本頁說明可用於監控 Config Sync 資源的 OpenTelemetry 指標。
定價
Config Sync 指標會使用 Google Cloud Managed Service for Prometheus,將指標載入 Cloud Monitoring。Cloud Monitoring 會根據擷取的樣本數,收取擷取這些指標的費用。
詳情請參閱 Cloud Monitoring 定價。
Config Sync 收集指標的方式
Config Sync 會使用 OpenCensus 建立及記錄指標,並使用 OpenTelemetry 將指標匯出至 Prometheus 和 Cloud Monitoring。下列指南說明如何匯出指標:
- Cloud Monitoring
- Prometheus
- 自訂監控系統 (不建議)
根據預設,Config Sync 會建立名為 otel-collector 的 ConfigMap,用於設定 OpenTelemetry Collector。otel-collector 部署作業會在 config-management-monitoring 命名空間中執行。
建立 otel-collector ConfigMap 會設定 prometheus 匯出工具,該工具會公開指標端點供 Prometheus 掃描。
在 GKE 或其他已設定 Google Cloud 憑證的 Kubernetes 環境中執行 Config Sync 時,Config Sync 會建立名為 otel-collector-google-cloud 的 ConfigMap。otel-collector-google-cloud 會覆寫 otel-collector ConfigMap 中的設定。Config Sync 會還原對 otel-collector 或 otel-collector-google-cloud ConfigMap 所做的任何變更。
建立 otel-collector-google-cloud ConfigMap 時,也會新增 cloudmonitoring 匯出工具 (匯出至 Cloud Monitoring) 和 kubernetes 匯出工具 (匯出至 Google 內部指標服務)。kubernetes匯出工具會將選取的匿名指標傳送給 Google,協助改善 Config Sync。
Cloud Monitoring 會將您傳送的指標儲存在Google Cloud 專案中。cloudmonitoring和 kubernetes 匯出工具使用相同的Google Cloud 服務帳戶,該帳戶需要 IAM 權限才能寫入 Cloud Monitoring。如要設定這些權限,請參閱授予 Cloud Monitoring 指標寫入權限。
OpenTelemetry 指標
Config Sync 和 Resource Group Controller 會使用 OpenCensus 收集下列指標,並透過 OpenTelemetry Collector 提供這些指標。「標記」欄會列出適用於各項指標的 Config Sync 專屬標記。附有標籤的指標代表多項評估結果,每個標籤值組合各有一項。
Config Sync 指標
| 名稱 | 類型 | 標記 | 說明 |
|---|---|---|---|
| api_duration_seconds | 分布 | 作業、狀態 | API 伺服器呼叫的延遲時間分布。 |
| apply_duration_seconds | 分布 | 狀態 | 將從可靠資料來源宣告的資源套用至叢集的延遲分佈情形。 |
| apply_operations_total | 數量 | 作業、狀態、控制器 | 為將資源從真實來源同步至叢集而執行的作業總數。 |
| declared_resources | 最後的值 | 從 Git 剖析的已宣告資源數量。 | |
| internal_errors_total | 數量 | 來源 | Config Sync 遇到的內部錯誤總數。如果沒有發生內部錯誤,指標可能不會顯示在查詢結果中。 |
| last_sync_timestamp | 最後的值 | 狀態 | 最近一次從 Git 同步處理的時間戳記。 |
| parser_duration_seconds | 分布 | 狀態、觸發條件、來源 | 從真實來源同步至叢集所涉及不同階段的延遲時間分布。 |
| pipeline_error_observed | 最後的值 | 名稱、協調器、元件 | RootSync 和 RepoSync 自訂資源的狀態。值為 1 表示失敗。 |
| reconcile_duration_seconds | 分布 | 狀態 | 由協調器管理員處理的協調事件延遲分佈。 |
| reconciler_errors | 最後的值 | component、errorclass | 將資源從真實來源同步至叢集時發生的錯誤數。 |
| remediate_duration_seconds | 分布 | 狀態 | 補救措施協調事件的延遲時間分布情形。 |
| resource_conflicts_total | 數量 | 快取資源與叢集資源不符,導致的資源衝突總數。如果沒有發生資源衝突,指標可能不會顯示在查詢結果中。 | |
| resource_fights_total | 數量 | 同步頻率過高的資源總數。如果結果大於零,表示有問題。詳情請參閱「KNV2005:ResourceFightWarning」。如果沒有發生資源爭用,指標可能不會出現在查詢結果中。 |
