Como criar uma política de alertas para um SLO
Nesta página, descrevemos como criar uma política de alertas no Cloud Monitoring para um objetivo de nível de serviço (SLO) criado no Cloud Service Mesh.
Veja uma introdução aos SLOs em Visão geral dos objetivos de nível de serviço.
O Cloud Monitoring pode acionar um alerta quando um serviço está prestes a violar um SLO. Crie uma política de alertas com base na taxa de consumo do erro de orçamento. Todos os alertas sobre erros de orçamento têm a mesma condição básica: uma porcentagem específica do erro de orçamento para o período de conformidade é consumida em um período de lookback, que é um intervalo de tempo, como os 60 minutos anteriores. Quando você cria a política de alertas, o Cloud Service Mesh define automaticamente a maioria das condições do alerta com base nas configurações do SLO. Você especifica o período de lookback e a porcentagem de consumo.
Para determinar os valores do período de lookback e a porcentagem de consumo, podem ser necessárias algumas tentativas e erros. Use o período de lookback padrão de 60 minutos como ponto de partida. Para determinar a porcentagem de consumo, monitore o comportamento do serviço para ver qual porcentagem do erro de orçamento total (durante o período de conformidade) foi consumida nos 60 minutos anteriores. Defina a porcentagem de consumo de modo a não ultrapassar o valor do erro de orçamento que você está disposto a pagar para o período de lookback, mas não quer gerar um alerta desnecessário.
Por exemplo, suponha que você tenha criado um SLO com o seguinte nome:
95% < 300ms Latency in Calendar Week
Com esse SLO, apenas 5% do número total de solicitações em uma semana pode ter uma
latência maior que 300 ms. O erro de orçamento total é consumido ao alcançar ou exceder 5%. Se
você definir o período de lookback como uma hora, cada período de lookback será 1/168 do
período de conformidade (há 168 horas em uma semana). Para calcular a porcentagem de consumo por hora
que não excede o orçamento total de erros da semana:
5% ÷ 168 ≈ 0.03%
Como a latência do serviço pode variar dependendo da carga ou de outras condições, definir 0,03% como a porcentagem de consumo pode acionar alertas desnecessários. Comece com o dobro desse valor, ou 0,06%, monitore o serviço e ajuste o valor conforme necessário.
Antes de começar
Crie um SLO para um dos serviços.
Como criar uma política de alertas em um SLO
Acesse a guia Integridade de um serviço:
No Google Cloud console, acesse Cloud Service Mesh.
Selecione o projeto Google Cloud na lista suspensa na barra de menus.
Clique no serviço para criar uma política de alertas.
Na barra de navegação à esquerda, clique em Integridade.
Clique no SLO para criar uma política de alertas.
Na seção Status atual do SLO à direita, clique no link Criar política de alertas.
A caixa de diálogo Adicionar condição é exibida. O Cloud Service Mesh preenche automaticamente a condição Taxa de uso do SLO com base nas configurações do SLO. Configure a condição Taxa de uso do SLO para receber um alerta quando o erro de orçamento do SLO estiver diminuindo muito rapidamente. Você quer ter certeza de que vai receber um alerta antes que o SLO esteja fora do erro de orçamento.
