、UTF-8 | 文字列 |
例
01 REC 02 STR PIC X(10) 02 NATIONAL PIC N(10) 02 UTF8 PIC U(1) USAGE UTF-8
エンコード形式
英数字フィールドは次のようにエンコードされます。
- X フィールドのデフォルトは EBCDIC エンコード
- National(N)フィールドのデフォルトは Unicode Transformation Format 16-bit(UTF-16 BE)エンコードです。
- UTF8 フィールドのデフォルトは Unicode Transformation Format-8(UTF-8)エンコード
Mainframe Connector は、ほとんどのシングルバイト文字セット(SBCS)、ダブルバイト文字セット(DBCS)エンコードをサポートしています。必要に応じて、独自のカスタム SBCS エンコードを定義することもできます。
バイナリ フィールド(計算)
バイナリ フィールドは、符号付きまたは符号なしのビッグ エンディアン整数として保存されます。Mainframe Connector は、バイナリ フィールドを常に論理的に符号付き 64 ビット整数として保存します。したがって、符号なし long 型の入力では下位 63 ビットのみを使用する必要があります。そうしないと、トランスコード プロセスが失敗します。
| 画像記号 | 画像属性 | 論理型 |
|---|---|---|
| S、9 | COMP、コンピューティング | Long(符号付き 64 ビット整数) |
例
01 REC 02 INT PIC S9(8) COMP
16 進浮動小数点フィールド(COMP-1、COMP-2)
16 進数浮動小数点(HFP)フィールドは完全にサポートされています。Mainframe Connector は、HFP フィールドに単精度形式と倍精度形式の両方を使用します。
| 画像記号 | 画像属性 | 論理型 |
|---|---|---|
| COMP-1、COMP-2 | Double(64 ビット符号付き浮動小数点) |
例
01 REC 03 HFP-SINGLE COMP-1. 03 HFP-DOUBLE COMP-2.
パック 10 進数フィールド(COMP-3)
パック 10 進数フィールドは完全にサポートされています。トランスコーディング プロセス中に、Mainframe Connector は指定された精度とスケールに基づいて、最もパフォーマンスの高い論理型を選択します。
| 画像記号 | 画像属性 | 論理型 |
|---|---|---|
| S、9、V | COMP-3 | Long(64 ビット符号付き整数)、BigInteger、Decimal64、BigDecimal |
例
01 REC 02 DEC PIC S9(2)V9(8) COMP-3
