Cuando optimices el rendimiento de una aplicación, ten en cuenta su uso de NDB. Por ejemplo, si una aplicación lee un valor que no está en la caché, esa lectura tarda un tiempo. Puedes acelerar tu aplicación ejecutando acciones de Datastore en paralelo con otras tareas o ejecutando varias acciones de Datastore en paralelo entre sí.
La biblioteca de cliente NDB proporciona muchas funciones asíncronas ("async").
Cada una de estas funciones permite que una aplicación envíe una solicitud a Datastore. La función devuelve
inmediatamente un objeto
Future. La aplicación puede hacer otras cosas mientras Datastore gestiona la solicitud.
Una vez que Datastore haya gestionado la solicitud, la aplicación podrá obtener los resultados del objeto Future.
Introducción
Supongamos que uno de los controladores de solicitudes de tu aplicación necesita usar NDB para escribir algo, quizás para registrar la solicitud. También debe llevar a cabo otras operaciones de NDB, como obtener algunos datos.
Si sustituyes la llamada a put() por una llamada a su equivalente asíncrono put_async(), la aplicación podrá hacer otras cosas inmediatamente en lugar de bloquearse en put().
De esta forma, las demás funciones de NDB y la renderización de plantillas pueden realizarse mientras Datastore escribe los datos. La aplicación no se bloquea en Datastore hasta que obtiene datos de Datastore.
En este ejemplo, es un poco absurdo llamar a future.get_result:
la aplicación nunca usa el resultado de NDB. Ese código está ahí solo para asegurarse de que el controlador de solicitudes no se cierre antes de que termine NDB put. Si el controlador de solicitudes se cierra demasiado pronto, es posible que la inserción nunca se produzca. Para mayor comodidad, puedes decorar el controlador de solicitudes con @ndb.toplevel. Esto indica al controlador que no debe salir hasta que se hayan completado sus solicitudes asíncronas. De esta forma, puedes enviar la solicitud y no preocuparte por el resultado.
Puedes especificar un WSGIApplication completo como ndb.toplevel. De esta forma, cada uno de los controladores de WSGIApplication espera a que se completen todas las solicitudes asíncronas antes de devolver el resultado.
No se aplica a todos los controladores de WSGIApplication.
Usar una aplicación toplevel es más cómodo que
todas sus funciones de controlador. Sin embargo, si un método de controlador usa yield,
ese método debe envolverse en otro decorador,
@ndb.synctasklet; de lo contrario, dejará de ejecutarse en
el yield y no finalizará.
Usar APIs asíncronas y Futures
Casi todas las funciones síncronas de NDB tienen una contraparte _async. Por ejemplo, put() tiene put_async().
Los argumentos de la función asíncrona siempre son los mismos que los de la versión síncrona.
El valor devuelto de un método asíncrono siempre es un Future o (en el caso de las funciones "multi") una lista de Futures.
Un Future es un objeto que mantiene el estado de una operación
que se ha iniciado, pero que puede que aún no se haya completado. Todas las APIs asíncronas
devuelven uno o varios Futures.
Puedes llamar a la función get_result() de Future para pedirle el resultado de su operación. A continuación, Future se bloquea, si es necesario, hasta que el resultado esté disponible y, después, te lo proporciona.
get_result() devuelve el valor que devolvería la versión síncrona de la API.
Nota:
Si has usado Futures en otros lenguajes de programación, puede que pienses que puedes usar un Future directamente como resultado. Eso no funciona aquí.
Estos lenguajes usan
futuros implícitos, mientras que NDB usa futuros explícitos.
Llama al get_result() para obtener el resultado de una prueba de drogas en el trabajo Future.
¿Qué ocurre si la operación genera una excepción? Depende de cuándo se produzca la excepción. Si NDB detecta un problema al hacer una solicitud
(quizá un argumento del tipo incorrecto), el método _async()
genera una excepción. Sin embargo, si la excepción la detecta, por ejemplo, el servidor de Datastore, el método _async() devuelve un Future y la excepción se generará cuando tu aplicación llame a su get_result(). No te preocupes demasiado por esto, ya que todo acaba funcionando de forma bastante natural. Quizá la mayor diferencia es que, si se imprime un traceback, verás algunas partes de la maquinaria asíncrona de bajo nivel expuestas.
Por ejemplo, supongamos que estás escribiendo una aplicación de libro de visitas. Si el usuario ha iniciado sesión, quieres mostrar una página con las entradas más recientes del libro de visitas. En esta página también se debe mostrar el nombre de usuario. La aplicación necesita dos tipos de información: la información de la cuenta del usuario que ha iniciado sesión y el contenido de las entradas del libro de visitas. La versión "síncrona" de esta aplicación podría ser la siguiente:
Aquí hay dos acciones de E/S independientes: obtener la entidad Account y obtener las entidades Guestbook recientes. Con la API síncrona, estos procesos se llevan a cabo uno después del otro. Esperamos a recibir la información de la cuenta antes de obtener las entidades del libro de visitas. Sin embargo, la aplicación no necesita la información de la cuenta de inmediato. Podemos aprovechar esta situación y usar APIs asíncronas:
Esta versión del código primero crea dos Futures
(acct_future y recent_entries_future)
y, a continuación, espera a que se completen. El servidor trabaja en ambas solicitudes en paralelo.
Cada llamada a la función _async() crea un objeto Future
y envía una solicitud al servidor de Datastore. El servidor puede empezar a trabajar en la solicitud de inmediato. Las respuestas del servidor pueden devolverse en cualquier orden arbitrario. El objeto Future vincula las respuestas a sus solicitudes correspondientes.
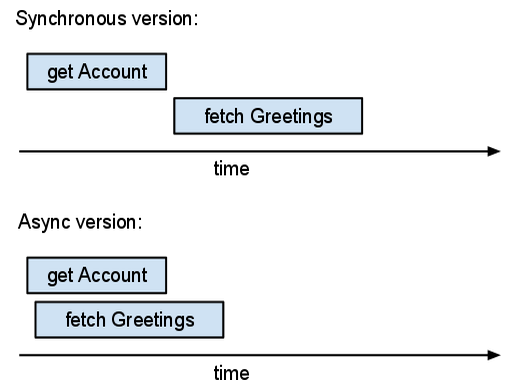
El tiempo total (real) empleado en la versión asíncrona es aproximadamente igual al tiempo máximo de las operaciones. El tiempo total empleado en la versión síncrona supera la suma de los tiempos de las operaciones. Si puedes ejecutar más operaciones en paralelo, las operaciones asíncronas te serán de más ayuda.
Para ver cuánto tardan las consultas de tu aplicación o cuántas operaciones de E/S realiza por solicitud, puedes usar Appstats. Esta herramienta puede mostrar gráficos similares al dibujo anterior en función de la instrumentación de una aplicación activa.
Usar tasklets
Un tasklet de NDB es un fragmento de código que puede ejecutarse simultáneamente con otro código. Si escribes un tasklet, tu aplicación puede usarlo de forma muy similar a como usa una función NDB asíncrona: llama al tasklet, que devuelve un Future. Más adelante, al llamar al método get_result() del Future, se obtiene el resultado.
Los tasklets son una forma de escribir funciones simultáneas sin hilos. Un bucle de eventos ejecuta los tasklets, que pueden suspenderse a sí mismos para bloquear las operaciones de E/S u otras operaciones mediante una instrucción yield. La noción de operación de bloqueo se abstrae en la clase Future, pero una tarea también puede yield una
RPC para esperar a que se complete.
Cuando el tasklet tiene un resultado, raise una excepción ndb.Return; NDB asocia el resultado con el Future yield anterior.
Cuando escribes un tasklet de NDB, usas yield y raise de una forma poco habitual. Por lo tanto, si buscas ejemplos de cómo usarlos, probablemente no encontrarás código como un tasklet de NDB.
Para convertir una función en una tarea de NDB, sigue estos pasos:
- decorar la función con
@ndb.tasklet, - sustituir todas las llamadas al almacén de datos síncrono por
yields de llamadas al almacén de datos asíncrono, - hacer que la función "devuelva" su valor de retorno con
raise ndb.Return(retval)(no es necesario si la función no devuelve nada).
