O AI Platform Pipelines permite orquestrar seus fluxos de trabalho de machine learning (ML) como pipelines reutilizáveis e reproduzíveis. O AI Platform Pipelines evita que você precise configurar o Kubeflow Pipelines com o TensorFlow Extended no Google Kubernetes Engine.
Neste guia, descrevemos várias opções para implantar o AI Platform Pipelines no GKE. É possível implantar o Kubeflow Pipelines em um cluster atual do GKE ou criar um novo cluster do GKE. Se você quiser reutilizar um cluster existente do GKE, verifique se ele atende os seguintes requisitos:
- Seu cluster precisa ter pelo menos três nós. Cada nó precisa ter pelo menos duas CPUs e quatro GB de memória disponíveis.
- O escopo de acesso do cluster precisa conceder acesso total a todas as APIs do Cloud ou o cluster precisa usar uma conta de serviço personalizada.
- O cluster ainda não pode ter o Kubeflow Pipelines instalado.
Selecione a melhor opção de implantação para sua situação:
- Use o AI Platform Pipelines para criar um novo cluster do GKE com acesso total ao Google Cloud e implantar o Kubeflow Pipelines no cluster. Essa opção facilita a implantação e o uso do AI Platform Pipelines.
- Crie um novo cluster do GKE com acesso granular ao Google Cloud e implante o Kubeflow Pipelines nesse cluster. Essa opção permite especificar os recursos e as APIs do Google Cloud a que as cargas de trabalho no cluster têm acesso.
- Implantar o AI Platform Pipelines em um cluster do GKE existente. Esta opção descreve como implantar o AI Platform Pipelines em um cluster do GKE existente.
Antes de começar
Antes de seguir este guia, verifique se o projeto Google Cloud está configurado corretamente e se você tem permissões suficientes para implantar o AI Platform Pipelines.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Use as instruções a seguir para verificar se você recebeu os
papéis necessários para implantar o AI Platform Pipelines.
-
Abra uma sessão do Cloud Shell.
O Cloud Shell é aberto em um frame na parte inferior do Console do Google Cloud.
-
É necessário ter os papéis de Visualizador (
roles/viewer) e de administrador do Kubernetes Engine (roles/container.admin) no projeto ou outros papéis com as mesmas permissões, como Proprietário (roles/owner) no projeto, para implantar o AI Platform Pipelines. Execute o comando a seguir no Cloud Shell para listar os principais com os papéis de Visualizador e Administrador do Kubernetes Engine.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/container.admin OR bindings.role:roles/viewer"
Substitua PROJECT_ID pelo ID do projeto do Google Cloud.
Use a saída desse comando para verificar se sua conta tem os papéis de Visualizador e Administrador do Kubernetes Engine.
-
Se você quiser conceder acesso granular ao cluster, também precisará ter o papel de Administrador da conta de serviço (
roles/iam.serviceAccountAdmin) no projeto ou outros papéis com as mesmas permissões, como o Editor. (roles/editor) ou Proprietário (roles/owner) no projeto. Execute o seguinte comando no Cloud Shell para listar os principais que têm o papel "Administrador da conta de serviço".gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/iam.serviceAccountAdmin"
Substitua PROJECT_ID pelo ID do projeto do Google Cloud.
Use a saída desse comando para verificar se sua conta tem o papel "Administrador da conta de serviço".
-
Se você não recebeu os papéis necessários, entre em contato com o administrador do projeto do Google Cloud para receber mais ajuda.
Saiba mais sobre como conceder papéis de gerenciamento de identidade e acesso.
-
Implantar o AI Platform Pipelines com acesso total a Google Cloud
O AI Platform Pipelines facilita a configuração e o uso do Kubeflow Pipelines
criando um cluster do GKE para você e implantando
o Kubeflow Pipelines no cluster. Quando o AI Platform Pipelines cria um
cluster do GKE, ele usa a
conta de serviço padrão do Compute Engine. Para conceder ao cluster acesso total aos
recursos e APIs Google Cloud que você ativou no projeto, é
possível conceder ao cluster o
escopo de acesso https://www.googleapis.com/auth/cloud-platform. Conceder acesso
dessa maneira permite que os pipelines de ML executados no cluster acessem APIs Google Cloud, como o AI Platform Training e o AI Platform Prediction. Embora esse
processo facilite a configuração do AI Platform Pipelines, ele pode conceder aos desenvolvedores de
pipeline acesso excessivo aos recursos e às APIs do Google Cloud .
