Une fois que vous avez sécurisé et configuré votre base de données, vous pouvez la connecter à Looker.
Vous pouvez créer une connexion à une base de données dans Looker sur la page Connecter votre base de données à Looker. Il existe deux façons d'ouvrir la page Connecter votre base de données à Looker :
- Sélectionnez Connexions dans la section Base de données du panneau Admin. Sur la page Connexions, cliquez sur le bouton Ajouter une connexion.
- Cliquez sur le bouton Créer dans le panneau de navigation de gauche, puis sélectionnez l'élément de menu Connexion.
Pour en savoir plus sur l'application d'attributs utilisateur aux paramètres de connexion, consultez la section Connexions de la page de documentation Attributs utilisateur.
Cette page décrit les champs courants que Looker affiche sur la page Connecter votre base de données à Looker. Les champs exacts affichés par la page dépendent de la configuration de votre dialecte.
Cliquez ici pour afficher les liens vers les instructions spécifiques aux dialectes dans la documentation Looker.
- Actian Avalanche
- AlloyDB pour PostgreSQL
- Amazon Aurora PostgreSQL
- Amazon Athena
- Amazon Aurora MySQL
- Amazon RDS pour MySQL
- Amazon RDS pour PostgreSQL
- Amazon Redshift
- Apache Druid
- Apache Hive 2.3+ et 3.1.2+
- Apache Spark 3 et versions ultérieures
- ClickHouse
- Cloudera Impala 3.1 ou version ultérieure
- Databricks
- DataVirtuality
- Denodo
- Dremio
- Exasol
- Google BigQuery Legacy SQL
- SQL standard Google BigQuery
- Google Cloud SQL pour MySQL
- Google Cloud SQL pour PostgreSQL
- Google Spanner
- Greenplum
- IBM DB2 sur AS400
- IBM DB2 sur LUW
- MariaDB
- Microsoft Azure Synapse Analytics
- Microsoft Azure SQL Database
- Microsoft Azure PostgreSQL
- Microsoft SQL Server (MSSQL)
- MongoDB Connector for BI
- MySQL
- Oracle
- Oracle ADWC
- PostgreSQL
- PrestoDB
- SAP HANA
- SingleStore (anciennement MemSQL)
- Snowflake
- Teradata
- Trino
- Vector
- Vertica
Une fois que vous avez saisi les paramètres de connexion à votre base de données, vous pouvez sélectionner le bouton Tester sur la page Connecter votre base de données à Looker pour tester la connexion et vous assurer qu'elle est correctement configurée. Cliquez sur Tester pour vérifier que la connexion fonctionne. Pour obtenir des informations sur le dépannage, consultez la page de documentation Tester la connectivité à la base de données. Si Looker affiche Peut se connecter, appuyez sur Connecter pour créer la connexion. Votre connexion de base de données est ensuite ajoutée à la liste de la page d'administration Connexions de Looker.
Paramètres généraux
Nom
Le nom de la connexion tel que vous souhaitez y faire référence. Vous avez besoin de ce nom de connexion à la base de données pour l'utiliser dans le paramètre connection de votre modèle LookML. Le nom de la connexion à la base de données permet également d'identifier la connexion sur la page Connexions Admin de Looker. N'utilisez pas le nom d'un dossier pour ce paramètre. Cette valeur ne doit pas nécessairement correspondre à un élément de votre base de données. Name est une étiquette qui identifie cette connexion dans l'interface utilisateur Looker.
Champ d'application de la connexion
Indiquez si la connexion doit pouvoir être utilisée avec tous les projets ou avec un seul :
- Tous les projets : tous les projets LookML de l'instance peuvent avoir accès à la connexion. Le nom de la connexion peut donc être spécifié dans le paramètre
connectiondes fichiers de modèle de ce projet. - Projet sélectionné : un seul projet LookML sur l'instance peut avoir accès à la connexion. Lorsque vous sélectionnez cette option, l'écran "Connexion" affiche un menu déroulant des projets sur l'instance. Sélectionnez le projet qui peut accéder à cette connexion.