Una aplicación puede usar tasklets para tener un control más preciso sobre las APIs asíncronas. Por ejemplo, supongamos que se da el siguiente esquema:
...
Cuando se muestra un mensaje, es lógico que se muestre el alias del autor. La forma "síncrona" de obtener los datos para mostrar una lista de mensajes podría ser la siguiente:
Por desgracia, este método es ineficiente. Si lo consultaras en Appstats, verías que las solicitudes "Get" están en serie. Es posible que veas el siguiente patrón de "escalera".
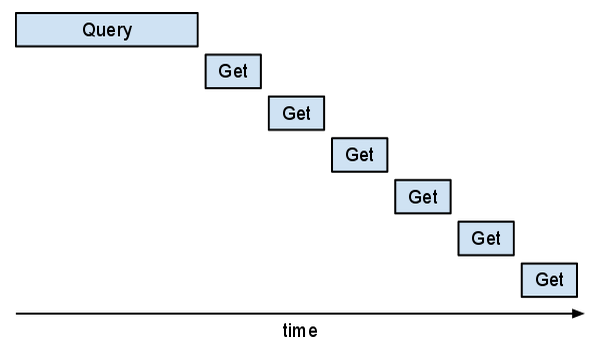
Esta parte del programa sería más rápida si esos "Gets" pudieran superponerse.
Podrías reescribir el código para usar get_async, pero es
difícil hacer un seguimiento de qué solicitudes y mensajes asíncronos van juntos.
La aplicación puede definir su propia función "async" convirtiéndola en un tasklet. De esta forma, puedes organizar el código de una forma menos confusa.
Además, en lugar de usar
acct = key.get() o
acct = key.get_async().get_result(),
la función debería usar
acct = yield key.get_async().
Este yield indica a NDB que es un buen lugar para suspender este tasklet y permitir que se ejecuten otros.
Al decorar una función de generador con @ndb.tasklet,
la función devuelve un Future en lugar de un
objeto de generador. En el tasklet, cualquier yield de un
Future espera y devuelve el resultado del Future.
Por ejemplo:
Ten en cuenta que, aunque get_async() devuelve un Future, el framework de tasklets hace que la expresión yield devuelva el resultado de Future a la variable acct.
map() llama a callback() varias veces.
Sin embargo, el yield ..._async() de callback()
permite que el programador de NDB envíe muchas solicitudes asíncronas antes de esperar a que
finalice alguna de ellas.
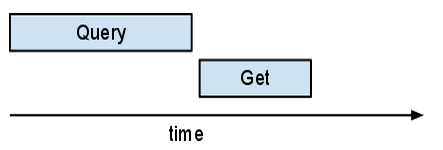
Si lo examinas en Appstats, te sorprenderá ver que estas múltiples solicitudes Get no solo se superponen, sino que se completan en la misma solicitud. NDB implementa un autobatcher. El autobatcher agrupa varias solicitudes en un solo lote de RPC al servidor. Lo hace de tal forma que, mientras haya más trabajo por hacer (se puede ejecutar otra retrollamada), recoge claves. En cuanto se necesita uno de los resultados, el autobatcher envía el RPC por lotes. A diferencia de la mayoría de las solicitudes, las consultas no se agrupan en lotes.
Cuando se ejecuta un tasklet, obtiene su espacio de nombres predeterminado de el valor predeterminado que tenía cuando se generó el tasklet o el valor al que lo cambió el tasklet durante la ejecución. En otras palabras, el espacio de nombres predeterminado no está asociado ni almacenado en Context, y cambiar el espacio de nombres predeterminado en un tasklet no afecta al espacio de nombres predeterminado de otros tasklets, excepto a los que haya generado.
Tasklets, consultas paralelas y resultados paralelos
Puedes usar tasklets para que varias consultas obtengan registros al mismo tiempo. Por ejemplo, supongamos que tu aplicación tiene una página que muestra el contenido de un carrito de la compra y una lista de ofertas especiales. El esquema podría tener este aspecto:
Una función "síncrona" que obtiene artículos del carrito de la compra y ofertas especiales podría tener el siguiente aspecto:
En este ejemplo se usan consultas para obtener listas de artículos del carrito y ofertas. A continuación, se obtienen detalles sobre los artículos del inventario con get_multi().
