データベースのオペレーションを継続させ、ダウンタイムを最小限に抑えるには、高可用性を持つ Patroni の設定の信頼性と品質を確保することが重要です。このページでは、障害のさまざまなシナリオ、レプリケーションの整合性、フェイルオーバーのメカニズムなど、Patroni クラスタのテストに関する包括的なガイドを紹介します。
Patroni の設定をテストする
任意の Patroni インスタンス(
alloydb-patroni1、alloydb-patroni2、alloydb-patroni3)に接続し、AlloyDB Omni Patroni のフォルダに移動します。cd /alloydb/
Patroni のログを調べます。
docker compose logs alloydbomni-patroni
エントリの最終行に Patroni ノードに関する情報が反映されているはずです。出力は次のようになります。
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lockプライマリ Patroni インスタンス
alloydb-patroni1へのネットワーク接続を持ち、Linux を実行している任意のインスタンスに接続して、インスタンスに関する情報を取得します。jqツールのインストールが必要になる場合があります(sudo apt-get install jq -yを実行)。curl -s http://alloydb-patroni1:8008/patroni | jq .
次の例のように表示されます。
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
Patroni ノードで Patroni HTTP API エンドポイントを呼び出すと、Patroni によって管理されている特定の PostgreSQL インスタンスの状態と構成に関するさまざまな詳細情報が公開されます。この情報には、クラスタのステータス情報、タイムライン、WAL 情報、ノードとクラスタが正常に稼働しているかどうかを示すヘルスチェックなどが含まれます。
HAProxy の設定をテストする
ブラウザがインストールされ、HAProxy ノードにネットワーク接続できるマシンで、アドレス
http://haproxy:7000にアクセスします。ホスト名の代わりに HAProxy インスタンスの外部 IP アドレスを使用することもできます。次のスクリーンショットのように表示されます。
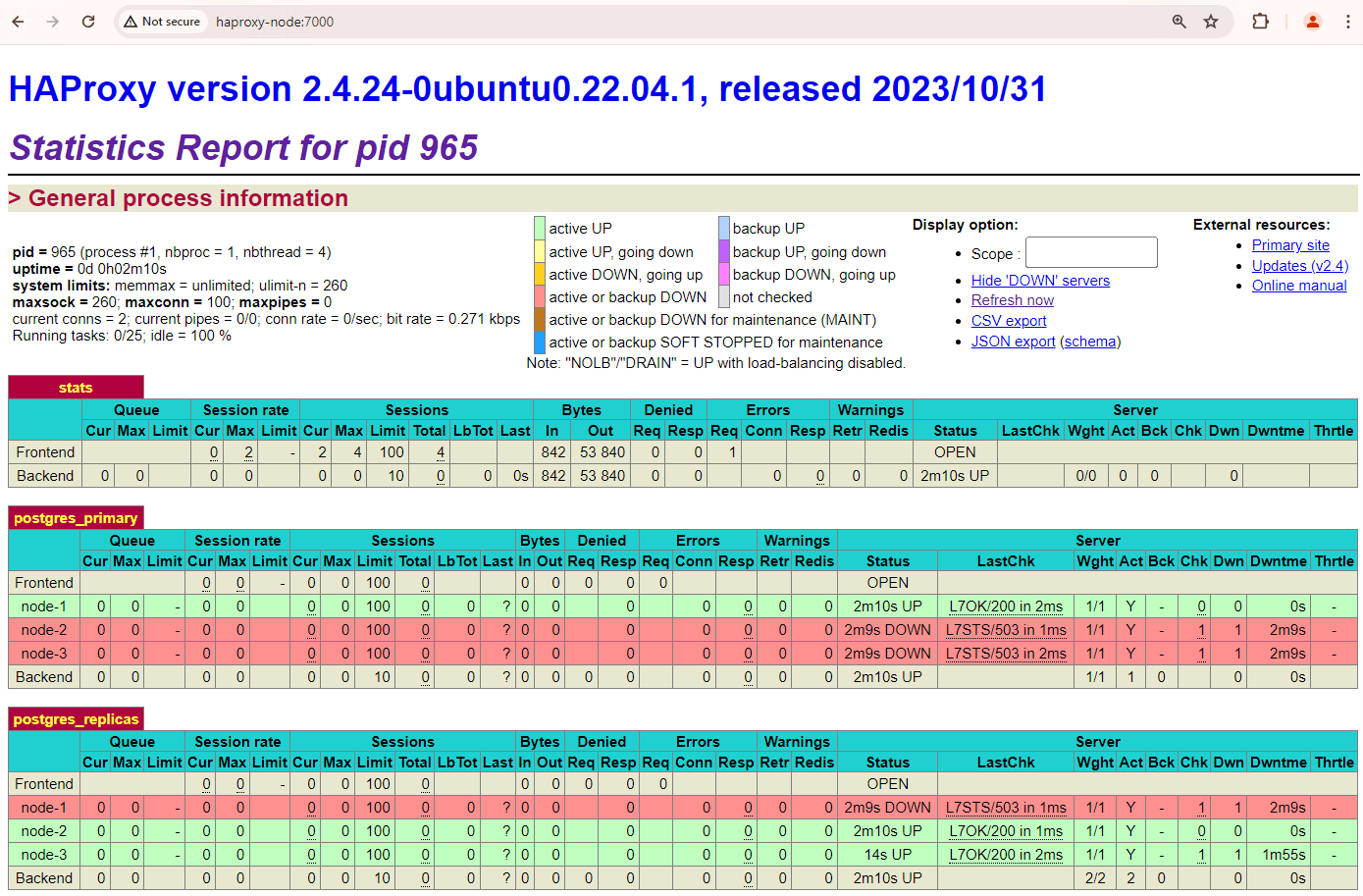
図 1: Patroni ノードのヘルス ステータスとレイテンシを示す HAProxy ステータスのページ。
HAProxy ダッシュボードには、プライマリ Patroni ノード
patroni1と 2 つのレプリカpatroni2とpatroni3のヘルス ステータスとレイテンシが表示されます。クエリを実行して、クラスタのレプリケーション統計情報を確認できます。pgAdmin などのクライアントから HAProxy を介してプライマリ データベース サーバーに接続し、次のクエリを実行します。
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;patroni2とpatroni3がpatroni1からストリーミングされていることを示す、次のような画面が表示されます。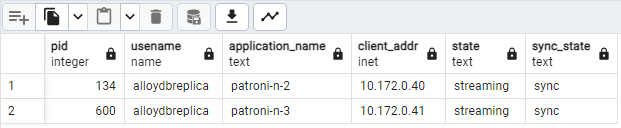