Use as instruções a seguir para implantar o AI Platform Pipelines com acesso total aos recursos e às APIs do Google Cloud .
Abra o AI Platform Pipelines no console do Google Cloud.
Na barra de ferramentas dos AI Platform Pipelines, clique em Nova instância. Os pipelines do Kubeflow serão abertos no Google Cloud Marketplace.
Clique em Configurar. O formulário Implantar o Kubeflow Pipelines (em inglês) será aberto.
Clique em Criar um novo cluster, se o link for exibido. Caso não for, vá para a próxima etapa.

Selecione a Zona de cluster em que seu cluster deve estar localizado. Para ajuda sobre como decidir qual zona usar, leia as práticas recomendadas para seleção de região.
Marque Permitir acesso às seguintes APIs do Cloud para conceder acesso aos recursos do Google Cloud aos aplicativos executados no cluster do GKE. Ao marcar essa caixa, você concede ao cluster acesso ao escopo de acesso
https://www.googleapis.com/auth/cloud-platform. Esse escopo de acesso fornece acesso total aos recursos do Google Cloud ativados no projeto. Conceder ao cluster acesso aos recursos do Google Cloud dessa maneira evita que você crie e gerencie uma conta de serviço ou crie um secret do Kubernetes.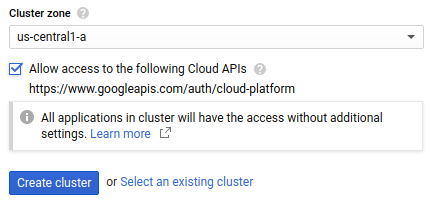
Clique em Criar cluster. Esta etapa pode levar alguns minutos.
Os namespaces são usados para gerenciar recursos em clusters grandes do GKE. Se você não planeja utilizar namespaces no cluster, selecione padrão na lista suspensa Namespace.
Se você planeja usar namespaces no cluster do GKE, crie um namespace usando a lista suspensa Namespace. Para criar um namespace:
- Selecione Criar um namespace na lista suspensa Namespace. A caixa Novo nome do namespace é exibida.
- Digite o nome do namespace em Novo nome do namespace.
Para saber mais sobre namespaces, leia uma postagem do blog sobre como organizar o Kubernetes com namespaces (em inglês).
Na caixa Nome da instância do app, insira um nome para a instância do Kubeflow Pipelines.
O armazenamento gerenciado permite armazenar os metadados e artefatos do pipeline de ML por meio do Cloud SQL e do Cloud Storage, em vez de armazená-los em discos permanentes do Compute Engine. O uso de serviços gerenciados para armazenar os artefatos e metadados do pipeline facilita o backup e a restauração dos dados do cluster. Para implantar o Kubeflow Pipelines com armazenamento gerenciado, selecione Usar armazenamento gerenciado e forneça as seguintes informações:
Bucket do Cloud Storage para armazenamento de artefatos: com o armazenamento gerenciado, o Kubeflow Pipelines armazena artefatos de pipeline em um bucket do Cloud Storage. Especifique o nome do bucket em que você quer que o Kubeflow Pipelines armazene artefatos. Se o bucket especificado não existir, o implantador do Kubeflow Pipelines criará automaticamente um bucket para você na região
us-central1.Nome da conexão da instância do Cloud SQL: com o armazenamento gerenciado, o Kubeflow Pipelines armazena metadados do pipeline em um banco de dados MySQL no Cloud SQL. Especifique o nome da conexão para sua instância do MySQL do Cloud SQL.
Nome de usuário do banco de dados: especifique o nome de usuário do banco de dados que será usado pelo Kubeflow Pipelines ao se conectar à instância do MySQL. No momento, o usuário do banco de dados precisa ter privilégios
ALLdo MySQL para implantar o Kubeflow Pipelines com armazenamento gerenciado. Se você deixar esse campo em branco, o valor padrão será raiz.Senha do banco de dados: especifique a senha do banco de dados que será usada pelo Kubeflow Pipelines ao se conectar à instância do MySQL. Se você deixar esse campo em branco, o Kubeflow Pipelines se conectará ao banco de dados sem fornecer uma senha, o que causa falhas quando o nome de usuário especificado exige senha.
Prefixo do nome do banco de dados: especifique o prefixo do nome do banco de dados. O valor do prefixo precisa começar com uma letra e conter apenas letras minúsculas, números e sublinhados.
Durante o processo de implantação, o Kubeflow Pipelines cria dois bancos de dados: "DATABASE_NAME_PREFIX_pipeline" e "DATABASE_NAME_PREFIX_metadata". Se houver bancos de dados com esses nomes na instância do MySQL, o Kubeflow Pipelines reutilizará os bancos de dados existentes. Se esse valor não for especificado, o Nome da instância do app será usado como prefixo do nome do banco de dados.
Clique em Implantar. Essa etapa pode levar alguns minutos.
Para acessar o painel de pipelines, abra o AI Platform Pipelines no console do Google Cloud.
Acesse o AI Platform Pipelines
Em seguida, clique em Abrir painel de pipelines para a instância do AI Platform Pipelines.
Implantar o AI Platform Pipelines com acesso granular a Google Cloud
Os pipelines de ML acessam Google Cloud recursos usando a conta de serviço e o escopo de acesso do pool de nós do cluster do GKE. Atualmente, para limitar o acesso do cluster a recursos Google Cloud específicos, é preciso implantar o AI Platform Pipelines em um cluster do GKE que usa uma conta de serviço gerenciada pelo usuário.
Use as instruções nas seções a seguir para criar e configurar uma conta de serviço, criar um cluster do GKE usando sua conta de serviço e implantar o Kubeflow Pipelines no cluster do GKE.
Criar uma conta de serviço para o cluster do GKE
Use as instruções a seguir para configurar uma conta de serviço para o cluster do GKE.
Abra uma sessão do Cloud Shell.
O Cloud Shell é aberto em um frame na parte inferior do Console do Google Cloud.
Execute os comandos a seguir no Cloud Shell para criar sua conta de serviço e conceder a ela acesso suficiente para executar o AI Platform Pipelines. Saiba mais sobre os papéis necessários para executar o AI Platform Pipelines com uma conta de serviço gerenciada pelo usuário.
export PROJECT=PROJECT_IDexport SERVICE_ACCOUNT=SERVICE_ACCOUNT_NAMEgcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name=$SERVICE_ACCOUNT \ --project=$PROJECTgcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/logging.logWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.metricWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.viewergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/storage.objectViewerSubstitua:
- SERVICE_ACCOUNT_NAME: o nome da conta de serviço a ser criada
- PROJECT_ID: o projeto do Google Cloud onde a conta de serviço é criada
Conceda à conta de serviço acesso a todos os recursos ou APIs do Google Cloud que os pipelines de ML exigem. Saiba mais sobre os papéis do Identity and Access Management e como gerenciar contas de serviço.
Conceda à conta de usuário o papel "Usuário da conta de serviço" (
iam.serviceAccountUser) na conta de serviço.gcloud iam service-accounts add-iam-policy-binding \ "SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com" \ --member=user:USERNAME \ --role=roles/iam.serviceAccountUser
Substitua:
- SERVICE_ACCOUNT_NAME: o nome da conta de serviço
- PROJECT_ID: o projeto do Google Cloud
- USERNAME: seu nome de usuário no Google Cloud.
Configure seu cluster do GKE
Use as instruções a seguir para configurar o cluster do GKE.
Abra o Google Kubernetes Engine no console do Google Cloud.
Clique no botão Criar cluster. O formulário Princípios básicos do cluster é aberto.
Insira o Nome do cluster.
Em Tipo de local, selecione Por zona e selecione a zona pretendida do cluster. Para ajuda sobre como decidir qual zona usar, leia as práticas recomendadas para seleção de região.
No painel de navegação, em Pools de nós, clique em default-pool. O formulário Detalhes do pool de nós é exibido.
Digite o Número de nós a serem criados no cluster. Seu cluster precisa ter três ou mais nós para implantar o AI Platform Pipelines. É necessário ter uma cota de recursos disponível para os nós e os recursos deles (como rotas de firewall).
No painel de navegação, em Pools de nós, clique em Nós. O formulário Nós é aberto.
Escolha a Configuração da máquina padrão para usar nas instâncias. Você precisa selecionar um tipo de máquina com pelo menos duas CPUs e 4 GB de memória, como
n1-standard-2, para implantar o AI Platform Pipelines. O faturamento varia de acordo com cada tipo de máquina. Para informações sobre preços de tipos de máquina, consulte a tabela de preços.No painel de navegação, em Pools de nós, clique em Segurança. O formulário Segurança do nó é exibido.
Na lista suspensa Conta de serviço, selecione a conta de serviço que você criou anteriormente neste guia.
Caso contrário, configure o cluster do GKE conforme desejado. Saiba mais sobre como criar um cluster do GKE.
