This document describes how to perform bulk upload, which triggers the Cloud Storage ingest pipeline behind the scene.
Preprocessing options
Currently, the bulk upload provides three preprocessing options:
Bulk upload without preprocessing: This triggers runPipeline API with GcsIngestPipeline without processing the documents with Document AI processors.
Extract entities with Document AI processors: This triggers runPipeline API with GcsIngestWithDocAiProcessorsPipeline. The pipeline will call the given Document AI processor first, and then ingest the documents with the processed results.
Classify document types and extract entities for each type: This also triggers runPipeline API with GcsIngestWithDocAiProcessorsPipeline, which first calls a classifier. Then, for each document type, you can specify a corresponding schema and processor to process those particular document types. They're ingested with the results and set to this schema.
Each of the preprocessing types correspond to the following options in the UI:
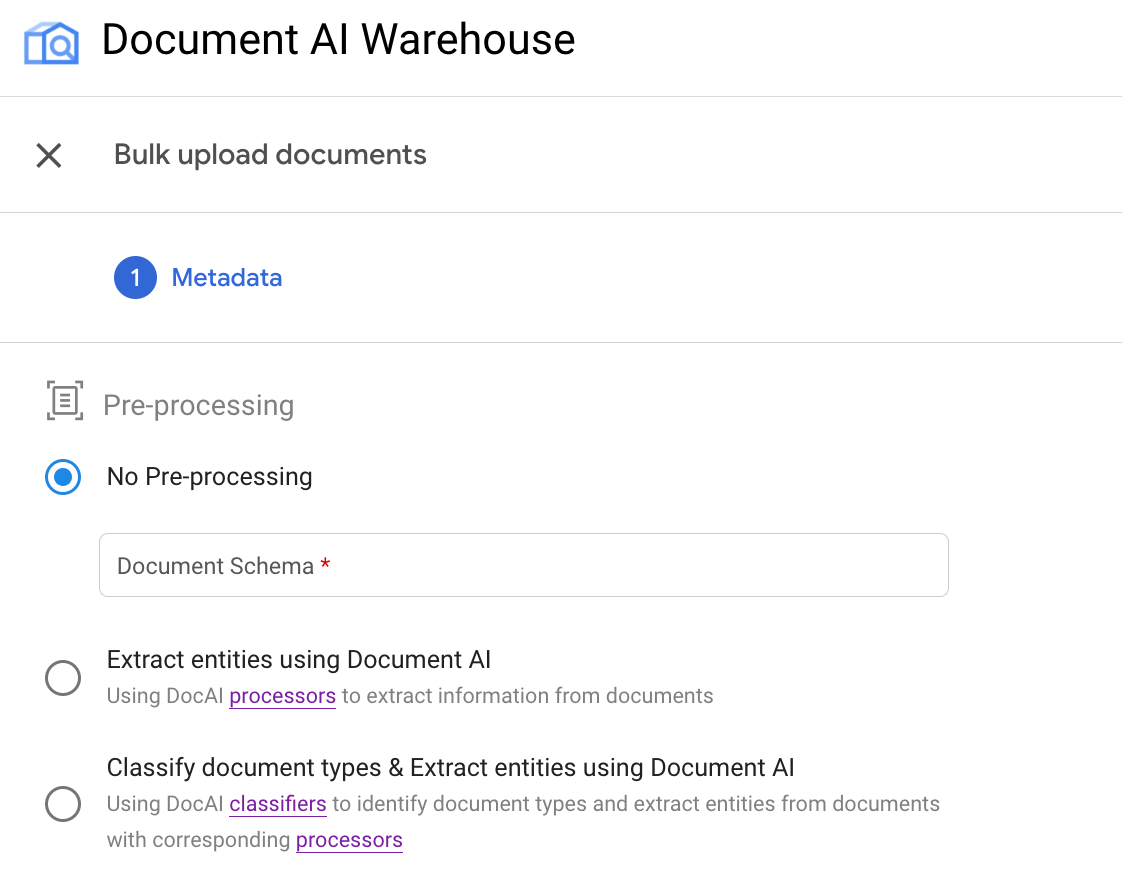
Example: Trigger bulk upload with an OCR processor
This example illustrates the second use of the pipeline.
