Cuando añadas un conector de BigQuery a tu aplicación Vertex AI Vision, todas las salidas del modelo de la aplicación conectada se insertarán en la tabla de destino.
Puedes crear tu propia tabla de BigQuery y especificarla al añadir un conector de BigQuery a la aplicación, o bien dejar que la plataforma de aplicaciones de Vertex AI Vision cree la tabla automáticamente.
Creación automática de tablas
Si dejas que la plataforma de aplicaciones de Vertex AI Vision cree la tabla automáticamente, puedes especificar esta opción al añadir el nodo del conector de BigQuery.
Se aplican las siguientes condiciones a los conjuntos de datos y las tablas si quieres usar la creación automática de tablas:
- Conjunto de datos: el nombre del conjunto de datos creado automáticamente es
visionai_dataset. - Tabla: el nombre de la tabla creada automáticamente es
visionai_dataset.APPLICATION_ID. Gestión de errores:
- Si ya existe una tabla con el mismo nombre en el mismo conjunto de datos, no se creará automáticamente.
Consola
Abre la pestaña Aplicaciones del panel de control de Vertex AI Vision.
Selecciona Ver aplicación junto al nombre de la aplicación en la lista.
En la página del creador de aplicaciones, selecciona BigQuery en la sección Conectores.
Deja vacío el campo Ruta de BigQuery.

Cambia cualquier otro ajuste.
REST Y LÍNEA DE COMANDOS
Para que la plataforma de aplicaciones infiera un esquema de tabla, usa el campo createDefaultTableIfNotExists de BigQueryConfig cuando crees o actualices una aplicación.
Crear y especificar una tabla manualmente
Si quiere gestionar manualmente la tabla de salida, esta debe tener el esquema requerido como subconjunto del esquema de la tabla.
Si la tabla tiene esquemas incompatibles, se rechaza la implementación.
Usar el esquema predeterminado
Si usa el esquema predeterminado para las tablas de salida del modelo, asegúrese de que la tabla solo contenga las siguientes columnas obligatorias. Puedes copiar directamente el siguiente texto de esquema al crear la tabla de BigQuery. Para obtener información más detallada sobre cómo crear una tabla de BigQuery, consulta el artículo Crear y usar tablas. Para obtener más información sobre la especificación del esquema al crear una tabla, consulta Especificar un esquema.
Usa el siguiente texto para describir el esquema al crear una tabla. Para obtener información sobre cómo usar el tipo de columna JSON ("type": "JSON"), consulta Trabajar con datos JSON en SQL estándar.
Se recomienda usar el tipo de columna JSON para las consultas de anotaciones. También puedes usar "type" : "STRING".
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
Google Cloud consola
En la Google Cloud consola, ve a la página BigQuery.
Selecciona el proyecto.
Selecciona más opciones .
Haz clic en Crear tabla.
En la sección "Esquema", habilita Editar como texto.

gcloud
En el siguiente ejemplo, primero se crea el archivo JSON de la solicitud y, a continuación, se usa el comando gcloud alpha bq tables create.
Primero, crea el archivo JSON de la solicitud:
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsonEnvía el comando
gcloud. Haz las siguientes sustituciones:TABLE_NAME: el ID de la tabla o el identificador completo de la tabla.
DATASET: ID del conjunto de datos de BigQuery.
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
Filas de BigQuery de ejemplo generadas por una aplicación de Vertex AI Vision:
| ingestion_time | página | instancia | nodo | anotación |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
Usar un esquema personalizado
Si el esquema predeterminado no se adapta a tu caso práctico, puedes usar funciones de Cloud Run para generar filas de BigQuery con un esquema definido por el usuario. Si usas un esquema personalizado, no hay ningún requisito previo para el esquema de la tabla de BigQuery.
