Esta página descreve e compara dois serviços de proteção de dados confidenciais que ajudam a compreender os seus dados e a ativar fluxos de trabalho de administração de dados: o serviço de deteção e o serviço de inspeção.
Descoberta de dados confidenciais
O serviço de deteção monitoriza os dados em toda a sua organização. Este serviço é executado de forma contínua e descobre, classifica e cria perfis de dados automaticamente. A deteção pode ajudar a compreender a localização e a natureza dos dados que está a armazenar, incluindo recursos de dados dos quais pode não ter conhecimento. Normalmente, os dados desconhecidos (por vezes, denominados dados ocultos) não são sujeitos ao mesmo nível de administração de dados e gestão de riscos que os dados conhecidos.
Configura a deteção em vários âmbitos. Pode definir horários de criação de perfis diferentes para diferentes subconjuntos dos seus dados. Também pode excluir subconjuntos de dados que não precisa de analisar.
Resultado da análise de deteção: perfis de dados
O resultado de uma análise de deteção é um conjunto de perfis de dados para cada recurso de dados no âmbito. Por exemplo, uma análise de deteção de dados do BigQuery ou do Cloud SQL gera perfis de dados ao nível do projeto, da tabela e da coluna.
Um perfil de dados contém métricas e estatísticas sobre o recurso com perfil. Inclui as classificações de dados (ou infoTypes), os níveis de sensibilidade, os níveis de risco dos dados, o tamanho dos dados, o formato dos dados e outros elementos que descrevem a natureza dos dados e a respetiva postura de segurança dos dados (o nível de segurança dos dados). Pode usar perfis de dados para tomar decisões informadas sobre como proteger os seus dados, por exemplo, definindo políticas de acesso na tabela.
Considere uma coluna do BigQuery denominada ccn, em que cada linha contém um número de cartão de crédito exclusivo e não existem valores nulos. O perfil de dados ao nível da coluna gerado tem os seguintes detalhes:
| Nome a apresentar | Valor |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
Além disso, este perfil ao nível da coluna faz parte de um perfil ao nível da tabela, que fornece estatísticas como a localização dos dados, o estado da encriptação e se a tabela é partilhada publicamente. Na Google Cloud consola, também pode ver as entradas do Cloud Logging para a tabela e os principais do IAM com funções para a tabela.
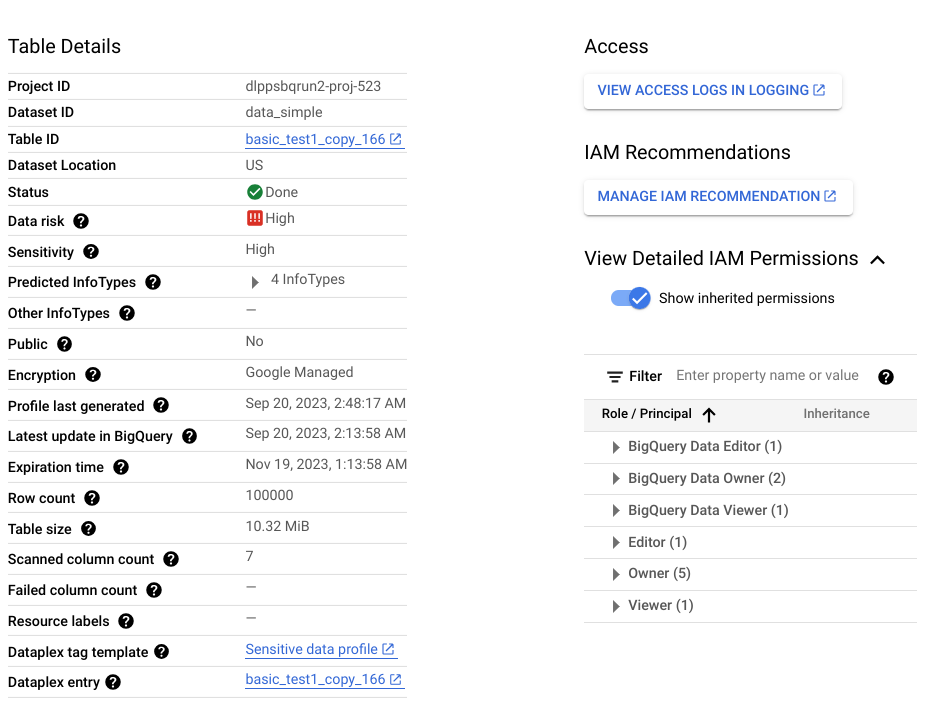
Para ver uma lista completa de métricas e estatísticas disponíveis nos perfis de dados, consulte a referência de métricas.
Quando usar a descoberta
Quando planear a sua abordagem de gestão de riscos de dados, recomendamos que comece pela deteção. O serviço de descoberta ajuda a ter uma vista geral dos seus dados e a ativar alertas, relatórios e a correção de problemas.
Além disso, o serviço de deteção pode ajudar a identificar os recursos onde os dados não estruturados podem residir. Esses recursos podem justificar uma inspeção exaustiva. Os dados não estruturados são especificados por uma pontuação de texto livre elevada numa escala de 0 a 1.