Clique em Criar
Instalar o Kubeflow Pipelines no cluster do GKE
Use as instruções a seguir para configurar o Kubeflow Pipelines em um cluster do GKE.
Abra o AI Platform Pipelines no console do Google Cloud.
Na barra de ferramentas dos AI Platform Pipelines, clique em Nova instância. Os pipelines do Kubeflow serão abertos no Google Cloud Marketplace.
Clique em Configurar. O formulário Implantar Kuberflow Pipelines (em inglês) será aberto.
Na lista suspensa Cluster, selecione o cluster que você criou em uma etapa anterior. Se o cluster que você quer usar não estiver qualificado para implantação, verifique se ele atende aos requisitos para implantar o Kubeflow Pipelines.
Os namespaces são usados para gerenciar recursos em clusters grandes do GKE. Se você não planeja utilizar namespaces no cluster, selecione padrão na lista suspensa Namespace.
Se você planeja usar namespaces no cluster do GKE, crie um namespace usando a lista suspensa Namespace. Para criar um namespace:
- Selecione Criar um namespace na lista suspensa Namespace. A caixa Novo nome do namespace é exibida.
- Digite o nome do namespace em Novo nome do namespace.
Para saber mais sobre namespaces, leia uma postagem do blog sobre como organizar o Kubernetes com namespaces (em inglês).
Na caixa Nome da instância do app, insira um nome para a instância do Kubeflow Pipelines.
O armazenamento gerenciado permite armazenar os metadados e artefatos do pipeline de ML por meio do Cloud SQL e do Cloud Storage, em vez de armazená-los em discos permanentes do Compute Engine. O uso de serviços gerenciados para armazenar os artefatos e metadados do pipeline facilita o backup e a restauração dos dados do cluster. Para implantar o Kubeflow Pipelines com armazenamento gerenciado, selecione Usar armazenamento gerenciado e forneça as seguintes informações:
Bucket do Cloud Storage para armazenamento de artefatos: com o armazenamento gerenciado, o Kubeflow Pipelines armazena artefatos de pipeline em um bucket do Cloud Storage. Especifique o nome do bucket em que você quer que o Kubeflow Pipelines armazene artefatos. Se o bucket especificado não existir, o implantador do Kubeflow Pipelines criará automaticamente um bucket para você na região
us-central1.Nome da conexão da instância do Cloud SQL: com o armazenamento gerenciado, o Kubeflow Pipelines armazena metadados do pipeline em um banco de dados MySQL no Cloud SQL. Especifique o nome da conexão para sua instância do MySQL do Cloud SQL.
Nome de usuário do banco de dados: especifique o nome de usuário do banco de dados que será usado pelo Kubeflow Pipelines ao se conectar à instância do MySQL. No momento, o usuário do banco de dados precisa ter privilégios
ALLdo MySQL para implantar o Kubeflow Pipelines com armazenamento gerenciado. Se você deixar esse campo em branco, o valor padrão será raiz.Senha do banco de dados: especifique a senha do banco de dados que será usada pelo Kubeflow Pipelines ao se conectar à instância do MySQL. Se você deixar esse campo em branco, o Kubeflow Pipelines se conectará ao banco de dados sem fornecer uma senha, o que causa falhas quando o nome de usuário especificado exige senha.
Prefixo do nome do banco de dados: especifique o prefixo do nome do banco de dados. O valor do prefixo precisa começar com uma letra e conter apenas letras minúsculas, números e sublinhados.
Durante o processo de implantação, o Kubeflow Pipelines cria dois bancos de dados: "DATABASE_NAME_PREFIX_pipeline" e "DATABASE_NAME_PREFIX_metadata". Se houver bancos de dados com esses nomes na instância do MySQL, o Kubeflow Pipelines reutilizará os bancos de dados existentes. Se esse valor não for especificado, o Nome da instância do app será usado como prefixo do nome do banco de dados.
Clique em Implantar. Essa etapa pode levar alguns minutos.
Para acessar o painel de pipelines, abra o AI Platform Pipelines no console do Google Cloud.
Acesse o AI Platform Pipelines
Em seguida, clique em Abrir painel de pipelines para a instância do AI Platform Pipelines.
Implantar o AI Platform Pipelines em um cluster do GKE existente
Para usar o Google Cloud Marketplace na implantação do Kubeflow Pipelines em um cluster do GKE, os critérios a seguir precisam ser atendidos:
- Seu cluster precisa ter pelo menos três nós. Cada nó precisa ter pelo menos duas CPUs e quatro GB de memória disponíveis.