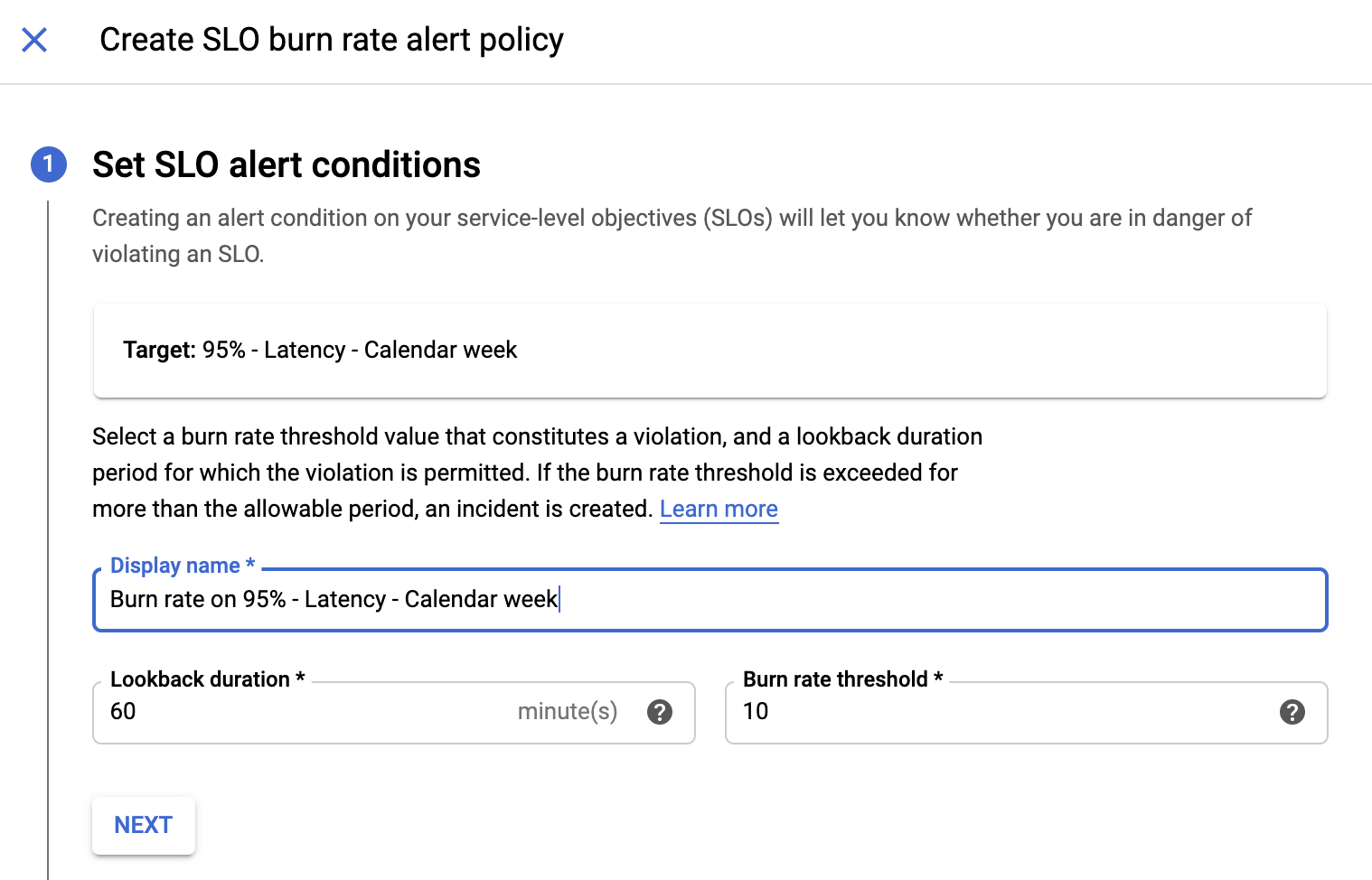
Configure a condição:
- Para nomear a condição, clique no link Título sugerido para usar o nome com base no SLO ou insira um nome para a condição.
- Na seção Meta, digite o período de lookback no campo Duração de lookback ou use o valor padrão.
- Na seção Configuração, insira a porcentagem de consumo no campo Limite.
- Clique em Salvar. A janela Criar nova política de alertas é exibida.
Configure a política de alertas:
- Digite um nome de política.
- A condição é preenchida automaticamente, mas é possível adicionar outra condição.
- Se a política de alertas tiver apenas uma condição, deixe o campo Gatilhos de política no valor padrão de Qualquer condição é atendida.
- Opcionalmente, configure as seções Notificações e Documentação. Saiba mais em Como gerenciar políticas de alerta.
- Clique em Salvar. A página Detalhes da política é exibida.
- Para voltar ao painel do Cloud Service Mesh, clique no Menu de navegação dehaze e acesse Anthos > Serviços.
A seguir
Saiba mais sobre alertas da engenharia de confiabilidade do site no Google: