La traçabilité des données est une fonctionnalité Dataplex qui vous permet de suivre la manière dont les données transitent par vos systèmes: leur origine, la cible de transmission, et les transformations qui leur sont appliquées.
Pourquoi avez-vous besoin de la traçabilité des données ?
La gestion de grands ensembles de données implique souvent de transformer les données en entités adaptées aux besoins d'un projet spécifique: fichiers texte, tableaux, rapports, tableaux de bord, modèles.
Par exemple, imaginons que vous possédiez une boutique en ligne dans laquelle vous enregistrez chaque achat dans une seule table SQL. Pour faciliter le travail de vos analystes avec les données, vous commencez à exécuter des tâches qui extraient des informations de cette seule table et produisent des tables plus petites par région, par marque ou par prix soldé. Vos analystes commencent ensuite à faire de même: ils effectuent d'autres transformations, en fusionnant ces petites tables avec d'autres sources de données pour produire encore plus de tables.
Cela peut devenir un défi de taille pour vos partenaires:
- Les consommateurs de données ne peuvent pas utiliser un outil en libre-service pour déterminer si les données proviennent d'une source fiable.
- Les ingénieurs en données ne peuvent pas identifier la cause des problèmes, car ils ne disposent pas de moyen fiable de suivre toutes les transformations de données.
- Les ingénieurs et analystes de données ne peuvent pas évaluer pleinement l'impact possible avant de modifier ou de supprimer des tables.
- Les responsables de la gouvernance des données ne peuvent pas comprendre comment les données sensibles sont utilisées dans l'ensemble de l'organisation et s'assurer du respect des exigences réglementaires.
La généalogie des données est une solution qui permet de suivre les données de manière pratique:
- Découvrez comment les données sont collectées et transformées à l'aide de graphiques de filiation.
- Recherchez les causes des erreurs de suivi liées aux entrées et aux opérations de données.
- Améliorez la gestion des changements grâce à l'analyse d'impact: évitez les temps d'arrêt ou les erreurs inattendues, comprenez les entrées dépendantes et collaborez avec les personnes concernées.
Modèle d'informations sur la traçabilité des données
Dans sa forme de base, la lignée est un enregistrement des données qui sont transformées de sources en cibles. L'API Data Lineage collecte ces informations et les organise dans un modèle de données hiérarchique à l'aide des concepts de processus, d'exécutions et d'événements.
Processus
Un processus correspond à la définition d'une opération de transformation de données compatible avec un système spécifique. Dans le contexte de la lignée BigQuery, un process est l'un des types de tâches compatibles.
Exécuter
Une exécution correspond à une exécution d'un processus. Les processus peuvent être exécutés plusieurs fois.
Les exécutions contiennent des informations telles que les heures de début et de fin, l'état ou des attributs supplémentaires.
Pour en savoir plus, consultez la documentation de référence sur la ressource run.
Événement
Un événement représente un point dans le temps où une opération de transformation de données a eu lieu et a entraîné le transfert de données entre une source et une entité cible.
Les événements contiennent une liste de maillons qui définissent quelle entrée était la source et quelle était la cible d'un événement particulier. Bien que les événements soient utilisés pour calculer des graphiques de filiation, ils ne sont pas directement exposés dans la console Google Cloud. Vous pouvez les créer, les lire et les supprimer (mais pas les mettre à jour) à l'aide de l'API Data Lineage.