- O escopo de acesso do cluster precisa conceder acesso total a todas as APIs do Cloud ou o cluster precisa usar uma conta de serviço personalizada.
- O cluster ainda não pode ter o Kubeflow Pipelines instalado.
Saiba mais sobre como configurar o cluster do GKE para o AI Platform Pipelines.
Use as instruções a seguir para configurar o Kubeflow Pipelines em um cluster do GKE.
Abra o AI Platform Pipelines no console do Google Cloud.
Na barra de ferramentas dos AI Platform Pipelines, clique em Nova instância. Os pipelines do Kubeflow serão abertos no Google Cloud Marketplace.
Clique em Configurar. O formulário Implantar Kuberflow Pipelines (em inglês) será aberto.
Na lista suspensa Cluster, selecione o cluster. Se o cluster que você quer usar não estiver qualificado para implantação, verifique se ele atende aos requisitos para implantar o Kubeflow Pipelines.
Os namespaces são usados para gerenciar recursos em clusters grandes do GKE. Caso o cluster não use namespaces, selecione padrão na lista suspensa Namespace.
Se o cluster usar namespaces, selecione um namespace atual ou crie um com a lista suspensa Namespace. Para criar um namespace:
- Selecione Criar um namespace na lista suspensa Namespace. A caixa Novo nome do namespace é exibida.
- Digite o nome do namespace em Novo nome do namespace.
Para saber mais sobre namespaces, leia uma postagem do blog sobre como organizar o Kubernetes com namespaces (em inglês).
Na caixa Nome da instância do app, insira um nome para a instância do Kubeflow Pipelines.
O armazenamento gerenciado permite armazenar os metadados e artefatos do pipeline de ML por meio do Cloud SQL e do Cloud Storage, em vez de armazená-los em discos permanentes do Compute Engine. O uso de serviços gerenciados para armazenar os artefatos e metadados do pipeline facilita o backup e a restauração dos dados do cluster. Para implantar o Kubeflow Pipelines com armazenamento gerenciado, selecione Usar armazenamento gerenciado e forneça as seguintes informações:
Bucket do Cloud Storage para armazenamento de artefatos: com o armazenamento gerenciado, o Kubeflow Pipelines armazena artefatos de pipeline em um bucket do Cloud Storage. Especifique o nome do bucket em que você quer que o Kubeflow Pipelines armazene artefatos. Se o bucket especificado não existir, o implantador do Kubeflow Pipelines criará automaticamente um bucket para você na região
us-central1.Nome da conexão da instância do Cloud SQL: com o armazenamento gerenciado, o Kubeflow Pipelines armazena metadados do pipeline em um banco de dados MySQL no Cloud SQL. Especifique o nome da conexão para sua instância do MySQL do Cloud SQL.
Nome de usuário do banco de dados: especifique o nome de usuário do banco de dados que será usado pelo Kubeflow Pipelines ao se conectar à instância do MySQL. No momento, o usuário do banco de dados precisa ter privilégios
ALLdo MySQL para implantar o Kubeflow Pipelines com armazenamento gerenciado. Se você deixar esse campo em branco, o valor padrão será raiz.Senha do banco de dados: especifique a senha do banco de dados que será usada pelo Kubeflow Pipelines ao se conectar à instância do MySQL. Se você deixar esse campo em branco, o Kubeflow Pipelines se conectará ao banco de dados sem fornecer uma senha, o que causa falhas quando o nome de usuário especificado exige senha.
Prefixo do nome do banco de dados: especifique o prefixo do nome do banco de dados. O valor do prefixo precisa começar com uma letra e conter apenas letras minúsculas, números e sublinhados.
Durante o processo de implantação, o Kubeflow Pipelines cria dois bancos de dados: "DATABASE_NAME_PREFIX_pipeline" e "DATABASE_NAME_PREFIX_metadata". Se houver bancos de dados com esses nomes na instância do MySQL, o Kubeflow Pipelines reutilizará os bancos de dados existentes. Se esse valor não for especificado, o Nome da instância do app será usado como prefixo do nome do banco de dados.
Clique em Implantar. Essa etapa pode levar alguns minutos.
Para acessar o painel de pipelines, abra o AI Platform Pipelines no console do Google Cloud.
Acesse o AI Platform Pipelines
Em seguida, clique em Abrir painel de pipelines para a instância do AI Platform Pipelines.
A seguir
- Orquestre o processo de ML como um pipeline.
- Use a interface de usuário do Kubeflow Pipelines para executar um pipeline.
- Saiba mais sobre o AI Platform Pipelines e os pipelines com ML.