目標
Dataproc Hub を使用して、Dataproc クラスタ上で実行する単一ユーザーの JupyterLab ノートブック環境を作成する。
ノートブックを作成し、Dataproc クラスタ上で Spark ジョブを実行する。
クラスタを削除し、ノートブックを Cloud Storage に保存する。
始める前に
- 管理者から
notebooks.instances.use権限が付与されている必要があります(Identity and Access Management(IAM)のロールを設定するをご覧ください)。
Dataproc Hub から Dataproc JupyterLab クラスタを作成する
Google Cloud コンソールの [Dataproc] → [ワークベンチ] ページで、[ユーザー管理のノートブック] タブを選択します。
管理者が作成した Dataproc Hub インスタンスが一覧表示される行の [JupyterLab を開く] をクリックします。
- Google Cloud コンソールへのアクセス権がない場合は、管理者が共有している Dataproc Hub インスタンスの URL をウェブブラウザで入力します。
[Jupyterhub] → [Dataproc Options] ページで、クラスタ構成とゾーンを選択します。有効である場合は、カスタマイズを指定して、[Create] をクリックします。
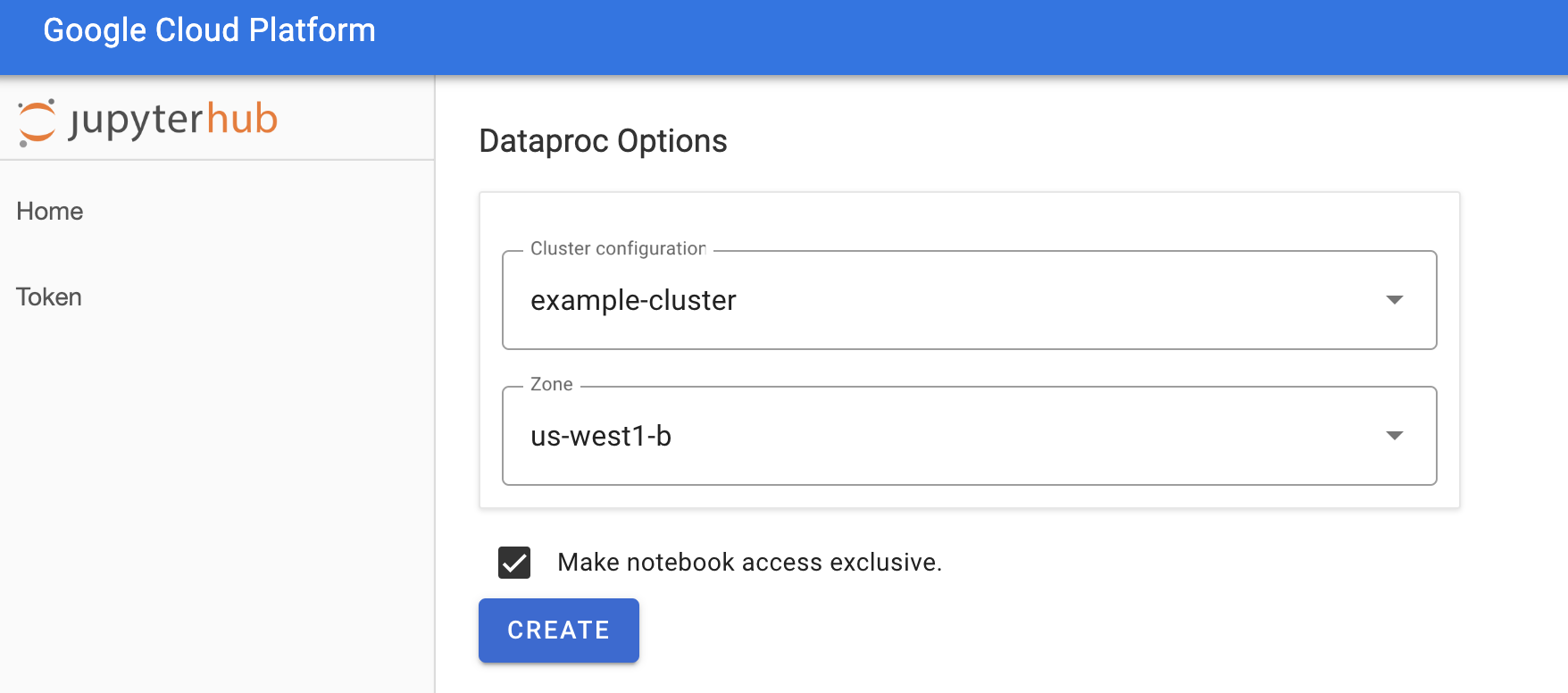
Dataproc クラスタが作成されると、クラスタ上で実行されている JupyterLab インターフェースにリダイレクトされます。
ノートブックを作成して Spark ジョブを実行する
JupyterLab インターフェースの左パネルで
GCS(Cloud Storage)をクリックします。JupyterLab ランチャーから PySpark ノートブックを作成します。
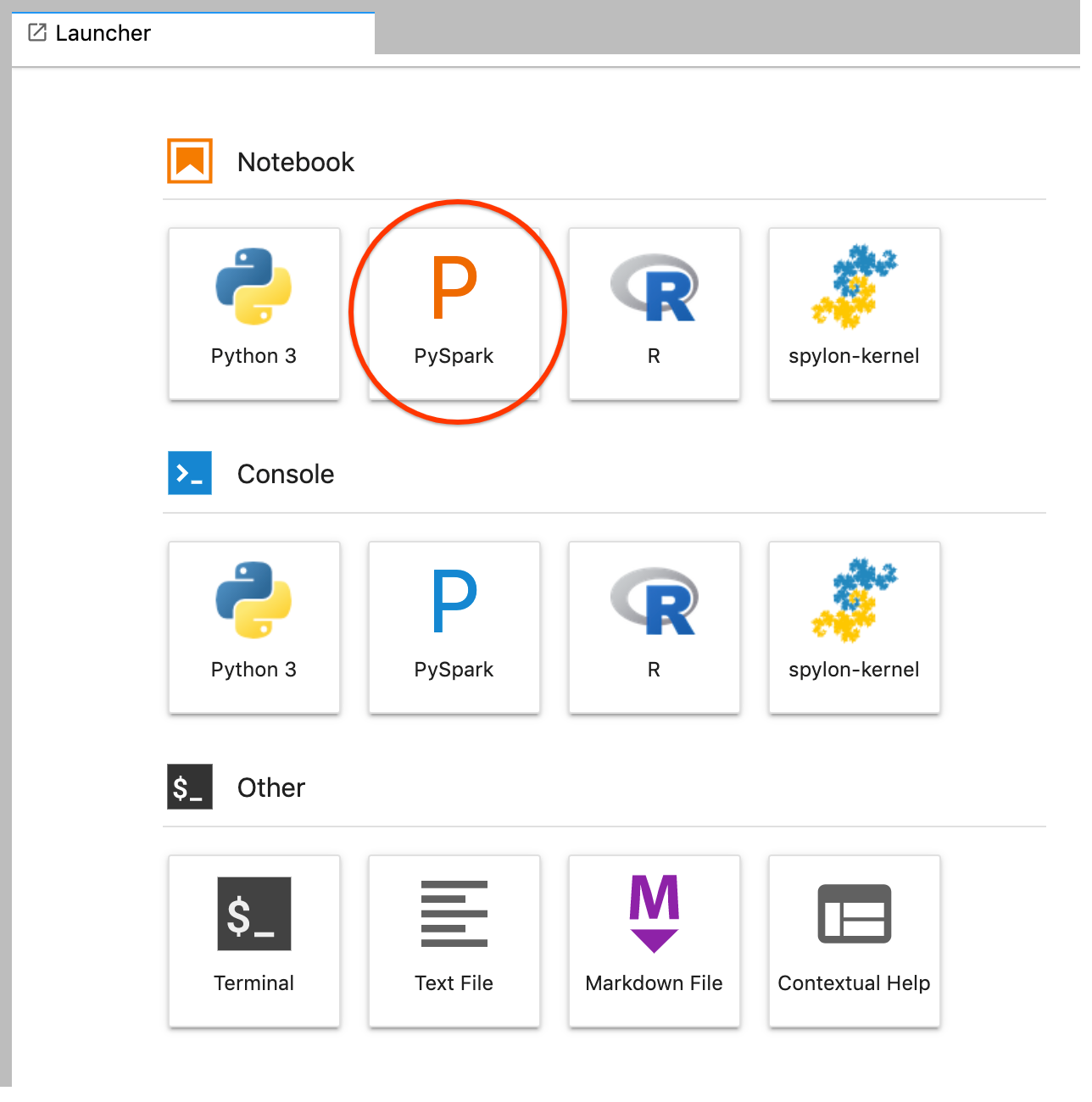
PySpark カーネルは(