Create an OCR processor and get processor ID
If you have created an OCR processor before, just find it in the processor list, and go into the details page of the processor and get the processor ID.
If you have not created one, follow these steps:
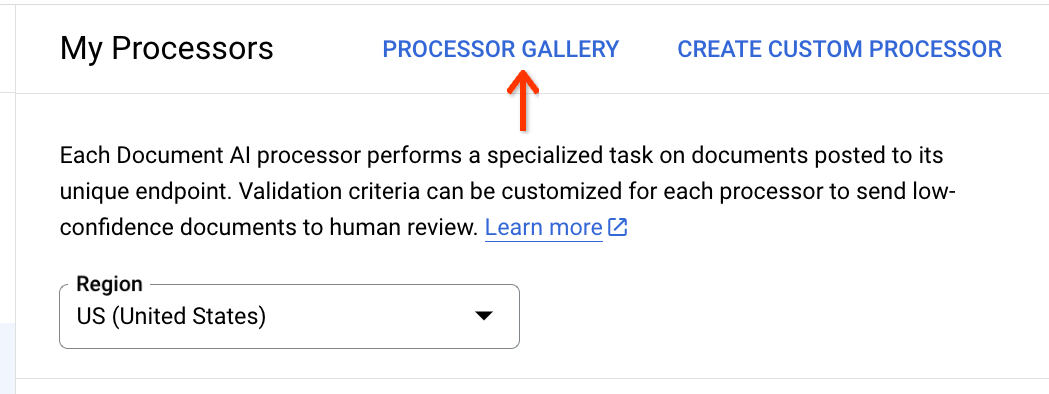
At the top of the processor list, click the Processor Gallery:
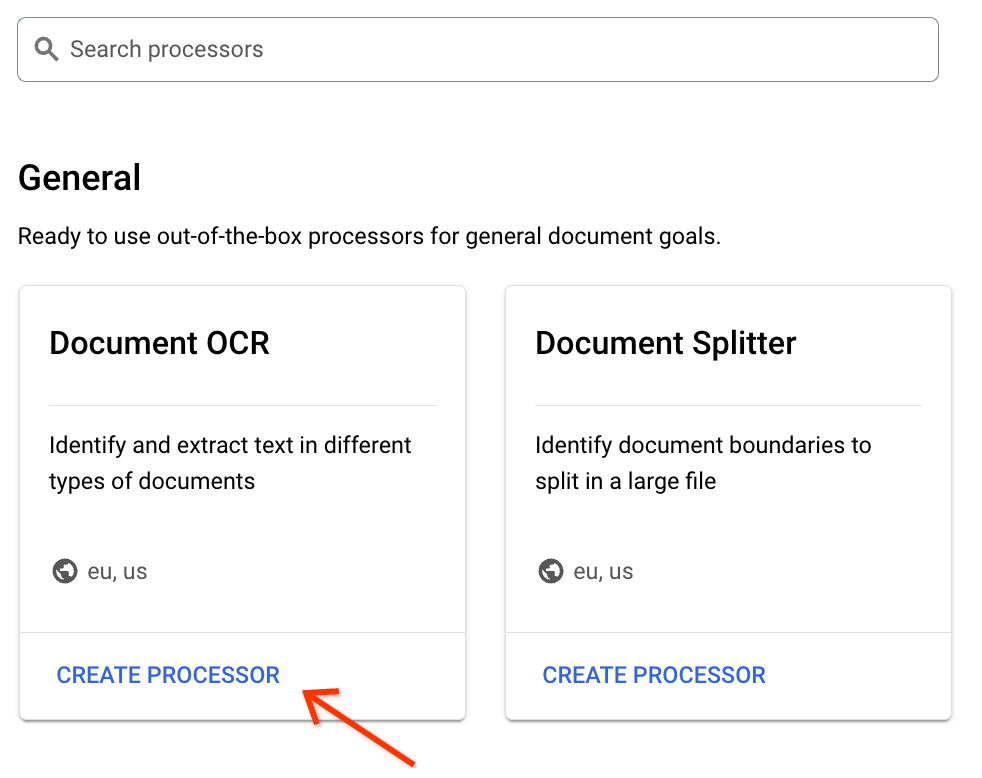