Inspeção de dados confidenciais
O serviço de inspeção realiza uma análise exaustiva de um único recurso para localizar cada instância individual de dados confidenciais. Uma inspeção produz uma descoberta para cada instância detetada.
As tarefas de inspeção oferecem um conjunto abrangente de opções de configuração para ajudar a identificar os dados que quer inspecionar. Por exemplo, pode ativar a amostragem para limitar os dados a inspecionar a um determinado número de linhas (para dados do BigQuery) ou a determinados tipos de ficheiros (para dados do Cloud Storage). Também pode segmentar um período específico em que os dados foram criados ou modificados.
Ao contrário da deteção, que monitoriza continuamente os seus dados, uma inspeção é uma operação a pedido. No entanto, pode agendar tarefas de inspeção recorrentes denominadas acionadores de tarefas.
Resultado da análise de inspeção: conclusões
Cada descoberta inclui detalhes como a localização da instância detetada, o respetivo infoType potencial e a certeza (também denominada probabilidade) de que a descoberta corresponde ao infoType. Consoante as suas definições, também pode obter a string real à qual a descoberta se refere. Esta string é denominada citação na proteção de dados confidenciais.
Para ver uma lista completa dos detalhes incluídos numa conclusão da inspeção, consulte o artigo
Finding.
Quando usar a inspeção
Uma inspeção é útil quando precisa de investigar dados não estruturados (como comentários ou críticas criados pelos utilizadores) e identificar cada instância de informações de identificação pessoal (IIP). Se uma análise de deteção identificar recursos que contenham dados não estruturados, recomendamos que execute uma análise de inspeção nesses recursos para obter detalhes sobre cada resultado individual.
Quando não usar a inspeção
A inspeção de um recurso não é útil se ambas as condições seguintes se aplicarem. Uma análise de deteção pode ajudar a decidir se é necessária uma análise de inspeção.
- Tem apenas dados estruturados no recurso. Ou seja, não existem colunas de dados de forma livre, como comentários ou críticas de utilizadores.
- Já conhece os infoTypes armazenados nesse recurso.
Por exemplo, suponha que os perfis de dados de uma análise de deteção indicam que uma determinada tabela do BigQuery não tem colunas com dados não estruturados, mas tem uma coluna de números de cartões de crédito únicos. Neste caso, a inspeção de números de cartões de crédito na tabela não é útil. Uma inspeção produz um
resultado para cada item na coluna. Se tiver 1 milhão de linhas e cada linha contiver 1 número de cartão de crédito, uma tarefa de inspeção produz 1 milhão de resultados para o infoType CREDIT_CARD_NUMBER. Neste exemplo, a inspeção não é necessária porque a análise de deteção já indica que a coluna contém números de cartões de crédito únicos.
Residência, tratamento e armazenamento de dados
Tanto a deteção como a inspeção suportam os requisitos de residência dos dados:
- O serviço de deteção processa os seus dados onde residem e armazena os perfis de dados gerados na mesma região ou multirregião que os dados com perfis. Para mais informações, consulte as considerações sobre a residência de dados.
- Quando inspeciona dados num Google Cloud sistema de armazenamento, o serviço de inspeção processa os seus dados na mesma região onde os dados residem e armazena a tarefa de inspeção nessa região. Quando inspeciona dados através de uma tarefa híbrida ou de um método
content, o serviço de inspeção permite-lhe especificar onde deve processar os seus dados. Para mais informações, consulte o artigo Como os dados são armazenados.
Resumo da comparação: serviços de descoberta e inspeção
| Descoberta | Inspeção | |
|---|---|---|
| Vantagens |
|
|
| Custo |
10 TB custam aproximadamente 300 USD por mês no modo de consumo. |
10 TB custam aproximadamente 10 000 USD por análise. |
| Origens de dados suportadas | BigLake BigQuery Variáveis de ambiente das funções do Cloud Run Variáveis de ambiente da revisão do serviço do Cloud Run Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore Híbrido (qualquer origem)1 |
| Âmbitos suportados |
|
Uma única tabela do BigQuery, um contentor do Cloud Storage ou um tipo do Datastore. |
| Modelos de inspeção integrados | Sim | Sim |
| Integrados e infoTypes personalizados | Sim | Sim |
| Resultado da análise | Vista geral de alto nível (perfis de dados) de todos os dados suportados. | Resultados concretos de dados confidenciais no recurso inspecionado. |
| Guarde os resultados no BigQuery | Sim | Sim |
| Enviar para o catálogo universal do Dataplex como etiquetas (descontinuado) | Yes | Yes |
| Envie para o catálogo universal do Dataplex como aspetos | Yes | Não |
| Publicar resultados no Security Command Center | Yes | Yes |
| Publique resultados no Google Security Operations | Sim para a descoberta ao nível da organização e da pasta | Não |
| Publicar no Pub/Sub | Yes | Sim |
| Suporte de residência dos dados | Yes | Yes |
1 A inspeção híbrida tem um modelo de preços diferente. Para mais informações, consulte o artigo Inspeção de dados de qualquer origem .
O que se segue?
- Explore estratégias recomendadas para mitigar o risco de dados (próximo documento desta série)