sc変数を使用して)SparkContext を初期化します。SparkContext を調べて、ノートブックから Spark ジョブを実行できます。rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem']) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b)) print(rdd.collect())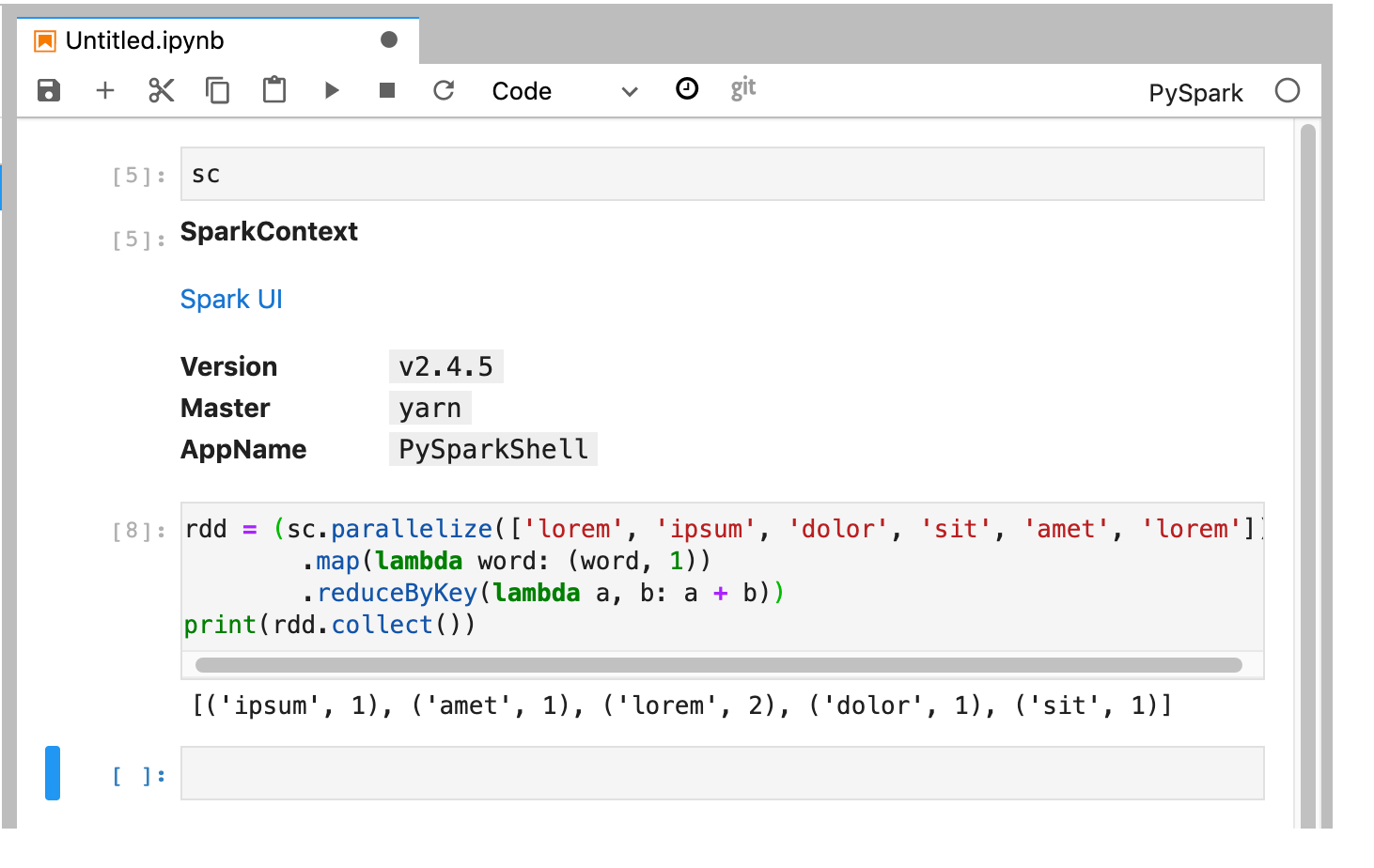
ノートブックに名前を付けて保存します。ノートブックが保存され、Dataproc クラスタの削除後も Cloud Storage に残ります。
Dataproc クラスタをシャットダウンする
JupyterLab インターフェースから、[File] → [Hub Control Panel] を選択して、[Jupyterhub] ページを開きます。
[Stop My Cluster] をクリックして、JupyterLab サーバーをシャットダウン(削除)し、Dataproc クラスタを削除します。
次のステップ
- GitHub で Dataproc の Spark と Jupyter ノートブックを調べる。