Find the Document OCR processor in the gallery, and at the bottom of the card, click Create Processor:
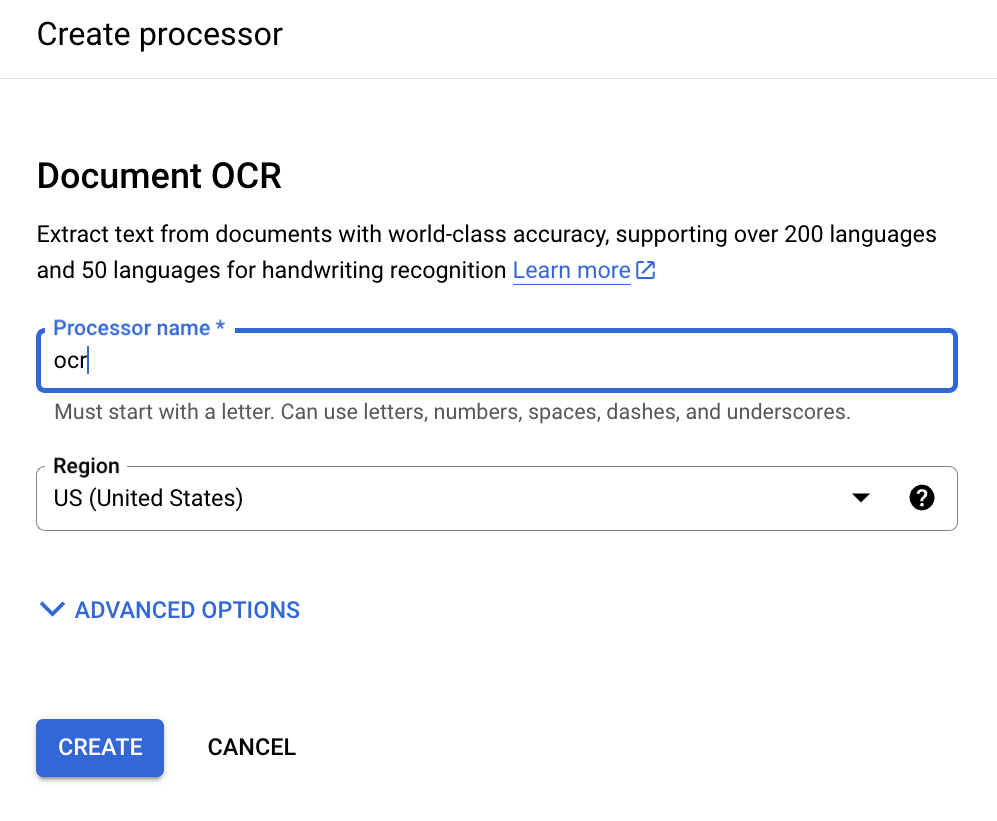
Enter a processor display name:
Click Create and when you're redirected to the Processor Details page, find the ID:
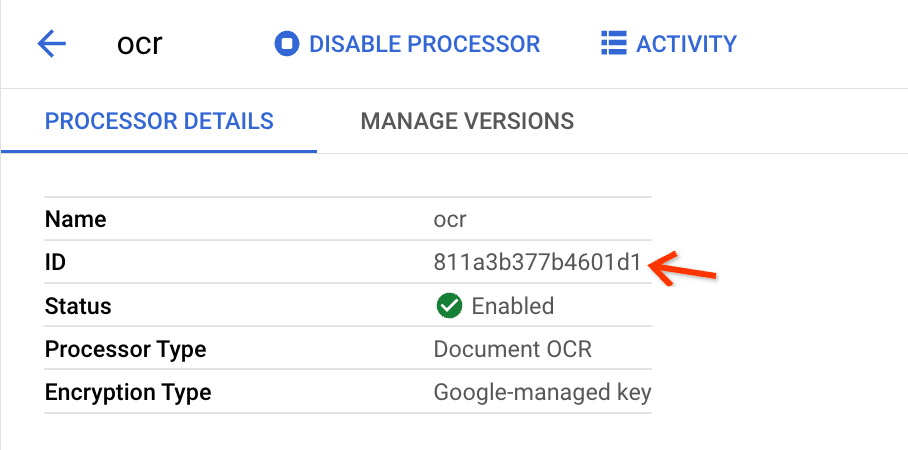
This is what you need to copy to the input fields in the bulk upload view.