Utilisez cette option avec les autorisations suivantes pour déléguer la gestion des connexions et la configuration des modèles :
Dialecte
Dialecte SQL correspondant à votre connexion. Il est important de choisir la valeur appropriée afin que les options de connexion pertinentes vous soient présentées et que Looker puisse convertir correctement votre LookML en langage SQL.
ID du projet de facturation
Pour les connexions Google BigQuery uniquement, l'ID du projet de facturation correspond à l'ID du projet Google Cloud .
Hôte
Nom d'hôte de votre base de données que Looker doit utiliser pour se connecter à l'hôte de la base de données.
Si vous avez collaboré avec un analyste Looker pour configurer un tunnel SSH vers votre base de données, saisissez "localhost" dans le champ Hôte.
Port
Port de base de données que Looker doit utiliser pour se connecter à l'hôte de la base de données.
Si vous avez travaillé avec un analyste Looker pour configurer un tunnel SSH vers votre base de données, saisissez dans le champ Port le numéro de port qui redirige vers votre base de données. Votre analyste Looker devrait vous l'avoir fourni.
Base de données
Nom de la base de données de votre hôte. Par exemple, vous pouvez avoir un nom d'hôte my-instance.us-east-1.redshift.amazonaws.com sur lequel se trouve une base de données appelée sales_info. Vous devez saisir sales_info dans ce champ. Si vous avez plusieurs bases de données sur le même hôte, vous devrez peut-être créer plusieurs connexions pour les utiliser (à l'exception des bases de données MySQL, dans lesquelles le terme base de données a une signification légèrement différente de celle de la plupart des dialectes SQL).
Schéma
Le schéma par défaut que Looker utilise lorsqu'aucun schéma n'est indiqué. Cela s'applique lorsque vous utilisez SQL Runner, au cours de la génération d'un projet LookML et que vous interrogez des tables.
Authentification
Pour les connexions Google BigQuery, Snowflake, Trino et Databricks, sélectionnez le type d'authentification que vous souhaitez que Looker utilise pour accéder à votre base de données :
- Pour les connexions Google BigQuery, vous pouvez configurer OAuth ou un compte de service que Looker utilisera pour s'authentifier auprès de votre base de données.
- Pour les connexions à Snowflake, Trino et Databricks, vous pouvez configurer OAuth ou un compte de base de données que Looker utilisera pour s'authentifier auprès de votre base de données.
Lorsque vous utilisez OAuth, vos utilisateurs doivent se connecter à votre base de données pour émettre des requêtes depuis Looker. Pour en savoir plus sur la configuration d'OAuth sur une connexion à Looker, consultez les procédures de connexion à Google BigQuery, Snowflake, Trino ou Databricks.
Nom d'utilisateur
Nom d'utilisateur d'un compte utilisateur de votre base de données que Looker peut utiliser pour se connecter à votre base de données.
Mot de passe
Mot de passe d'un compte utilisateur de votre base de données que Looker peut utiliser pour se connecter à votre base de données.
Paramètres facultatifs
Serveur SSH
L'option Serveur SSH n'est disponible que si l'instance est déployée sur l'infrastructure Kubernetes et si l'ajout d'informations de configuration du serveur SSH à votre instance Looker a été activé. Si cette option n'est pas activée sur votre instance Looker et que vous souhaitez l'activer, contactez un spécialiste des ventes ou ouvrez une demande d'assistance. Google Cloud
Le serveur SSH choisit automatiquement le port localhost pour vous et il est impossible de spécifier le port localhost. Si vous devez créer une connexion SSH qui vous oblige à spécifier un port localhost, ouvrez une demande d'assistance.
Pour vous connecter à votre base de données à l'aide d'un tunnel SSH, activez le bouton bascule et sélectionnez une configuration de serveur SSH dans la liste déroulante.
Port local
Par défaut, Looker sélectionne automatiquement un port local disponible pour le tunnel SSH. Pour choisir manuellement un port local, sélectionnez Saisie manuelle et saisissez un numéro de port dans le champ Port local personnalisé. Assurez-vous que le port local est disponible sur votre instance.
Tables dérivées persistantes (PDT)
Activer les PDT
Activez l'option Activer les PDT pour activer les tables dérivées persistantes. Lorsque les PDT sont activées, la fenêtre Connexion affiche des champs PDT supplémentaires et la section Remplacements de PDT. Looker n'affiche l'option Activer les PDT que si le dialecte de base de données prend en charge l'utilisation des PDT.