図 2. Patroni ノードのレプリケーション ステータスを示す pg_stat_replication の出力。
自動フェイルオーバーをテストする
このセクションでは、ノードが 3 つあるクラスタで、接続された実行中の Patroni コンテナを停止してプライマリ ノードの停止をシミュレートします。プライマリで Patroni サービスを停止してサービスの停止をシミュレートすることも、ファイアウォール ルールを適用してそのノードへの通信を停止することもできます。
プライマリ Patroni インスタンスで、AlloyDB Omni Patroni のフォルダに移動します。
cd /alloydb/
コンテナを停止します。
docker compose down
次のように出力されます。これにより、コンテナとネットワークが停止したことがわかります。
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default RemovedHAProxy ダッシュボードを更新して、フェイルオーバーがどのように行われるかを確認します。
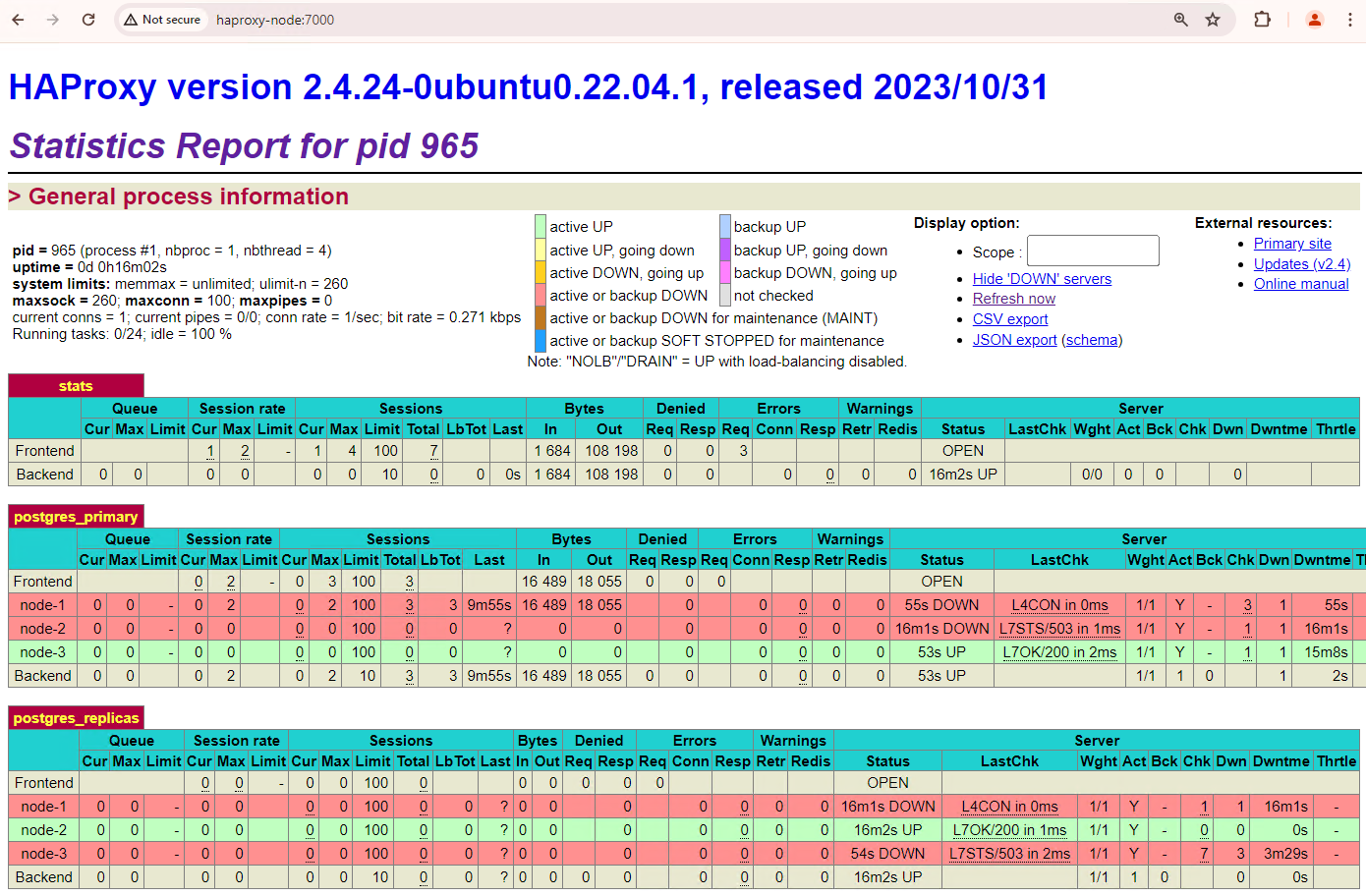
図 3. プライマリ ノードからスタンバイ ノードへのフェイルオーバーを示す HAProxy ダッシュボード。
patroni3インスタンスが新しいプライマリになり、残るレプリカはpatroni2のみになりました。以前のプライマリpatroni1は停止され、ヘルスチェックが失敗します。Patroni では、モニタリング、コンセンサス、自動オーケストレーションの組み合わせによりフェイルオーバーが実行、管理されます。