Exemple
Prenons l'exemple suivant, où des données sont copiées entre des tables BigQuery:
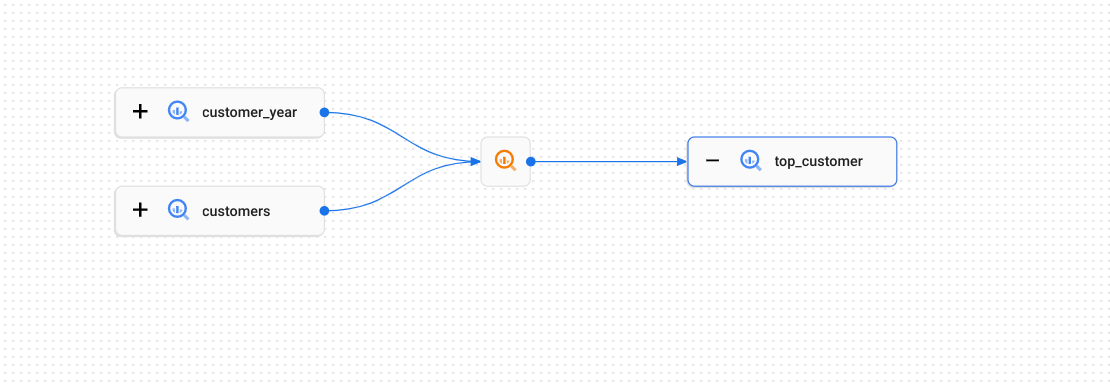
Le processus de lignée (représenté sur le graphique par l'icône ![]() ) décrit la manière dont les données sont transférées entre les tables. Il peut s'agir d'une requête SQL
) décrit la manière dont les données sont transférées entre les tables. Il peut s'agir d'une requête SQL CREATE TABLE AS SELECT ou d'une instruction INSERT.
Chaque exécution de cette instruction SQL constituerait une exécution individuelle.
Les exécutions contiennent des événements qui enregistrent les tables utilisées comme sources et comme cibles. Dans cet exemple, les tables customer_year et customers sont toutes deux la source de la table top_customer cible.
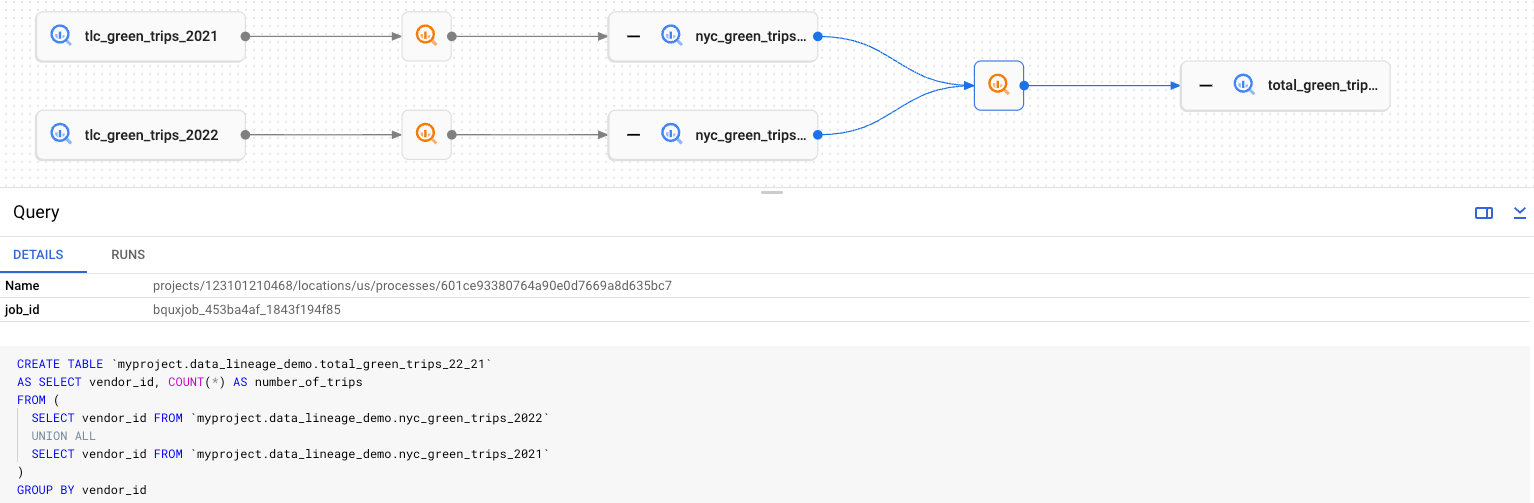
Graphique de traçabilité
Les graphiques de traçabilité représentent les informations collectées par l'API Data Lineage pour une entrée Data Catalog spécifique. Un graphique de traçabilité montre la lignée en amont ou en aval d'une seule entrée racine. Racine fait référence à l'entrée pour laquelle vous consultez la lignée.