Remarques à propos des PDT :
- Les PDT ne sont pas compatibles avec les connexions Snowflake qui utilisent OAuth.
- La désactivation des PDT dans une connexion n'entraîne pas la désactivation des groupes de données associés à vos PDT. Même si vous désactivez les PDT, les groupes de données existants continueront d'exécuter leurs requêtes
sql_triggersur la base de données. Si vous souhaitez empêcher un groupe de données d'exécuter sa requêtesql_triggersur votre base de données, vous devez supprimer ou commenter le paramètredatagroupde votre projet LookML. Vous pouvez également modifier le paramètre Planification du suivi des tables PDT et des groupes de données pour la connexion afin que Looker vérifie les tables PDT et les groupes de données très rarement, voire jamais. - Pour les connexions Snowflake, Looker définit la valeur du paramètre
AUTOCOMMITsurTRUE(valeur par défaut de Snowflake).AUTOCOMMITest nécessaire pour les commandes SQL exécutées par Looker afin de gérer son système d'enregistrement des PDT.
Base de données temporaire
Même s'il s'agit d'une base de données temporaire étiquetée, vous devez saisir le nom de la base de données ou du schéma (selon votre dialecte SQL) que Looker doit utiliser pour créer des tables dérivées persistantes. Vous devez configurer cette base de données ou ce schéma à l'avance en utilisant les autorisations en écriture appropriées. Sur la page de documentation Instructions pour la configuration de la base de données, sélectionnez le dialecte de votre base de données afin d'afficher les instructions associées à ce dialecte.
Chaque connexion doit avoir sa propre base de données temporaire ou son propre schéma. Ces éléments ne peuvent pas être partagés entre les connexions.
Nombre maximum de connexions de PDT builder
Le paramètre Nombre maximal de connexions du générateur de PDT vous permet de spécifier le nombre de tables simultanées que le régénérateur Looker peut lancer sur votre connexion à la base de données. Le paramètre Nombre maximal de connexions du générateur de PDT s'applique uniquement aux types de tables pour lesquels le régénérateur Looker lance des reconstructions :
- Tables persistantes à déclenchement (tables dérivées persistantes et tables agrégées qui utilisent la stratégie de persistance
datagroup_triggerousql_trigger_value). - Tables persistantes qui utilisent la stratégie
persist_for, mais uniquement lorsque la tablepersist_forfait partie d'une cascade de tables dérivées dont dépend une table qui utilise la stratégie de persistancedatagroup_triggerousql_trigger_value. Dans ce cas, le régénérateur Looker recréera une tablepersist_for, étant donné que la table est nécessaire pour recréer une autre table dans la cascade. Sinon, le régénérateur ne lance pas de créations de tablespersist_for.
Le paramètre Nombre maximal de connexions du générateur de PDT est défini par défaut sur 1, mais peut être augmenté jusqu'à 10. Toutefois, la valeur ne peut pas être supérieure à celle définie dans le champ Nombre maximal de connexions par nœud ni à la valeur per-user-query-limit définie dans les options de démarrage de Looker.
Vous devez configurer cette valeur attentivement. Si cette valeur est trop élevée, vous risquez de submerger votre base de données. Si cette valeur est faible, les tables PDT ou agrégées de grande taille peuvent retarder la création d'autres tables persistantes ou ralentir les autres requêtes sur la connexion. Les bases de données qui prennent en charge les environnements multi-tenant, telles que BigQuery, Snowflake et Redshift, peuvent gagner en performances lors de la gestion de créations de requêtes en parallèle.
Si vous souhaitez augmenter le paramètre Nombre maximal de connexions du générateur de PDT, une bonne règle consiste à l'augmenter d'une unité. Si un comportement inattendu se produit, rétablissez la valeur par défaut 1. Sinon, si les performances des requêtes ne sont pas affectées, vous pouvez continuer à l'augmenter progressivement de 1 et vérifier les performances à chaque incrément avant d'augmenter davantage le paramètre.