(Esta función no usa
el valor devuelto de get_multi() directamente. Llama a get_multi() para obtener todos los detalles del inventario en la caché, de modo que se puedan leer rápidamente más adelante. get_multi
combina muchas Gets en una sola solicitud. Sin embargo, las consultas se realizan una tras otra. Para que esas peticiones se produzcan al mismo tiempo, superpón las dos consultas:
La llamada get_multi()
sigue siendo independiente: depende de los resultados de la consulta, por lo que no puedes combinarla con las consultas.
Supongamos que esta aplicación a veces necesita el carrito, a veces las ofertas y a veces ambos. Quieres organizar el código de forma que haya una función para obtener el carrito y otra para obtener las ofertas. Si tu aplicación llama a estas funciones juntas, lo ideal sería que sus consultas se "solaparan". Para ello, convierte estas funciones en tasklets:
Ese yield x, y es importante, pero fácil de pasar por alto. Si fueran dos instrucciones yield
independientes, se ejecutarían en serie. Sin embargo, yield una tupla
de tasklets es un yield paralelo: los tasklets se pueden ejecutar en paralelo
y yield espera a que todos terminen y devuelve
los resultados. En algunos lenguajes de programación, se conoce como barrera.
Si conviertes un fragmento de código en un tasklet, probablemente quieras hacer más pronto. Si detectas código "síncrono" que podría ejecutarse en paralelo con un tasklet, probablemente sea una buena idea convertirlo también en un tasklet.
Después, puedes paralelizarlo con un yield paralelo.
Si escribes una función de solicitud (una función de solicitud de webapp2, una función de vista de Django, etc.) para que sea un tasklet, no hará lo que quieres: se detendrá después de generar el resultado. En esta situación, quieres decorar la función con
@ndb.synctasklet.
@ndb.synctasklet es como @ndb.tasklet, pero se ha modificado para llamar a get_result() en el tasklet.
De esta forma, tu tasklet se convierte en una función que devuelve su resultado de la forma habitual.
Iteradores de consultas en tasklets
Para iterar los resultados de una consulta en un tasklet, usa el siguiente patrón:
Es el equivalente compatible con tasklets de lo siguiente:
Las tres líneas en negrita de la primera versión son el equivalente
de la línea en negrita de la segunda versión.
Los tasklets solo se pueden suspender en una palabra clave yield.
El bucle for sin yield no permite que se ejecuten otros tasklets.
Puede que te preguntes por qué este código usa un iterador de consultas en lugar de
obtener todas las entidades con qry.fetch_async().
Es posible que la aplicación tenga tantas entidades que no quepan en la RAM.
Quizá estés buscando una entidad y puedas dejar de iterar una vez que la encuentres, pero no puedes expresar tus criterios de búsqueda solo con el lenguaje de consulta. Puedes usar un iterador para cargar entidades que quieras comprobar y, a continuación, salir del bucle cuando encuentres lo que buscas.
Urlfetch asíncrono con NDB
Un Context de NDB tiene una función urlfetch() asíncrona que se paraleliza bien con los tasklets de NDB. Por ejemplo:
El servicio de obtención de URL tiene su propia API de solicitudes asíncronas. Está bien, pero no siempre es fácil de usar con los tasklets de NDB.
Usar transacciones asíncronas
Las transacciones también se pueden realizar de forma asíncrona. Puedes pasar una función que ya tengas a ndb.transaction_async() o usar el decorador @ndb.transactional_async.
Al igual que las demás funciones asíncronas, esta devolverá un NDB Future:
Las transacciones también funcionan con tasklets. Por ejemplo, podríamos cambiar nuestro código update_counter a yield mientras esperamos las llamadas RPC de bloqueo:
Usar Future.wait_any()
A veces, quieres hacer varias solicitudes asíncronas y devolver el resultado cuando se complete la primera.
Para ello, puedes usar el método de clase ndb.Future.wait_any():
Lamentablemente, no hay una forma sencilla de convertirlo en un tasklet, ya que un yield paralelo espera a que se completen todos los Future, incluidos aquellos por los que no quieres esperar.