指定したタイムアウトの時間内にプライマリ ノードによりリースが更新されなかった場合、またはプライマリ ノードにより失敗が報告された場合、クラスタ内の他のノードはコンセンサス システムを介してこの状態を把握します。残りのノードでは、新しいプライマリとしてプロモートする最も適切なレプリカを選択するために調整が行われます。候補となるレプリカが決まると、Patroni は PostgreSQL 構成の更新や未処理の WAL レコードの再生といった必要な変更を適用して、このノードをプライマリにプロモートします。次に、新しいプライマリ ノードはコンセンサス システムを自身のステータスで更新します。他のレプリカは、レプリケーション ソースを切り替えたり、新しいトランザクションに追いついたりするなど、新しいプライマリに従うように再構成を行います。HAProxy は新しいプライマリ ノードを検出し、それに応じてクライアント接続をリダイレクトして、サービスの停止を最小限に抑えます。
pgAdmin などのクライアントから HAProxy を介してデータベース サーバーに接続し、フェイルオーバー後のクラスタのレプリケーション統計情報を確認します。
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;現在
patroni2のみがストリーミングされていることを示す、次のような画面が表示されます。
図 4. フェイルオーバー後の Patroni ノードのレプリケーション ステータスを示す pg_stat_replication の出力。
このクラスタにはノードが 3 つあるので、サービスの停止をあと 1 回許容できます。現在のプライマリ ノード
