BigQuery DataFrames를 사용하여 그래프 시각화
이 문서에서는 BigQuery DataFrames 시각화 라이브러리를 사용하여 다양한 유형의 그래프를 그리는 방법을 보여줍니다.
bigframes.pandas API는 Python을 위한 전체 도구 생태계를 제공합니다. 이 API는 고급 통계 작업을 지원하며, BigQuery DataFrames에서 생성된 집계를 시각화할 수 있습니다. BigQuery DataFrames에서 내장 샘플링 작업이 있는 pandas DataFrame으로 전환할 수도 있습니다.
히스토그램
다음 예시에서는 bigquery-public-data.ml_datasets.penguins 테이블에서 데이터를 읽어 펭귄 부리 깊이 분포에 대한 히스토그램을 플롯합니다.

선 차트
다음 예에서는 bigquery-public-data.noaa_gsod.gsod2021 테이블의 데이터를 사용하여 연중 중앙값 온도 변화의 선 차트를 플롯합니다.

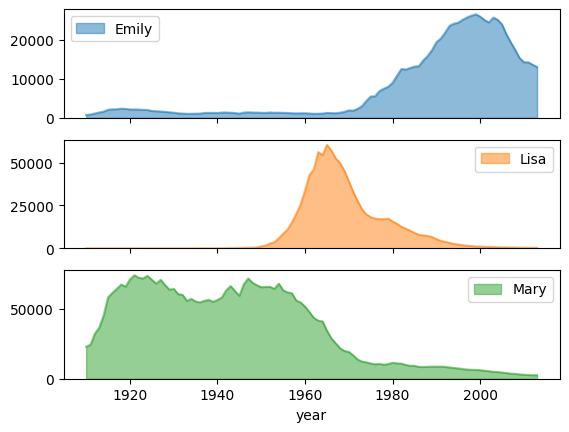
영역 차트
다음 예에서는 bigquery-public-data.usa_names.usa_1910_2013 테이블을 사용하여 미국 역사상 이름의 인기를 추적하고 Mary, Emily, Lisa 이름에 중점을 둡니다.

막대 차트
다음 예에서는 bigquery-public-data.ml_datasets.penguins 테이블을 사용하여 펭귄 성별의 분포를 시각화합니다.

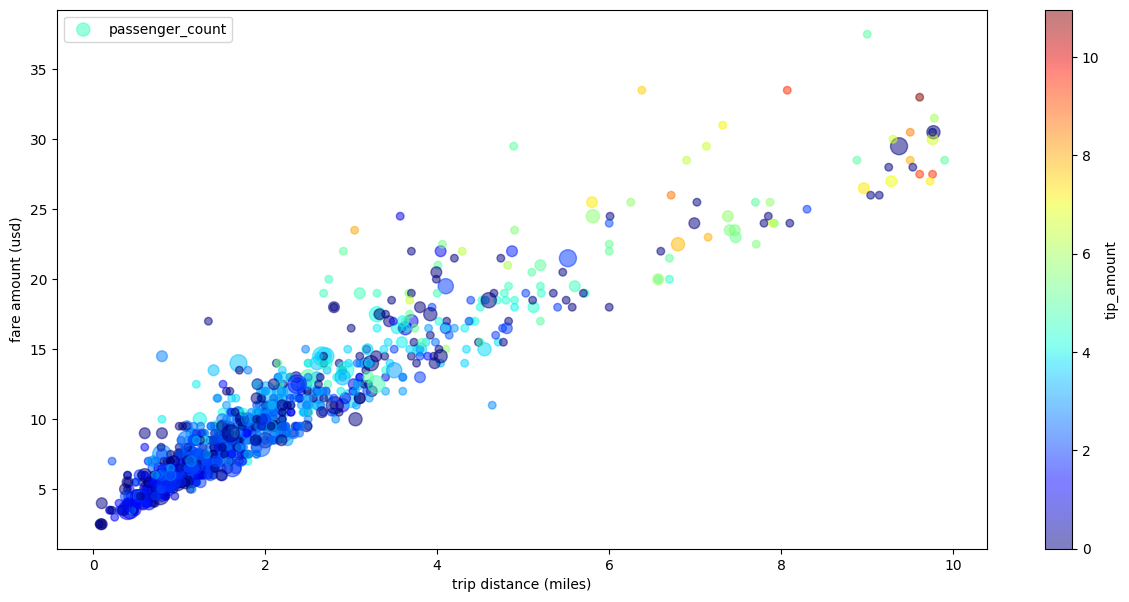
분산형 차트
다음 예에서는 bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021 테이블을 사용하여 택시 요금과 이동 거리 간의 관계를 살펴봅니다.

대규모 데이터 세트 시각화
BigQuery DataFrames는 시각화를 위해 데이터를 로컬 머신에 다운로드합니다. 다운로드할 데이터 포인트 수는 기본적으로 1,000개로 제한됩니다. 데이터 포인트 수가 상한을 초과하면 BigQuery DataFrames는 상한과 동일한 수의 데이터 포인트를 무작위로 샘플링합니다.
다음 예와 같이 그래프를 플롯할 때 sampling_n 매개변수를 설정하여 이 상한을 재정의할 수 있습니다.

Pandas 및 Matplotlib 매개변수를 사용한 고급 플로팅
BigQuery DataFrames의 플로팅 라이브러리는 Pandas와 Matplotlib로 구동되므로 Pandas에서와 마찬가지로 더 많은 매개변수를 전달하여 그래프를 미세 조정할 수 있습니다. 다음 섹션에서는 예를 설명합니다.
subplots를 사용한 이름 인기 추세
영역 차트 예시의 이름 기록 데이터를 사용하여 다음 예시에서는 plot.area() 함수 호출에서 subplots=True를 설정하여 각 이름에 대한 개별 그래프를 만듭니다.
여러 측정기준이 있는 택시 운행 분산형 차트
분산형 차트 예시의 데이터를 사용하여 다음 예에서는 x축과 y축의 라벨 이름을 바꾸고, 점 크기에 passenger_count 매개변수를 사용하고, tip_amount 매개변수로 색상 점을 사용하고, 그림 크기를 조정합니다.
다음 단계
- BigQuery DataFrames 사용 방법 알아보기
- dbt에서 BigQuery DataFrames를 사용하는 방법 알아보기
- BigQuery DataFrames API 참조 살펴보기