Trigger bulk upload
Open the bulk upload view.
Next to Add New, click Bulk Upload:
Find the correct processor.
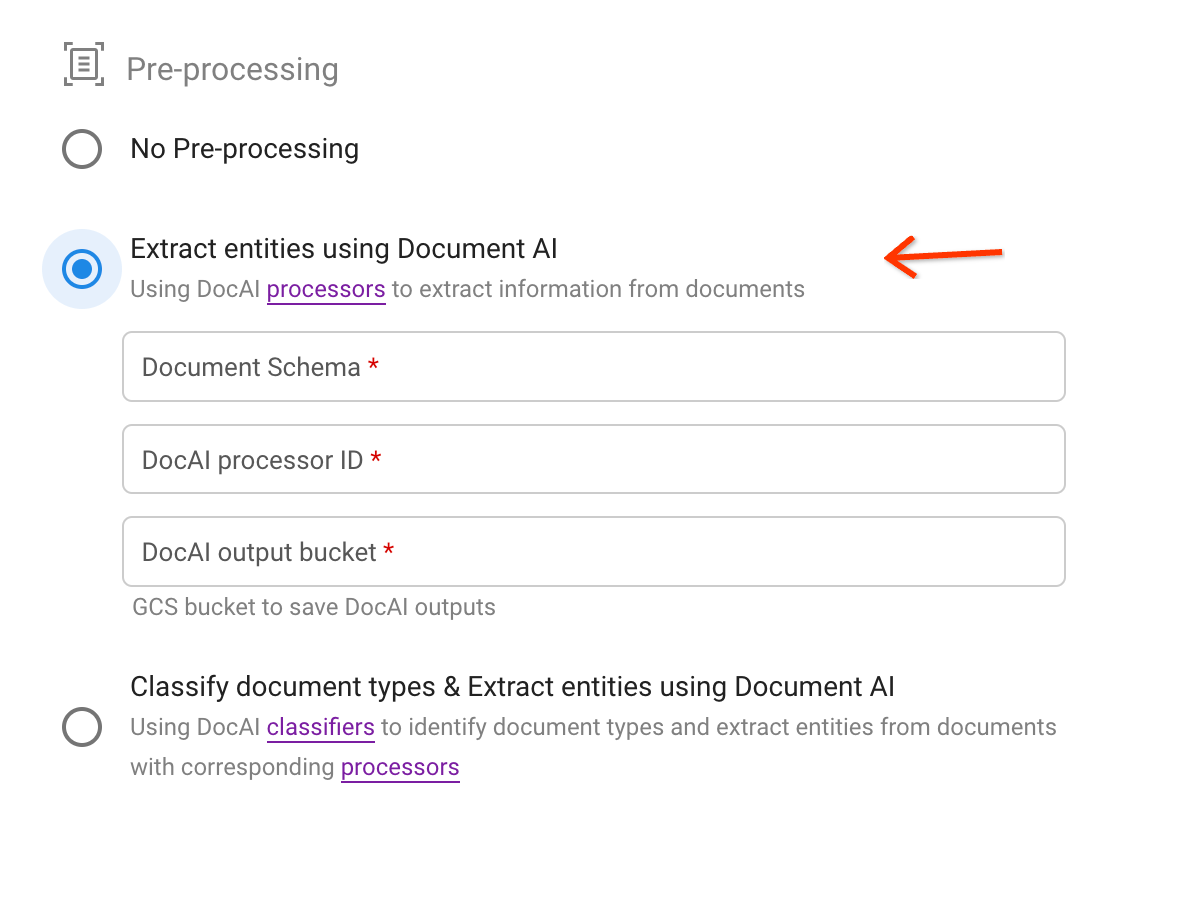
Select the second preprocessing option.