ゾーン 10 進数フィールド(DISPLAY)
ゾーン付き 10 進数フィールドは完全にサポートされています。トランスコーディング プロセス中に、Mainframe Connector は指定された精度とスケールに基づいて、最もパフォーマンスの高い論理型を選択します。
| 画像記号 | 画像属性 | 論理型 |
|---|---|---|
| S、9、V | ディスプレイ | Long(64 ビット符号付き整数)、BigInteger、Decimal64、BigDecimal |
例
01 REC 02 DEC PIC S9(2)V9(8) DISPLAY
リスト(OCCURS)
リストは、同じ型の要素を順序立てて集めたものです。Mainframe Connector は、次のタイプのリストをサポートしています。
固定リスト
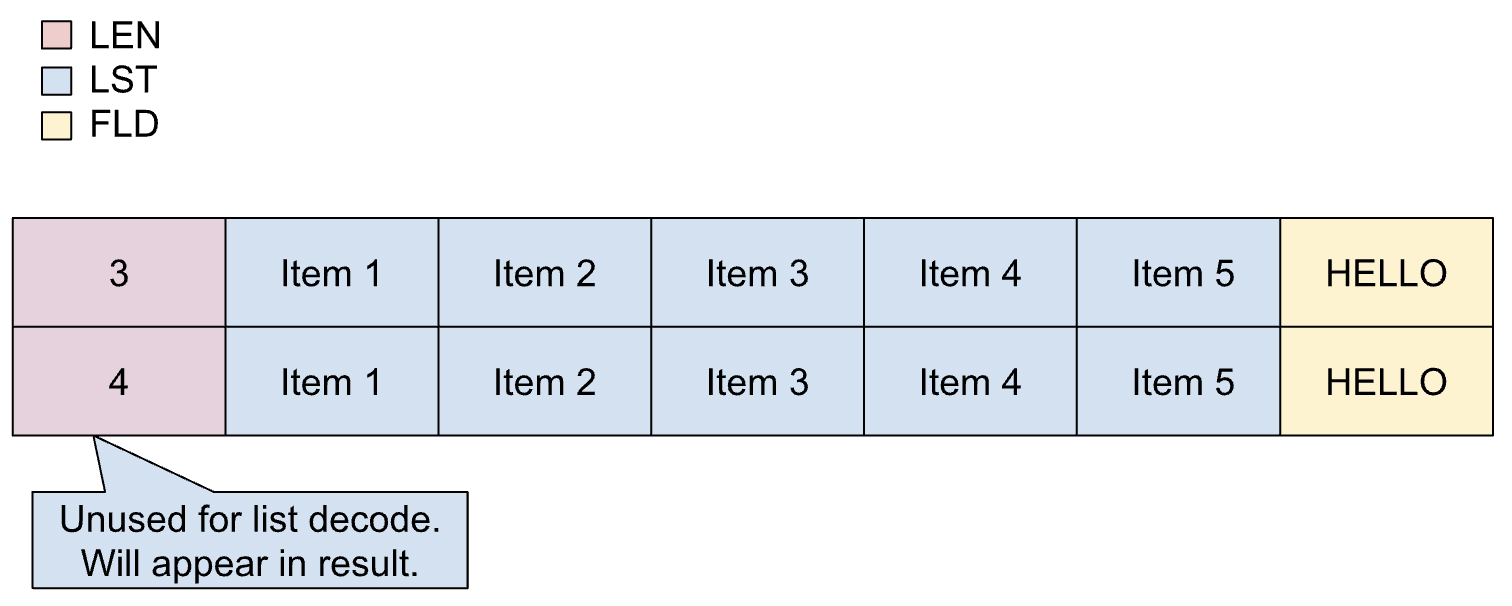
固定リストは、リストの一部となるアイテムの正確な数(アイテム数)が事前にわかっており、その数が常に同じである場合に使用されます。固定リストのアイテムは可変サイズにできます。
固定リストは、コピーブックで次のように定義されます。
01 REC.
02 LIST OCCURS 5 TIMES PIC X(1).
02 FLD PIC X(5).
次の図は、項目数が 5 の固定リストのレイアウトを示しています。
動的リスト
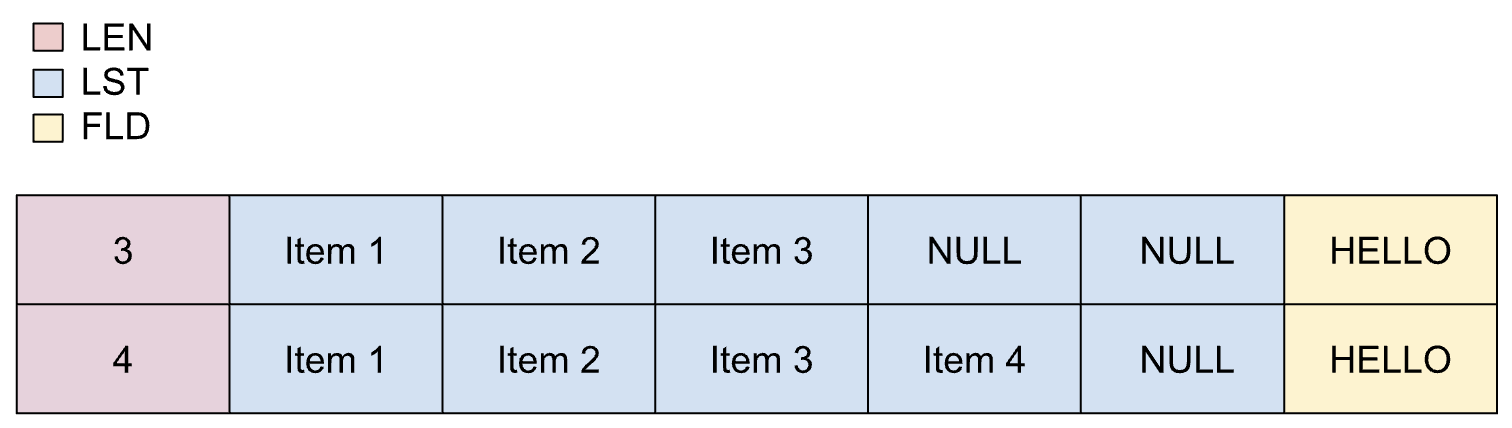
動的リストは、リストの一部となるアイテムの最大数が事前にわかっている場合に使用されます。ただし、実際のアイテム数は不明で、別のフィールドに依存します。動的リストのアイテムは可変サイズにできます。
動的リストのプロパティは次のとおりです。
- 長さフィールドは、精度を失うことなく整数に変換できます。
- 長さフィールドは scope 内にある必要があります。
- トランスコード プロセスでは、最小アイテム数は適用されません。
動的リストは、コピーブックで次のように定義されます。
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS 1 TO 5 TIMES
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
次の図は、アイテムの最大数が 5 の動的リストのレイアウトを示しています。
パックされた動的リスト
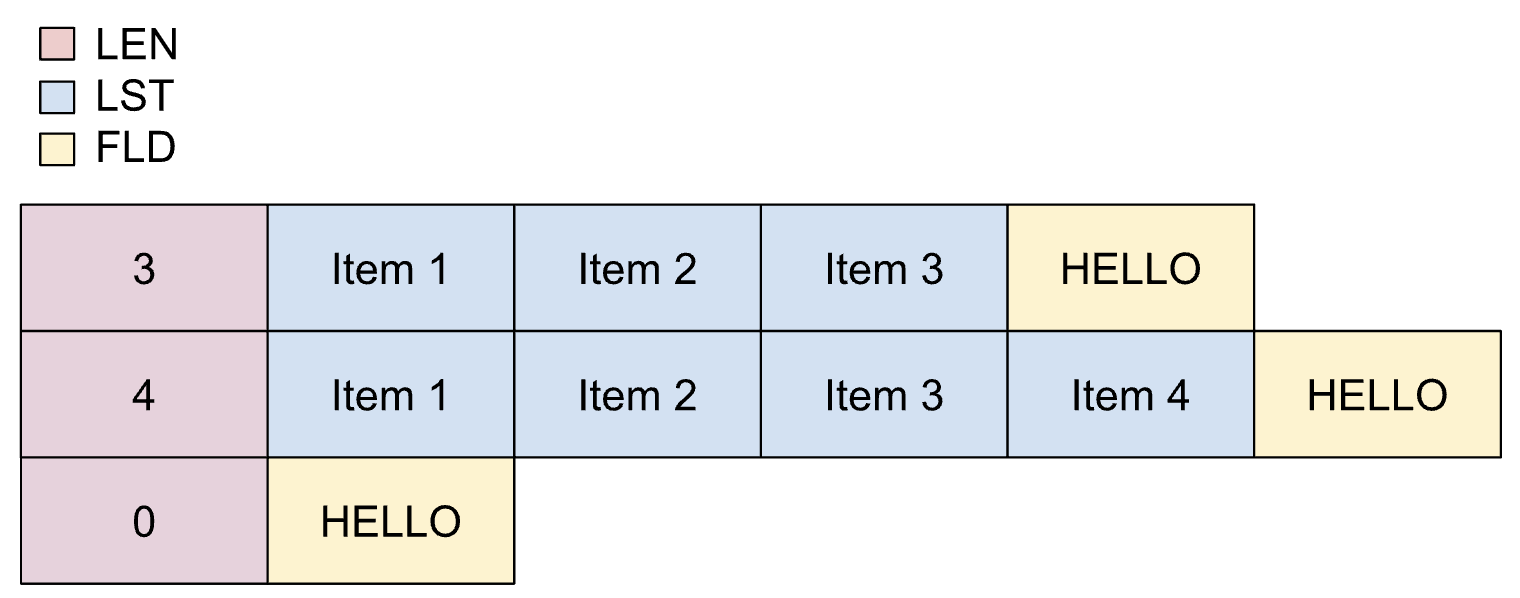
パックされた動的リストは、リストの一部となるアイテムの最大数が別のフィールドに依存し、アイテムがパックされている場合に使用されます。
パックされた動的リストのプロパティは次のとおりです。
- 長さフィールドは、精度を失うことなく整数に変換できます。