Dataplex fonctionne avec l'API Data Lineage pour identifier les entrées dont le nom complet correspond aux entités reconnues par la traçabilité des données. Pour les entrées Dataplex correspondantes, vous pouvez accéder à l'onglet Lignée sur leur page d'informations et afficher le graphique.
Les graphiques de lignée affichent deux types d'éléments:
Boutons rectangulaires larges qui représentent les entités impliquées dans la construction d'informations de lignée en tant que sources ou cibles d'un événement de lignée.
Boutons carrés plus petits représentant les processus chargés de créer ou de mettre à jour les entités source ou cible. Les boutons de processus utilisent des icônes spécifiques au système source qui les a signalés à l'API Data Lineage. Par exemple, les tâches BigQuery utilisent l'icône
 .
.
Visualisation du chemin de traçabilité
Les visualisations du chemin de traçabilité vous aident à comprendre les liens de traçabilité entre deux ressources sélectionnées. (Contrairement au graphique de traçabilité, qui affiche la lignée en amont ou en aval d'une seule entrée racine, potentiellement pour plusieurs sources ou cibles.)
Vous choisissez la ressource racine et une ressource cible, et la console Google Cloud affiche les liens de traçabilité entre les deux ressources. Les autres ressources et processus qui ne se trouvent pas sur un chemin entre les deux ressources sont masqués dans la visualisation du chemin.

Vue de la traçabilité sous forme de liste
La vue de liste de la généalogie affiche des informations détaillées sur la généalogie des entités dans un seul tableau.
Contrairement au graphique de la lignée, qui est plus adapté à l'affichage de graphiques de lignée relativement petits, la vue de la liste de la lignée vous permet d'afficher des informations sur la lignée des entités ayant de nombreuses connexions.
L'image suivante montre un exemple de vue de liste de la généalogie dans la console Google Cloud. La liste suivante décrit l'image plus en détail.
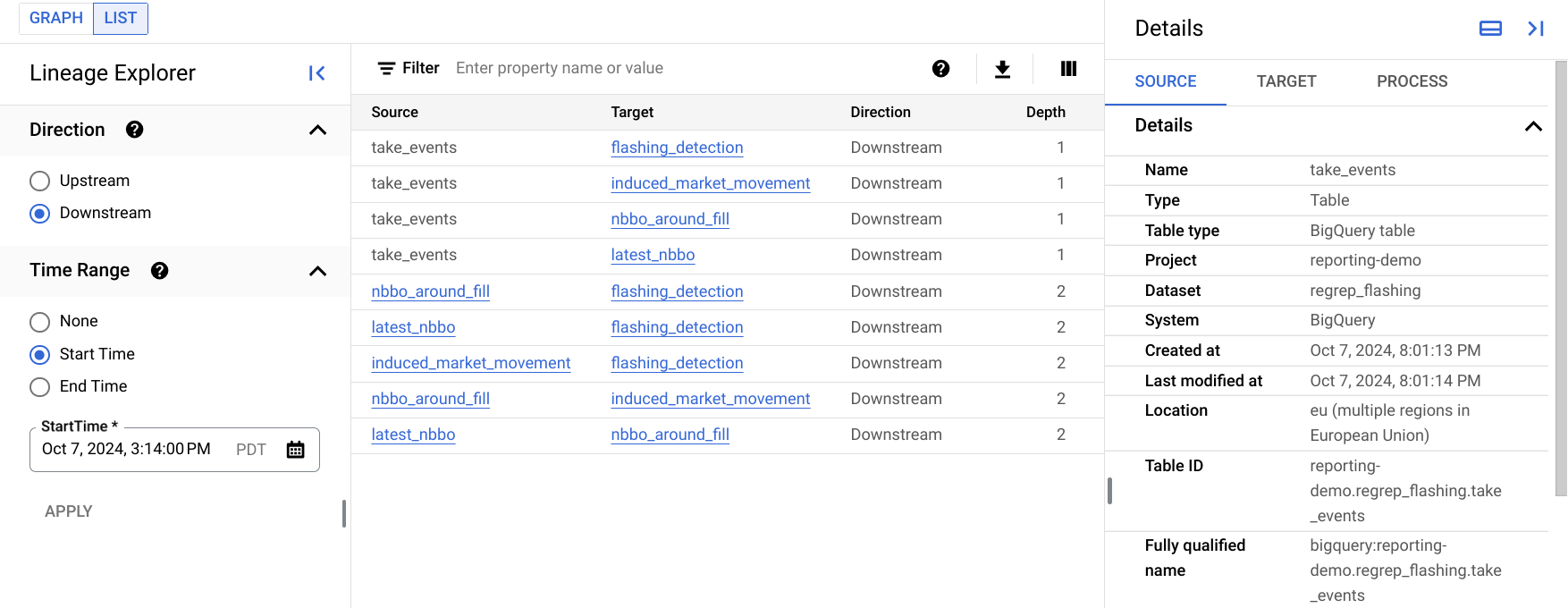
Chaque ligne du tableau représente un seul lien de lignée entre deux entrées. Dans le graphique, ces noms sont représentés par les liens de filiation entre deux entrées, y compris les nœuds de processus intermédiaires. Par exemple,