Choose a schema and specify a processor and Cloud Storage bucket path for saving the extraction results in JSON format.
Find the processor ID through the link in the description text:
Trigger upload:
With the processor ID copied from the last step, specify the input fields. The source file bucket path can be a bucket or a folder or subfolder in the bucket.
When the input fields are valid, to trigger bulk upload, at the top right, click Upload.
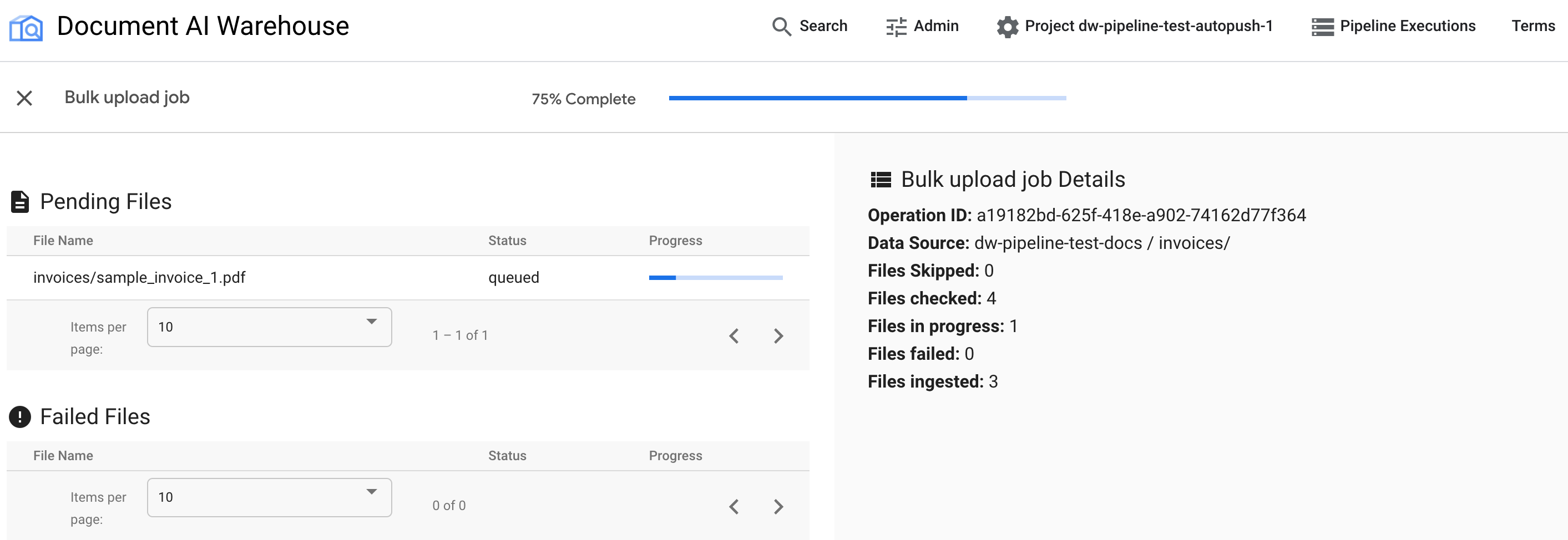
Check progress in the status page
After the bulk upload is triggered, you are redirected to the status tracking page:
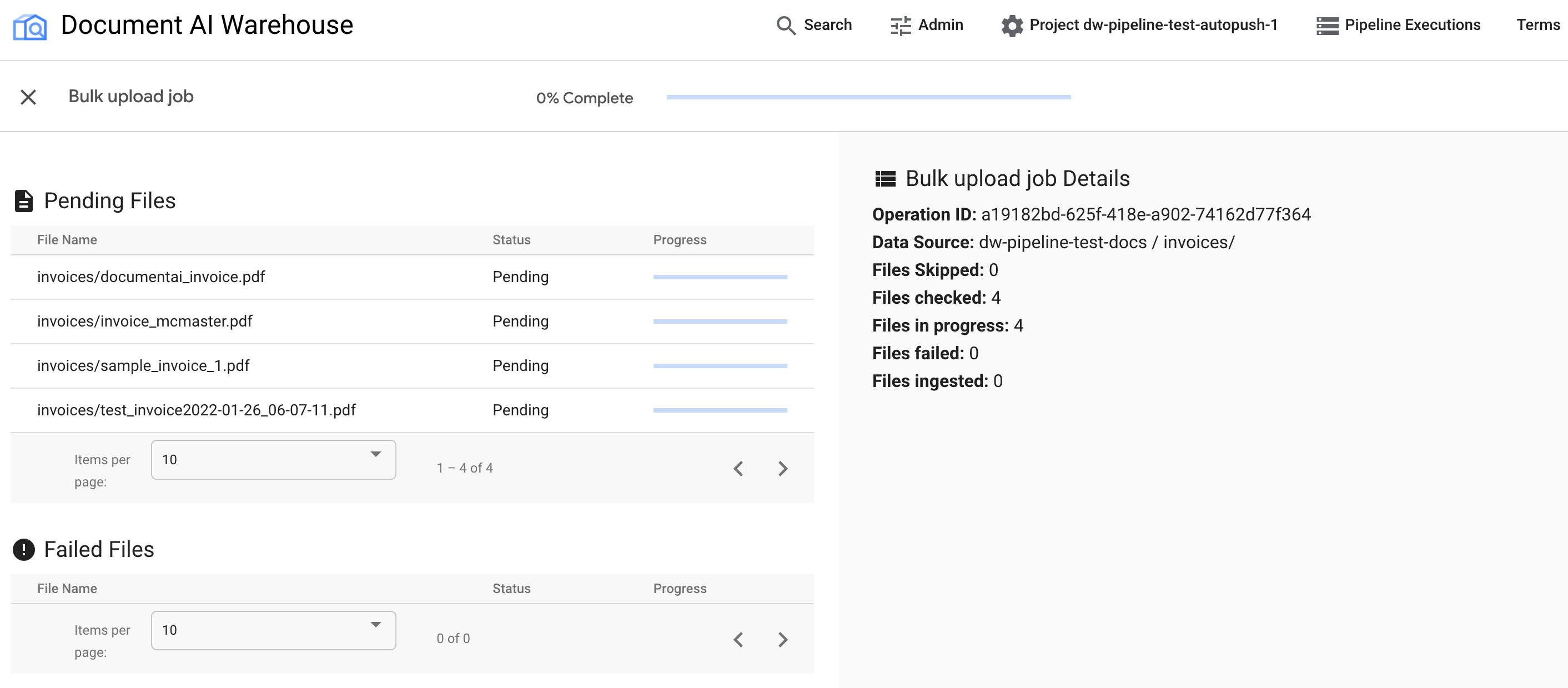
The first table shows any pending or processed documents. After they're ingested, the document is not listed in the first table anymore. Documents that failed to upload appear in the second table. On the right, the statistics shows the number of ingested, failed, and pending documents.