- 長さフィールドは scope 内にある必要があります。
- トランスコード プロセスでは、最小アイテム数は適用されません。
パックされた動的リストは、コピーブックで次のように定義されます。
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS UNBOUNDED
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
次の図は、パックされた動的リストのレイアウトを示しています。
再定義(REDEFINES)
再定義は、同じデータに複数のデコードの可能性がある COBOL 機能です。デコード プロセスでは、再定義は結果のテーブルに追加の列として表示され、データは複数回デコードされます。
再定義のプロパティは次のとおりです。
- 同じ基盤となるデータに対する再定義は兄弟フィールドではないため、互いのスコープ内にありません。
- 再定義されたフィールドは、宣言されたときではなく、基になるフィールドがデコードされたときにデコードされます。基になるフィールドは、再定義されたフィールドのスコープも決定します。
- 再定義されたすべてのフィールドは同じサイズで、固定サイズである必要があります。つまり、再定義されたフィールドでは、可変長のテキスト フィールドとパックされた動的リストを使用できません。
再定義は、コピーブックで次のように定義されます。
01 Rec.
05 Field-1 PIC X(100).
05 Group-1 REDEFINES Field-1.
10 Field-2 PIC 9(5) comp-3.
10 Field-3 PIC X(96).
05 Group-2 REDEFINES Field-1.
10 Field-4 PIC 9(4) comp-4.
10 Field-5 PIC X(50).
10 Field-6 PIC X(46).
次の図は、再定義されたフィールドのレイアウトを示しています。

再定義は、次のような一般的な方法を含め、さまざまな方法で使用できます。
同じデータを 2 つの異なる方法で表示する: これは、再定義が使用される最も一般的な方法です。エンコード プロセスでは、データが入力される順序は未定義であるため、エクスポート時に BigQuery のデータの整合性が維持されるようにする必要があります。
例
01 REC. 02 FULL-NAME PIC X(12). 02 NAME REDEFINES FULL-NAME. 05 FIRST-NAME PIC X(6). 05 LAST-NAME PIC X(6).タグ付き共用体を使用する: タグ付き共用体は、フィールドに応じて、任意のレコードのデータの解釈の 1 つだけが必要な場合に、再定義を使用する一般的な方法です。null インジケーターを使用すると、不要な解釈を null としてマークできます。また、null インジケーターの遅延評価により、解析も行われなくなります。タグ付き共用体のプロパティは次のとおりです。