Remarques à propos du paramètre Nombre maximal de connexions du générateur de PDT :
- Le paramètre Nombre maximal de connexions du générateur de PDT ne s'applique qu'aux connexions requises pour la reconstruction des tables, et non à celles nécessaires pour les vérifications des déclencheurs. Un contrôle de déclenchement est une requête permettant de savoir si la stratégie de persistance de la table est déclenchée. Ces requêtes de contrôle de déclenchement étant toujours exécutées successivement, le paramètre Nombre maximal de connexions du générateur de PDT ne s'applique pas.
- Dans une instance Looker en cluster, le régénérateur s'exécute uniquement sur le nœud principal. Le paramètre Nombre maximal de connexions du générateur de PDT s'applique uniquement au nœud principal et, par conséquent, définit la limite pour la totalité du cluster.
- Le paramètre Nombre maximal de connexions du générateur de PDT ne s'applique pas aux types de tables suivants. Ces types de tables sont créés les uns après les autres :
- Tables persistantes via le paramètre
persist_for(sauf si la table dépend de tables utilisant les stratégiesdatagroup_triggerousql_trigger_value). - Tables en mode Développement
- Tables recréées avec l'option Recréer les tables dérivées et exécuter.
- Tables lorsque l'une dépend d'une autre dans une cascade de dépendances. Une table ne peut pas être créée en même temps qu'une table dont elle dépend. Par exemple, si
table_Bdépend detable_A,table_Adoit terminer sa recompilation avant quetable_Bpuisse commencer à se recompiler.
- Tables persistantes via le paramètre
Calendrier de maintenance des groupes de données et des tables dérivées persistantes
Le régénérateur Looker vérifie les groupes de données et les tables persistantes (à la fois les tables agrégées et les tables dérivées persistantes) basées sur sql_trigger_value. Sur la base de ces vérifications, le régénérateur Looker régénère ou supprime les tables persistantes du schéma scratch de votre base de données.
La valeur Calendrier de maintenance des groupes de données et des tables dérivées persistantes définit l'intervalle cron pour le régénérateur Looker. Le régénérateur Looker lance un cycle de régénération pour vérifier les groupes de données et les tables persistantes à l'intervalle cron. Si un cycle de régénération Looker est toujours en cours au prochain intervalle cron, le régénérateur Looker terminera le cycle de régénération en cours, puis attendra l'intervalle cron suivant pour commencer le prochain cycle de régénération.
Le paramètre Calendrier de maintenance des groupes de données et des tables dérivées persistantes accepte une expression cron. La valeur par défaut est */5 * * * *, ce qui signifie que le cycle du régénérateur Looker lancera un cycle à l'intervalle de cinq minutes, si le cycle du régénérateur précédent est terminé. Si le cycle de régénération précédent n'est pas terminé, le régénérateur Looker s'initialise à l'intervalle de cinq minutes suivant la fin de son cycle.
La valeur par défaut de cinq minutes correspond également à l'intervalle le plus fréquent accepté pour le calendrier de maintenance des groupes de données et des tables dérivées persistantes. Looker n'impose pas d'intervalle maximal pour le planning de maintenance des groupes de données et des PDT. Vous pouvez donc étendre l'intervalle entre les cycles de régénération Looker aussi longtemps que le permet une expression cron. Gardez à l'esprit que des cycles de régénération Looker plus longs peuvent avoir un impact négatif sur la fraîcheur des données dans votre cache et vos tables persistantes.
Une fois que le régénérateur Looker a effectué toutes les vérifications et régénérations de PDT au cours d'un cycle, il attend le prochain intervalle cron pour lancer le cycle suivant. Si vous avez des tables PDT de grande taille, vous pouvez avoir de longues périodes entre les cycles de régénération de Looker. D'autres facteurs peuvent affecter le temps de régénération de vos tables, comme décrit dans la section Points importants à prendre en compte pour implémenter des tables persistantes de la page Tables dérivées dans Looker.