SourceetTargetsont des nœuds d'éléments, avec éventuellement plusieurs nœuds de processus entre eux.L'option Sens spécifie la partie du flux de données à afficher dans la liste, par rapport à l'élément racine:
En amont: affiche des informations sur la lignée pour les entrées qui sont des sources de données pour l'entrée sélectionnée. Dans le graphique de la lignée, ces entrées sont celles qui apparaissent à gauche de l'entrée sélectionnée.
En aval: affiche les informations de filiation pour les entrées qui utilisent l'entrée sélectionnée ou en sont dérivées. Sur le graphique de la lignée, ces entrées s'affichent à droite de l'entrée sélectionnée.
L'option Plage temporelle vous permet de filtrer les informations de traçabilité en fonction du moment où la traçabilité a eu lieu:
Heure de début: affiche la filiation qui s'est produite après l'heure de début.
Heure de fin: affiche la filiation qui s'est produite avant l'heure de fin.
La profondeur indique la distance d'une ressource source ou dérivée par rapport à la ressource racine. La vue Liste affiche jusqu'à 1 000 maillons de lignée, avec une profondeur maximale de 10 maillons de lignée à partir de la racine. Si une lignée se trouve en dehors de cette plage, vous en êtes informé. Vous pouvez afficher la lignée en dehors de cette plage en sélectionnant le nom d'une autre entité dans la vue Liste.
Le panneau Détails affiche des informations sur la source du lien, la cible du lien et tous les processus ayant créé ce lien.
Vous pouvez personnaliser les colonnes affichées dans le tableau et filtrer les résultats. Vous pouvez également exporter les résultats dans un fichier CSV.
Suivi automatique de la traçabilité des données
Lorsque vous activez l'API Data Lineage, Google Cloud les systèmes compatibles avec la traçabilité des données commencent à signaler leur mouvement de données. Chaque système intégré peut envoyer des informations sur la lignée pour une gamme différente de sources de données. Pour en savoir plus sur chaque produit compatible, consultez les sections suivantes.