Gráfico de aplicaciones con el nodo de BigQuery seleccionado
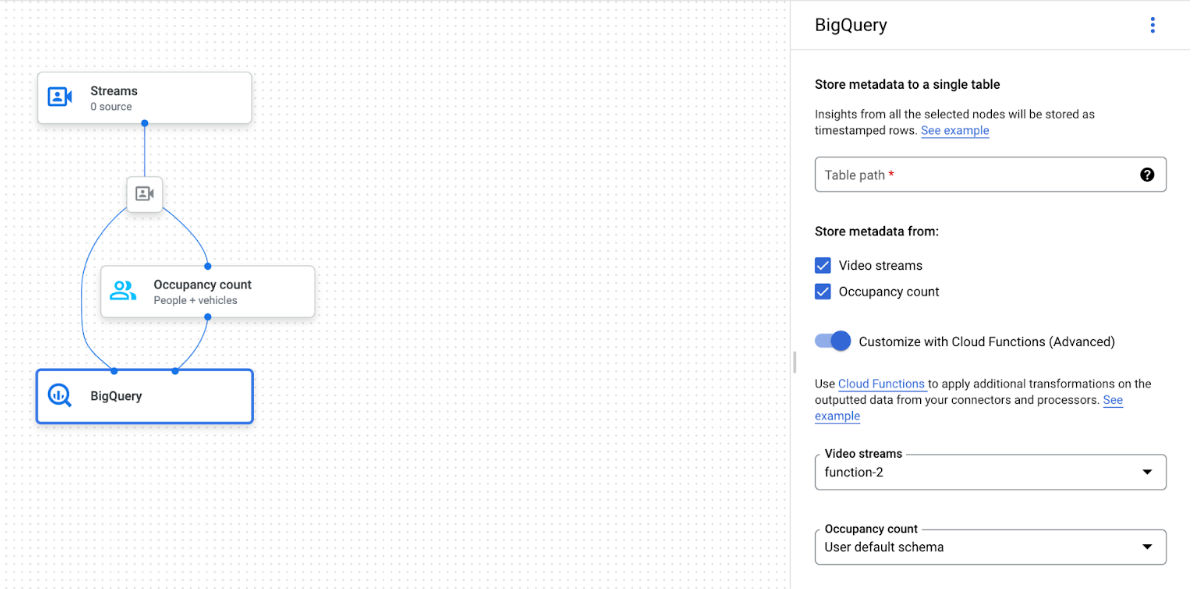
El conector de BigQuery se puede conectar a cualquier modelo que genere anotaciones basadas en vídeo o en proto:
- En el caso de las entradas de vídeo, el conector de BigQuery solo extrae los metadatos almacenados en el encabezado del flujo e ingiere estos datos en BigQuery como otras salidas de anotación de modelos. El vídeo en sí no se almacena.
- Si tu flujo no contiene metadatos, no se almacenará nada en BigQuery.
Consultar datos de tablas
Con el esquema de tabla de BigQuery predeterminado, puede realizar análisis avanzados una vez que la tabla se haya rellenado con datos.
Consultas de ejemplo
Puedes usar las siguientes consultas de ejemplo en BigQuery para obtener información valiosa de los modelos de Vertex AI Vision.
Por ejemplo, puedes usar BigQuery para dibujar una curva basada en el tiempo del número máximo de personas detectadas por minuto con los datos del modelo de detector de personas o vehículos con la siguiente consulta:
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
Del mismo modo, puedes usar BigQuery y la función de recuento de cruces de la analítica de ocupación para crear una consulta que cuente el número total de vehículos que cruzan la línea por minuto:
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
Ejecutar la consulta
Una vez que hayas formateado tu consulta de SQL estándar de Google, puedes usar la consola para ejecutarla:
Consola
En la Google Cloud consola, abre la página de BigQuery.
Selecciona Expand (Ampliar) junto al nombre del conjunto de datos y, a continuación, el nombre de la tabla.
En la vista de detalles de la tabla, haz clic en Redactar nueva consulta.

Introduce una consulta de SQL estándar de Google en el área de texto Editor de consultas. Para ver consultas de ejemplo, consulta Consultas de ejemplo.
Opcional: Para cambiar la ubicación del tratamiento de datos, haz clic en Más y, a continuación, en Configuración de la consulta. En Ubicación de tratamiento, haz clic en Selección automática y elige la ubicación de tus datos. Por último, haz clic en Guardar para actualizar la configuración de la consulta.
Haz clic en Ejecutar.
De esta forma, se crea una tarea de consulta que escribe el resultado en una tabla temporal.
Integración de Cloud Run Functions
Puedes usar funciones de Cloud Run para activar el procesamiento de datos adicional con tu ingestión de BigQuery personalizada. Para usar funciones de Cloud Run en tu ingestión personalizada de BigQuery, haz lo siguiente:
Cuando uses la Google Cloud consola, selecciona la función en la nube correspondiente en el menú desplegable de cada modelo conectado.