Si votre base de données n'est pas active 24h/24 et 7j/7, vous souhaiterez peut-être limiter les vérifications aux moments d'activité de votre base de données. Voici quelques expressions cron supplémentaires :
Expression cron |
Définition |
|---|---|
*/5 8-17 * * MON-FRI |
Vérifier les groupes de données et les tables PDT toutes les 5 minutes pendant les heures de travail, du lundi au vendredi |
*/5 8-17 * * * |
Vérifier les groupes de données et les tables PDT toutes les 5 minutes pendant les heures de travail, au quotidien |
0 8-17 * * MON-FRI |
Vérifier les groupes de données et les tables PDT toutes les heures pendant les heures de travail, du lundi au vendredi |
1 3 * * * |
Vérifier les groupes de données et les tables PDT tous les jours à 3 h 01 |
Voici quelques points à noter lorsque vous créez une expression cron :
- Looker utilise parse-cron v0.1.3, qui n'est pas compatible avec
?dans les expressionscron. - L'expression
cronutilise le fuseau horaire de l'application Looker pour déterminer quand les vérifications sont effectuées. - Si les tables PDT ne sont pas créées, rétablissez la valeur par défaut de la chaîne cron qui est
*/5 * * * *.
Voici quelques ressources pour vous aider à créer des chaînes cron :
- https://crontab.guru : pour vous aider à modifier et à tester des chaînes
cron. - http://www.crontab-generator.org : sélectionnez les paramètres temporels, et le générateur crée la chaîne
croncorrespondante.
Relancer les générations de tables dérivées persistantes en échec
Le bouton Relancer les générations de PDT ayant échoué permet de configurer la façon dont le régénérateur Looker tente de régénérer les tables persistantes à déclenchement qui ont échoué lors du cycle de régénération précédent. Le régénérateur Looker est le processus qui régénère les tables persistantes déclenchées (tables PDT et tables agrégées) selon l'intervalle configuré dans le paramètre de connexion Planification du suivi des tables PDT et des groupes de données. Lorsque le bouton Relancer les générations de tables dérivées persistantes en échec est activé, le régénérateur Looker tente de régénérer une table PDT dont la génération a échoué lors du cycle de régénération précédent, même si la condition de déclenchement de la table PDT n'est pas remplie. Lorsque ce paramètre est désactivé, le régénérateur Looker tentera de régénérer une table PDT dont la génération a échoué uniquement lorsque la condition de déclenchement de la table PDT est satisfaite. L'option Relancer les générations de PDT en échec est désactivée par défaut.
Pour en savoir plus sur le régénérateur Looker, consultez la page de documentation Tables dérivées dans Looker.
Contrôle des tables dérivées persistantes via l'API
Le bouton Contrôle des tables dérivées persistantes via l'API détermine si les appels d'API start_pdt_build, check_pdt_build et stop_pdt_build peuvent être utilisés pour cette connexion. Lorsque le bouton Commande API PDT est désactivé, ces appels d'API échouent lorsqu'ils font référence aux PDT sur cette connexion. L'option Contrôle des tables dérivées persistantes via l'API est désactivée par défaut.
Remplacements pour les PDT
Si votre base de données est compatible avec les tables dérivées persistantes et que vous avez activé le bouton Activer les PDT dans les paramètres de connexion, Looker affiche la section Remplacements de PDT. Dans la section Remplacements de PDT, vous pouvez saisir des paramètres JDBC distincts (hôte, port, base de données, nom d'utilisateur, mot de passe, schéma, paramètres supplémentaires et instructions post-connexion) qui sont spécifiques aux processus de PDT. Cette possibilité est précieuse pour plusieurs raisons :
- En créant un utilisateur de base de données distinct pour les processus PDT, vous pouvez utiliser les PDT dans votre projet Looker, même si vous attribuez des attributs utilisateur à vos identifiants de connexion à la base de données ou si vous utilisez OAuth pour votre connexion à la base de données.
- Les processus PDT peuvent s'authentifier par l'intermédiaire d'un utilisateur de base de données distinct dont la priorité est plus élevée. La base de données peut ainsi placer les jobs PDT en priorité au détriment des requêtes de moindre importance des utilisateurs.
- L'accès en écriture peut être révoqué pour la connexion standard à la base de données Looker, et être octroyé seulement à un utilisateur spécifique que les processus PDT utiliseront pour s'authentifier. Il s'agit d'une meilleure stratégie de sécurité pour la plupart des organisations.