- 複数の再定義が定義されている場合、エンコード プロセスは失敗します。
- 等価性チェックと非等価性チェックのみが実装されています。
例
01 REC. 05 TYPE PIC X(5). 05 DATA PIC X(100). 05 VARIANT-1 REDEFINES DATA. 10 Field-2 PIC 9(4) comp-3. 10 Field-3 PIC X(96). 05 VARIANT-2 REDEFINES DATA. 10 Field-4 PIC 9(4) comp-5. 10 Field-5 PIC X(50). 10 Field-6 PIC X(46).次の例を使用して、タグ付き共用体を実装できます。
{ "field_override": [ { "field": "VARIANT-1", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR1" } } }, { "field": "VARIANT-2", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR2" } } } ], "transformations": [ { "field": "DATA", "transformation": { "exclude": {}} } ] }
論理型
複数の形式間でデータをトランスコードするために、Mainframe Connector はすべてのデータを論理型に基づく中間表現(IR)に変換します。入力形式と出力形式は、データが任意の論理型との間でどのように変換されるかを定義します。次の表に、Mainframe Connector でサポートされているすべての論理型を示します。
| 論理型 | 説明 |
|---|---|
| BigDecimal | 任意のスケールと精度の 10 進数を表します。 |
| BigInteger | 任意のサイズの整数を表します。 |
| バイト | 可変サイズのバイト配列を表します。 |
| 日付 | 特定のタイムゾーンに依存しない日付を表します。 |
| Decimal64 | 任意のスケールの 64 ビット符号付き整数に収まる範囲の 10 進数を表します。 |
| Double | IEEE Standard for Floating-Point Arithmetic(IEEE 754)で説明されている倍精度浮動小数点数を表します。 |
| リスト | 特定の型のアイテムのリストを表します。リストには任意の数の項目を含めることができます。 |
| 長い | 符号付き 64 ビット数値を表します。 |