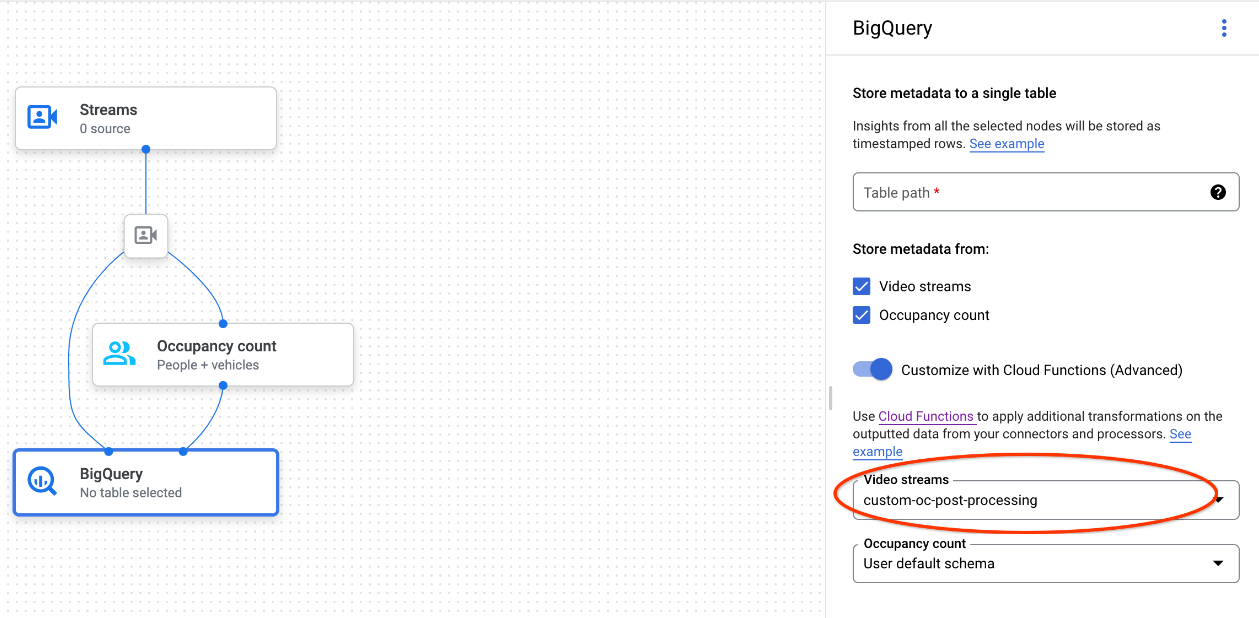
Cuando uses la API Vertex AI Vision, añade un par clave-valor al campo
cloud_function_mappingdeBigQueryConfigen el nodo BigQuery. La clave es el nombre del nodo de BigQuery y el valor es el activador HTTP de la función de destino.
Para usar funciones de Cloud Run con la ingestión de BigQuery personalizada, la función debe cumplir los siguientes requisitos:
- La instancia de funciones de Cloud Run debe crearse antes de crear el nodo de BigQuery.
- La API Vertex AI Vision espera recibir una anotación
AppendRowsRequestdevuelta por las funciones de Cloud Run. - Debes definir el campo
proto_rows.writer_schemaen todas las respuestasCloudFunction;write_streamse puede ignorar.
Ejemplo de integración de Cloud Run Functions
En el siguiente ejemplo se muestra cómo analizar la salida del nodo de recuento de ocupación (OccupancyCountPredictionResult) y extraer de ella un esquema de tabla ingestion_time, person_count y vehicle_count.
El resultado del siguiente ejemplo es una tabla de BigQuery con el siguiente esquema:
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
Usa el siguiente código para crear esta tabla:
Define un proto (por ejemplo,
test_table_schema.proto) para los campos de la tabla que quieras escribir:syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }Compila el archivo proto para generar el archivo de Python del búfer de protocolo:
protoc -I=./ --python_out=./ ./test_table_schema.protoImporta el archivo Python generado y escribe la función en la nube.
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
Para incluir tus dependencias en las funciones de Cloud Run, también debes subir el archivo
test_table_schema_pb2.pygenerado y especificarrequirements.txtde forma similar a la siguiente:functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2Despliega la función de Cloud y define el activador HTTP correspondiente en
BigQueryConfig.