- Pour les bases de données telles que Snowflake, les processus PDT peuvent être acheminés vers du matériel plus puissant qui n'est pas partagé avec le reste des utilisateurs Looker. Les tables PDT peuvent ainsi être créées rapidement en évitant les coûts inhérents à l'exécution d'un matériel onéreux à temps plein.
Par exemple, la configuration suivante illustre une connexion dans laquelle les champs « username » et « password » sont définis avec des attributs utilisateur. Chaque utilisateur peut ainsi accéder à la base de données avec ses propres identifiants. La section Remplacements PDT crée un utilisateur distinct (pdt_user) possédant son propre mot de passe. Le compte pdt_user sera utilisé pour l'ensemble des processus PDT, avec des niveaux d'accès adaptés à la création et à la mise à jour de tables PDT.
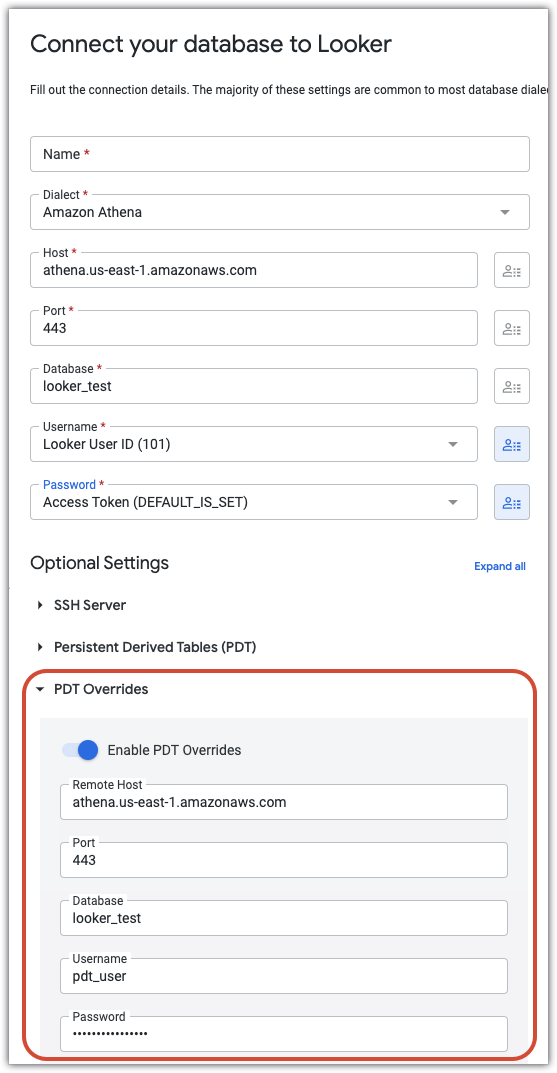
Fuseau horaire
Fuseau horaire de la base de données
Le fuseau horaire dans lequel votre base de données stocke les informations temporelles. Looker doit connaître cette information afin de convertir les valeurs de date/heure pour les utilisateurs et ainsi simplifier la compréhension et l'utilisation des données temporelles. Pour en savoir plus, consultez la page de documentation Utiliser les paramètres de fuseau horaire.
Requête Fuseau horaire
L'option Fuseau horaire de la requête n'est visible que si vous avez désactivé Fuseaux horaires spécifiques à l'utilisateur.
Lorsque les fuseaux horaires spécifiques à l'utilisateur sont désactivés, le fuseau horaire de la requête est celui qui s'affiche pour vos utilisateurs lorsqu'ils interrogent des données basées sur l'heure. Il s'agit également du fuseau horaire dans lequel Looker convertit les données basées sur l'heure à partir du fuseau horaire de la base de données.
Pour en savoir plus, consultez la page de documentation Utiliser les paramètres de fuseau horaire.
Autres paramètres
Paramètres JDBC supplémentaires
Si nécessaire, vous pouvez inclure d'autres paramètres JDBC (Java Database Connectivity) dans vos requêtes.
Pour référencer un attribut utilisateur dans un paramètre JDBC, utilisez la syntaxe de modélisation Liquid : _user_attributes['name_of_attribute']. Exemple :
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Max Connections per node
Ici, vous pouvez configurer le nombre maximal de connexions que Looker peut établir avec votre base de données. Dans la majorité des cas, vous configurez le nombre de requêtes simultanées que Looker peut exécuter sur votre base de données. Looker consacre également jusqu'à trois connexions à la suppression des requêtes. Si le pool de connexions est de taille très restreinte, Looker consacrera moins de connexions.
Vous devez configurer cette valeur attentivement. Si cette valeur est trop élevée, vous risquez de submerger votre base de données. Si cette valeur est trop faible, les requêtes devront partager une petite quantité de connexions. Chaque requête devant attendre le retour des autres requêtes précédemment exécutées, il se peut donc que de nombreuses requêtes semblent lentes aux utilisateurs.
La valeur par défaut (qui varie en fonction de votre dialecte SQL) constitue généralement un point de départ raisonnable. Pour ce qui est du nombre maximal de connexions qu'elles acceptent, la plupart des bases de données disposent également de leur propre configuration. Si la configuration de votre base de données limite les connexions, veillez à ce que la valeur Nombre maximal de connexions par nœud soit inférieure ou égale à la limite de votre base de données.
Expiration du pool de connexions
Si vos utilisateurs demandent davantage de connexions que la valeur Nombre maximal de connexions par nœud configurée, les requêtes devront attendre la fin des requêtes précédentes avant de pouvoir s'exécuter. Le temps d'attente maximal d'une requête se configure à cet endroit. Le paramètre par défaut est de 120 secondes.
Vous devez configurer cette valeur attentivement. S'il est trop faible, il se peut que les utilisateurs voient leurs requêtes annulées, car les requêtes des autres utilisateurs n'auront pas eu le temps de s'achever. S'il est trop élevé, il se peut qu'une grande quantité de requêtes s'accumulent et que le temps d'attente soit très long pour les utilisateurs. La valeur par défaut constitue généralement un point de départ raisonnable.
Nombre maximal de requêtes simultanées pour cette connexion
Cette valeur facultative limite le nombre de requêtes simultanées que Looker peut envoyer à la fois à cette connexion de base de données. Si d'autres requêtes simultanées arrivent en demandant la même connexion, Looker les place en file d'attente en interne et les traite dans l'ordre. Si vous définissez cette valeur, elle écrasera la valeur Nombre maximal de connexions par nœud existante.
Nombre maximal de requêtes simultanées par utilisateur pour cette connexion
Cette valeur facultative limite le nombre de requêtes simultanées d'un même utilisateur que Looker peut envoyer à la fois à cette connexion de base de données. Si d'autres requêtes simultanées arrivent en demandant la même connexion, Looker les place en file d'attente en interne et les traite dans l'ordre.
SSL
Choisissez si vous souhaitez, ou non, utiliser le chiffrement SSL pour protéger vos données pendant leur transition entre Looker et votre base de données. SSL n'est qu'une des options permettant de protéger vos données. D'autres options sécurisées sont décrites sur la page de documentation Activer l'accès sécurisé à la base de données.
Vérifier le protocole SSL
Choisissez si vous souhaitez demander une vérification du certificat SSL utilisé par la connexion. Si la validation est requise, l'autorité de certification (AC) SSL qui a signé le certificat SSL doit provenir de la liste des sources fiables du client. Si l'AC n'est pas une source fiable, la connexion de base de données n'est pas établie.
Si cette case n'est pas cochée, le chiffrement SSL est toujours utilisé sur la connexion, mais la vérification de la connexion SSL n'est pas requise. De fait, une connexion peut être établie lorsque l'AC ne figure pas sur la liste des sources fiables du client.
Effectuer une mise en cache préalable de l'exécuteur SQL
Dans SQL Runner, toutes les informations de la table sont préchargées dès que vous sélectionnez une connexion et un schéma. Cela permet à SQL Runner d'afficher rapidement les colonnes de la table dès que vous cliquez sur un nom de table. Néanmoins, pour les connexions et les schémas comportant de nombreuses tables ou des tables très volumineuses, il se peut que vous ne souhaitiez pas que SQL Runner précharge l'ensemble des informations.
Si vous préférez que SQL Runner charge les informations de la table seulement lorsqu'une table est sélectionnée, vous pouvez désélectionner l'option SQL Runner Precache afin de désactiver le préchargement de SQL Runner pour la connexion.
Télécharger un schéma d'informations pour l'écriture SQL
Pour certaines fonctionnalités d'écriture SQL, comme la prise en compte des agrégats, Looker utilise le schéma d'informations de votre base de données pour optimiser l'écriture SQL. Si le schéma d'informations n'est pas mis en cache, Looker peut être amené à bloquer l'écriture SQL sur la base de données afin de télécharger le schéma d'informations. Pour les dialectes qui utilisent le système de fichiers distribué Hadoop (HDFS), la récupération du schéma d'informations peut prendre suffisamment de temps pour affecter considérablement les performances de vos requêtes Looker. Si vous savez que votre schéma d'informations est lent, vous pouvez désactiver l'option Extraire le schéma d'informations de l'écriture SQL pour votre connexion. La désactivation de cette fonctionnalité empêchera certaines optimisations SQL de Looker pour certaines fonctionnalités. Vous devez donc activer l'option Télécharger un schéma d'informations pour l'écriture SQL, sauf si vous savez que le schéma d'informations de votre connexion est particulièrement lent.
Estimation du coût
L'option Estimation des coûts ne s'applique qu'aux connexions de base de données suivantes :
- Snowflake
- Amazon Redshift
- Amazon Aurora
- PostgreSQL, Google Cloud SQL pour PostgreSQL et Microsoft Azure PostgreSQL
Le bouton Estimation des coûts permet d'activer les fonctionnalités suivantes sur la connexion :
- Estimations de coûts pour les requêtes d'exploration
- Estimations des coûts pour les requêtes SQL Runner
- Estimations des économies de calcul pour les requêtes de visibilité globale
Pour en savoir plus, consultez la page de documentation Explorer les données dans Looker.
Pooling de connexions de base de données
Pour les dialectes compatibles avec le regroupement de connexions de base de données, cette fonctionnalité permet à Looker d'utiliser des pools de connexions via le pilote JDBC. Le regroupement de connexions à la base de données permet d'améliorer les performances des requêtes. En effet, une nouvelle requête n'a pas besoin de créer une connexion à la base de données, mais peut utiliser une connexion existante à partir du pool de connexions. La fonctionnalité de mise en pool de connexions garantit qu'une connexion est nettoyée après l'exécution d'une requête et qu'elle est disponible pour être réutilisée une fois l'exécution de la requête terminée. Pour en savoir plus, consultez la page de documentation Pool de connexions à la base de données.
Test de vos paramètres de connexion
Vous pouvez tester vos paramètres de connexion à partir de plusieurs endroits de l'interface utilisateur Looker :
- Sélectionnez le bouton Tester en bas de la page Paramètres de connexion.
- Sélectionnez le bouton Tester à côté de la connexion dans la page d'administration Connexions, comme décrit sur la page de documentation Connexions.
Une fois que vous avez saisi les paramètres de connexion, cliquez sur Tester pour vérifier que les informations sont correctes et que la base de données est en mesure de se connecter.
Si votre connexion ne réussit pas un ou plusieurs tests, voici quelques options de dépannage :
- Essayez quelques étapes de dépannage disponibles sur la page de documentation Tester la connectivité à la base de données.
- Si vous exécutez la version 3.6 ou une version antérieure de Mongo sur Atlas et que vous rencontrez un échec de lien de communication, consultez la page de documentation Mongo Connector.
- Pour recevoir des messages indiquant une connexion réussie concernant le schéma et les tables PDT temporaires, vous devrez avoir activé cette fonctionnalité au moment du paramétrage de votre base de données Looker. Des instructions à ce sujet sont disponibles sur la page de documentation Instructions pour la configuration de la base de données.
Si le problème persiste, ouvrez une demande d'assistance.
Tester en tant qu'utilisateur
Si vous avez défini une ou plusieurs valeurs de paramètre de connexion sur un attribut utilisateur, l'option Tester en tant qu'utilisateur s'affiche. Sélectionnez un utilisateur, puis cliquez sur Tester pour vérifier que la base de données peut se connecter et exécuter des requêtes en tant que cet utilisateur.
Étapes suivantes
Après avoir connecté votre base de données à Looker, vous pouvez configurer des options de connexion pour vos utilisateurs.