| 記録 | さまざまな型のフィールドの固定されたシリーズを表します。 |
| 文字列 | 特定のエンコードに関連しない Unicode 文字の文字列を表します。有効な Unicode コードポイントはすべて表現できます。ただし、一部の文字はすべてのエンコード プロセスでエンコードできるとは限りません。論理文字列は可変長です。 |
| タイムスタンプ | 特定のタイムゾーンに依存しないタイムスタンプを表します。 |
ORC 型のマッピング
次の表に、Mainframe Connector の論理型と ORC 型のマッピングを示します。
| 論理型 | ORC タイプ |
|---|---|
| BigDecimal | decimal |
| BigInteger | decimal |
| バイト | バイナリ blob |
| 日付 | 日付 |
| Decimal64 | decimal64 |
| Double | float64 |
| リスト | list |
| 長い | 64 ビット整数(bigint) |
| 記録 | 構造体 |
| 文字列 | UTF-8 でエンコードされた文字列 |
| タイムスタンプ | タイムスタンプ(ローカル タイムゾーンなし) |
BigQuery の型マッピング
次の表に、Mainframe Connector の論理型と BigQuery のデータ型のマッピングを示します。
| 論理型 | BigQuery のデータ型 | コメント |
|---|---|---|
| BigDecimal | NUMERIC | |
| BigInteger | NUMERIC | |
| バイト | BYTES | |
| 日付 | DATE | |
| Decimal64 | NUMERIC | |
| Double | FLOAT64 | |
| リスト | ARRAY | ネストされたリストとマップのリストはサポートされていません。 |
| 長い | INT64 | |
| 記録 | STRUCT | union に 1 つのバリアントしかない場合は、NULLABLE フィールドに変換されます。それ以外の場合は、union は NULLABLE フィールドのリストを持つ RECORD に変換されます。NULLABLE フィールドには、field_0、field_1 などの接尾辞が付きます。データを読み取るときに、このようなフィールドの 1 つのみに値が割り当てられます。 |
| 文字列 | STRING | |
| タイムスタンプ | TIMESTAMP |
フィールド スコープ
フィールドが別のフィールドのスコープ内にあると見なされるのは、次のいずれかの場合です。
- それを必要とするフィールドの前に定義されている兄弟フィールド。
- 親レコード内の、それを必要とするフィールドの前に定義されているフィールド。