BigQuery
L'activation de la traçabilité des données dans votre projet BigQuery oblige Dataplex à enregistrer automatiquement les informations de traçabilité pour:
Nouvelles tables créées à la suite des tâches BigQuery suivantes:
- Tâches de copie
- Tâches de chargement qui utilisent l'URI Cloud Storage pour charger des données dans n'importe quel format autorisé à partir de Cloud Storage*
- Tâches de requête qui utilisent le langage de définition de données (LDD) suivant dans GoogleSQL :
Tables existantes créées à la suite de l'utilisation des instructions LMD (langage de manipulation de données) suivantes dans GoogleSQL:
- SELECT en relation avec l'un des types de tables listés :
- INSERT SELECT
- MERGE
- MISE À JOUR
- SUPPRIMER
Les tâches de copie, de requête et de chargement BigQuery sont représentées sous forme de processus. Pour afficher les détails du processus, cliquez sur ![]() dans le graphique de traçabilité.
Chaque processus contient le job_id BigQuery dans la liste des attributs pour la tâche BigQuery la plus récente.
dans le graphique de traçabilité.
Chaque processus contient le job_id BigQuery dans la liste des attributs pour la tâche BigQuery la plus récente.
Autres services
La lignée de données est compatible avec les servicesGoogle Cloud suivants:
Traçabilité des données pour les sources de données personnalisées
Vous pouvez utiliser l'API Data Lineage dans Dataplex pour enregistrer manuellement des informations sur la traçabilité pour toute source de données non prise en charge par les systèmes intégrés.
Dataplex peut créer des graphiques de filiation pour la filiation enregistrée manuellement si vous utilisez un fullyQualifiedNames correspondant aux noms complets des entrées Data Catalog existantes. Si vous souhaitez enregistrer la lignée d'une source de données personnalisée, créez d'abord une entrée Data Catalog personnalisée.
Chaque processus pour la source de données personnalisée peut contenir la clé sql dans la liste des attributs. La valeur de cette clé sera utilisée pour afficher la mise en surbrillance du code dans le panneau d'informations du graphique de la lignée des données. L'instruction SQL s'affichera telle qu'elle a été fournie. L'utilisateur est responsable du filtrage des informations sensibles. Le nom de clé sql est sensible à la casse.
OpenLineage
Si vous utilisez déjà OpenLineage pour collecter des informations sur la lignée à partir d'autres sources de données, vous pouvez importer des événements OpenLineage dans Dataplex et les afficher dans la console Google Cloud. Pour en savoir plus, consultez la section Intégrer OpenLineage.
Limites
- Toutes les informations sur la lignée sont conservées dans le système pendant 30 jours seulement.
- Les informations de filiation sont conservées après la suppression de la source de données associée. Autrement dit, si vous supprimez une table BigQuery et son entrée dans Data Catalog, vous pouvez toujours lire la lignée de cette table à l'aide de l'API pendant 30 jours maximum.
Accéder à la traçabilité des données
Vous pouvez accéder aux fonctionnalités de traçabilité des données à l'aide des éléments suivants:
- Page "Détails de l'entrée" dans l'interface Web Dataplex de la console Google Cloud. Consultez Afficher les graphiques de traçabilité.
- Page d'informations sur la table dans l'interface Web BigQuery de la console Google Cloud. Consultez Afficher les graphiques de traçabilité.
- Pages "Dataset" et "Model Registry" dans l'interface Web Vertex AI de la console Google Cloud. Consultez Afficher les graphiques de traçabilité.
- API Data Lineage
Tarifs
Dataplex utilise le SKU de traitement Premium pour facturer la traçabilité des données. Pour en savoir plus, reportez-vous à la section Tarification.
Pour séparer les frais de lignée de données des autres frais dans le SKU de traitement premium Dataplex, dans le rapport de facturation Cloud, utilisez le libellé
goog-dataplex-workload-typeavec la valeurLINEAGE.Si vous appelez l'API Data Lineage
OriginsourceTypeavec une valeur autre queCUSTOM, cela entraîne des coûts supplémentaires.
Étape suivante
Découvrez comment suivre la lignée des données pour une copie de table BigQuery et des tâches de requête.
Découvrez comment utiliser la traçabilité des données avec les systèmes Google Cloud .
Pour en savoir plus sur l'administration, consultez les sections IAM mises à jour, les considérations concernant la lignée et la journalisation des audits de la lignée des données.