patroni3を停止すると、別のフェイルオーバーが発生します。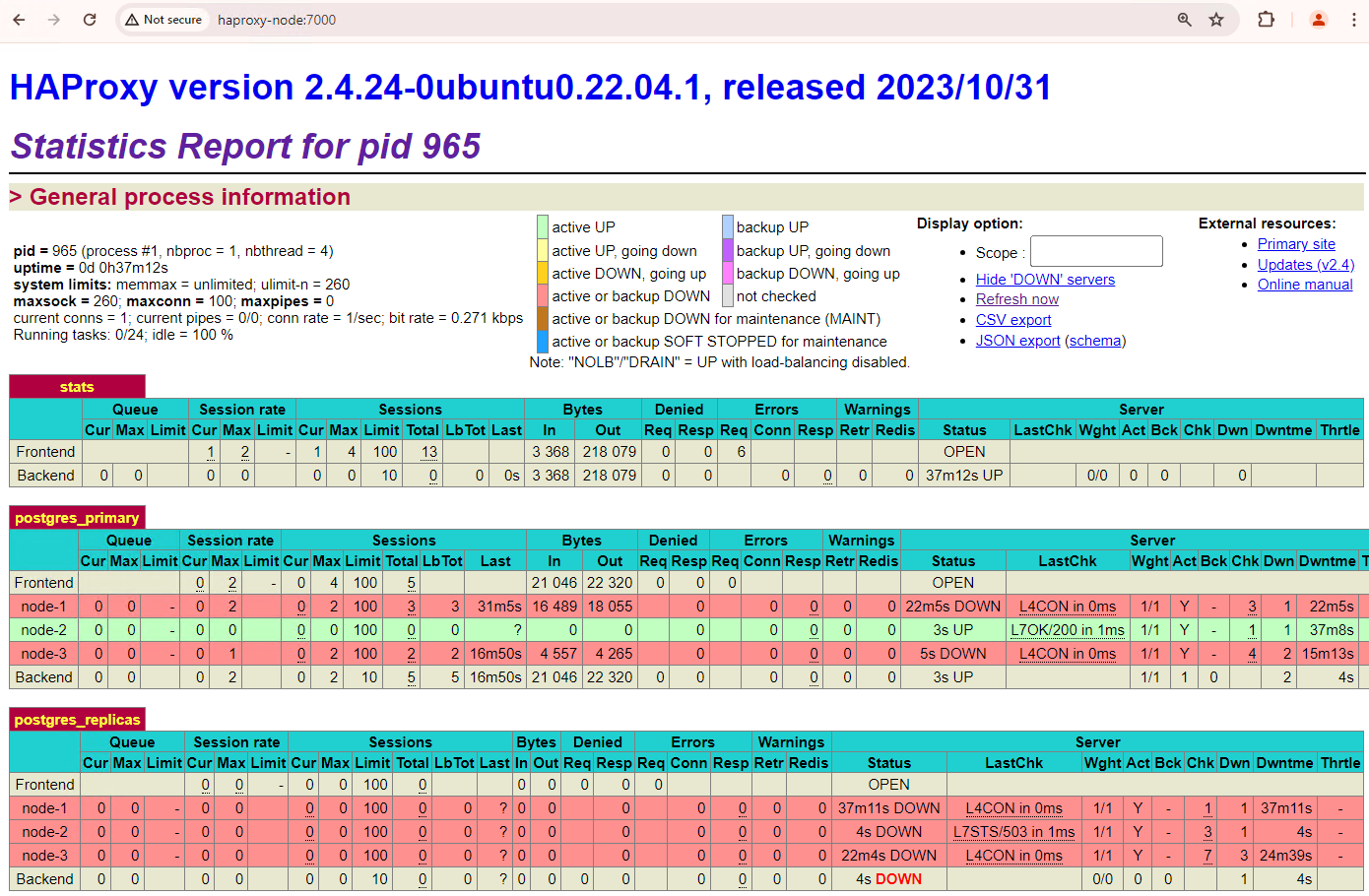
図 5. プライマリ ノード
patroni3からスタンバイ ノードpatroni2へのフェイルオーバーを示す HAProxy ダッシュボード。
フォールバックに関する考慮事項
フォールバックとは、フェイルオーバーが発生した後に以前のソースノードを復元するプロセスです。通常、高可用性データベース クラスタでは自動フォールバックはおすすめしません。復元が不完全であること、スプリットブレインのシナリオが発生するリスクがあること、レプリケーションでラグが発生するリスクがあることなど、重大な懸念がいくつかあるためです。
Patroni クラスタで、サービスの停止をシミュレートした 2 つのノードを起動すると、これらのノードはスタンバイ レプリカとしてクラスタに再参加します。
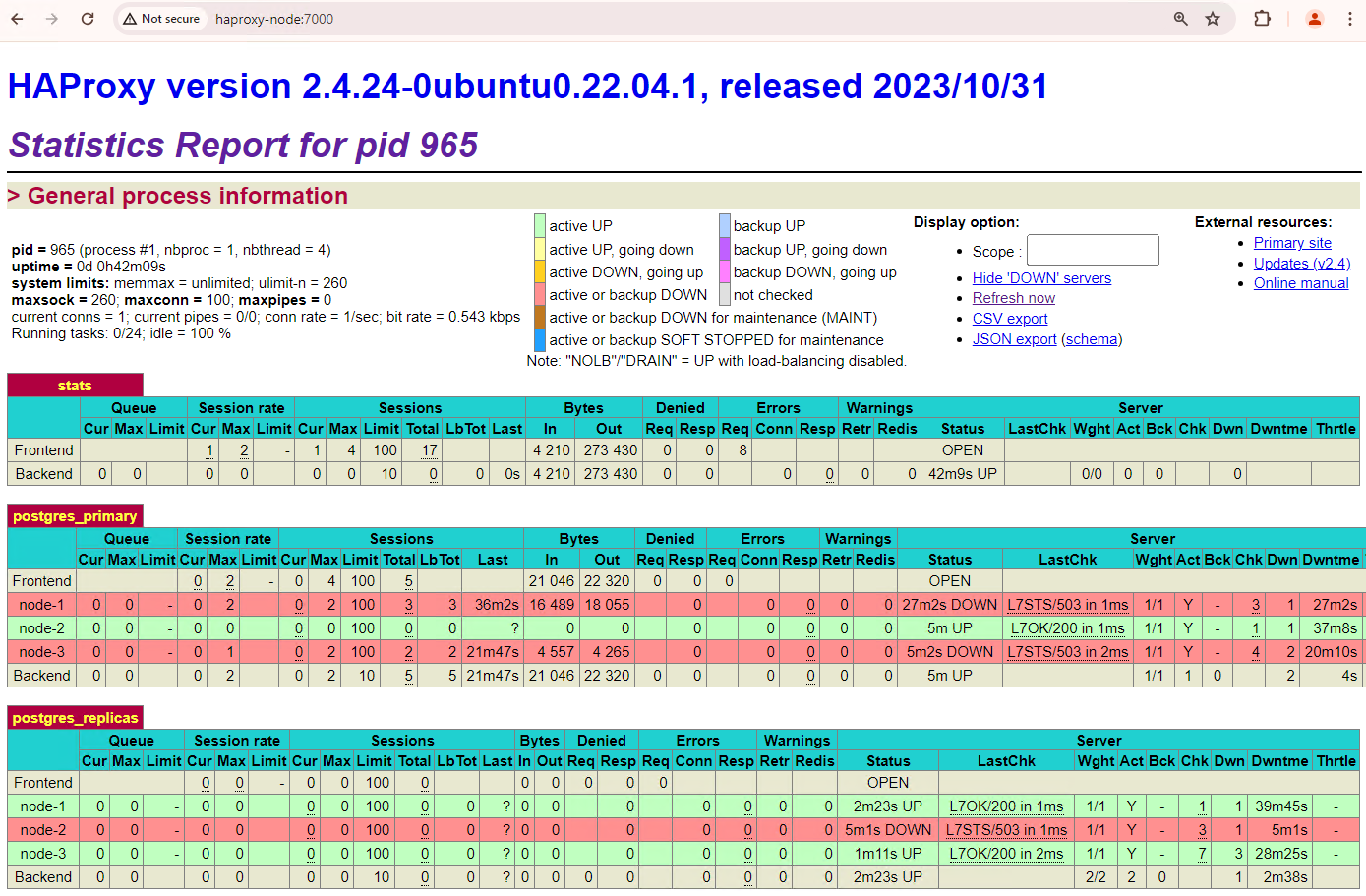
図 6: patroni1 と patroni3 がスタンバイ ノードとして復元されたことを示す HAProxy ダッシュボード。
これで、patroni1 と patroni3 が現在のプライマリ patroni2 から複製されました。

図 7. フォールバック後の Patroni ノードのレプリケーション状態を示す pg_stat_replication の出力。
初期プライマリに手動でフォールバックする場合は、patronictl コマンドライン インターフェースを使用します。手動フォールバックを使用すると、より信頼性が高く、一貫性があり、徹底的に検証された復元プロセスを確保し、データベース システムの完全性と可用性を維持できます。