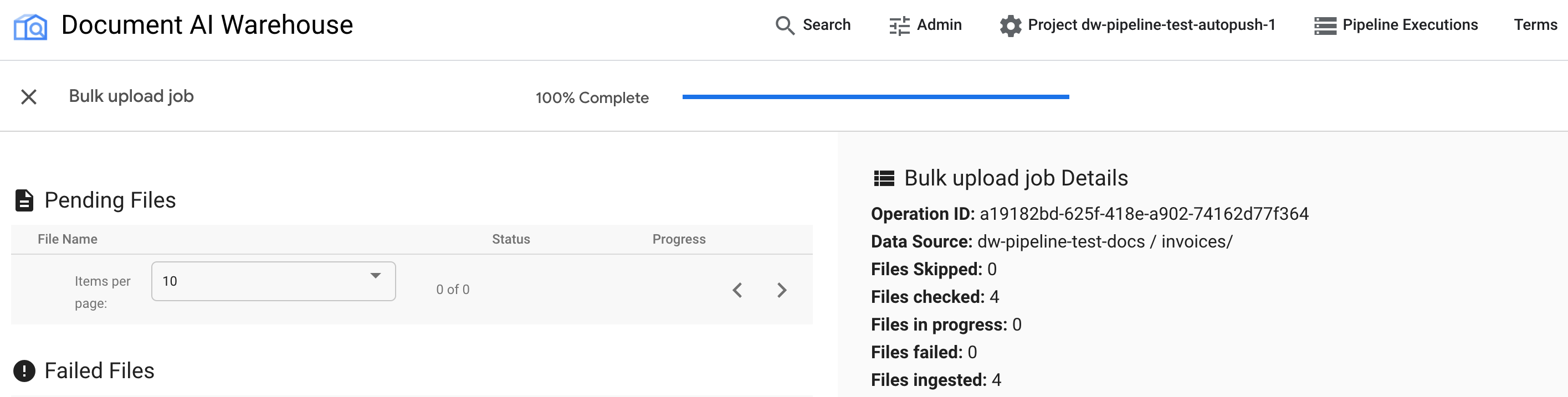
After the job is complete, the status page shows 100% complete without any pending documents:
Examine the uploaded documents
Find the newly ingested documents by going back to the search view. Click the Document AI Warehouse logo or Search on the top navigation bar:

Open any of the newly ingested documents by clicking the document name. In the document viewer, you can open the AI View.
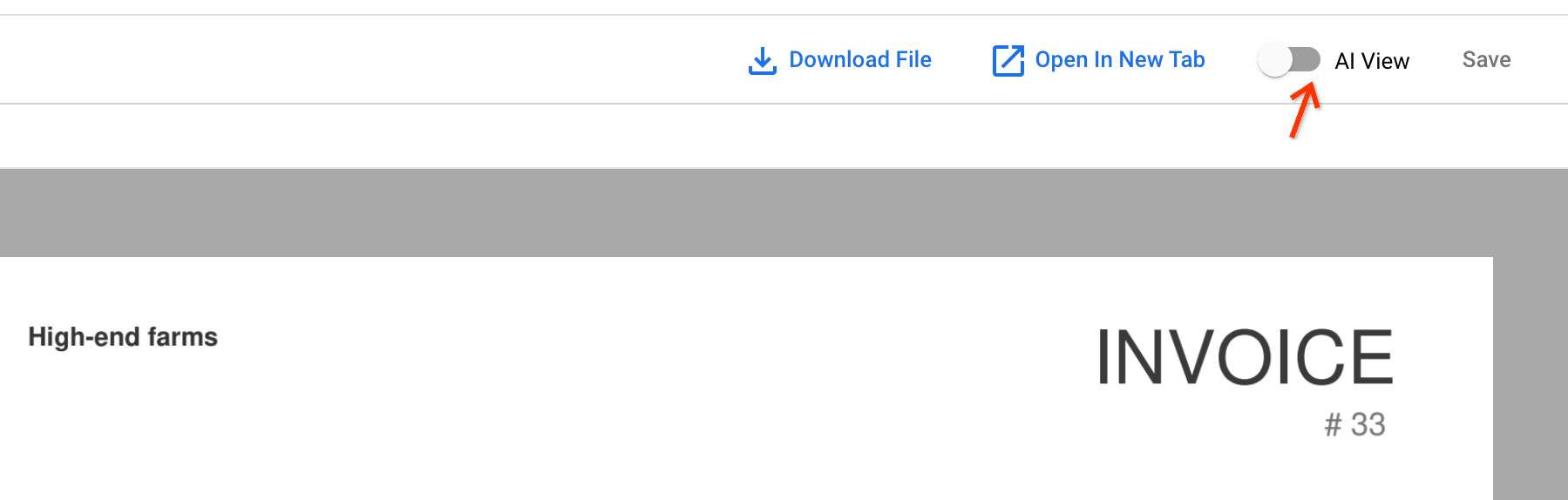
Go to the Text block tab. The OCR results are stored in the document:
Next step
Update existing documents with the extract with Document AI pipeline.