資源群組控制器指標
Resource Group Controller 是 Config Sync 中的元件,可追蹤受管理資源,並檢查各項資源是否已準備就緒或完成協調。可用的指標如下:
| 名稱 | 類型 | 標記 | 說明 |
|---|---|---|---|
| rg_reconcile_duration_seconds | 分布 | stallreason | 調解 ResourceGroup CR 所需時間的分布情形 |
| resource_group_total | 最後的值 | 目前 ResourceGroup CR 的數量 | |
| resource_count | 最後的值 | resourcegroup | ResourceGroup 追蹤的資源總數 |
| ready_resource_count | 最後的值 | resourcegroup | ResourceGroup 中就緒的資源總數 |
| resource_ns_count | 最後的值 | resourcegroup | ResourceGroup 中資源使用的命名空間數量 |
| cluster_scoped_resource_count | 最後的值 | resourcegroup | ResourceGroup 中的叢集範圍內資源數量 |
| crd_count | 最後的值 | resourcegroup | ResourceGroup 中的 CRD 數量 |
| kcc_resource_count | 最後的值 | resourcegroup | ResourceGroup 中的 KCC 資源總數 |
| pipeline_error_observed | 最後的值 | 名稱、協調器、元件 | RootSync 和 RepoSync 自訂資源的狀態。值為 1 表示失敗。 |
Config Sync 指標標籤
指標標籤可用於匯總 Cloud Monitoring 和 Prometheus 中的指標資料。您可以在 Monitoring 主控台的「Group By」(依據分組) 下拉式清單中選取這些項目。
如要進一步瞭解 Cloud Monitoring 標籤和 Prometheus 指標標籤,請參閱「指標模型元件」和「Prometheus 資料模型」。
指標標籤
使用 Cloud Monitoring 和 Prometheus 監控時,您會看到 Config Sync 和 Resource Group Controller 指標,這些指標會使用下列標籤。
| 名稱 | 值 | 說明 |
|---|---|---|
operation |
create、patch、update、delete | 執行的作業類型 |
status |
成功、錯誤 | 作業的執行狀態 |
reconciler |
rootsync、reposync | Reconciler 的類型 |
source |
剖析器、差異器、修復工具 | 內部錯誤的來源 |
trigger |
重試、watchUpdate、managementConflict、resync、reimport | 對帳事件的觸發條件 |
name |
對帳人員姓名 | 對帳員姓名 |
component |
剖析、來源、同步、算繪、就緒 | 元件名稱 / 目前對帳階段 |
container |
協調器、git-sync | 容器名稱 |
resource |
CPU、記憶體 | 資源類型 |
controller |
套用者、修復者 | 根或命名空間調解器中的控制器名稱 |
type |
任何 Kubernetes 資源,例如 ClusterRole、Namespace、NetworkPolicy、Role 等。 | Kubernetes API 的種類 |
commit |
---- | 最近一次同步處理的修訂版本雜湊 |
資源標籤
傳送至 Prometheus 和 Cloud Monitoring 的 Config Sync 指標會設定下列指標標籤,以識別來源 Pod:
| 名稱 | 說明 |
|---|---|
k8s.node.name |
代管 Kubernetes Pod 的節點名稱 |
k8s.pod.namespace |
Pod 的命名空間 |
k8s.pod.uid |
Pod 的 UID |
k8s.pod.ip |
Pod 的 IP |
k8s.deployment.name |
擁有 Pod 的 Deployment 名稱 |
從 reconciler Pod 傳送至 Prometheus 和 Cloud Monitoring 的 Config Sync 指標,也會設定下列指標標籤,以識別用於設定協調器的 RootSync 或 RepoSync:
| 名稱 | 說明 |
|---|---|
configsync.sync.kind |
設定這個協調器的資源類型:RootSync 或 RepoSync |
configsync.sync.name |
設定這個協調器的 RootSync 或 RepoSync 名稱 |
configsync.sync.namespace |
設定這個調解器的 RootSync 或 RepoSync 命名空間 |
Cloud Monitoring 資源標籤
Cloud Monitoring 資源標籤用於為儲存空間中的指標建立索引,因此與指標標籤不同,對基數的影響微乎其微,而基數是效能方面的重要考量。詳情請參閱「受監控的資源類型」。
k8s_container 資源類型會設定下列資源標籤,以識別來源容器:
| 名稱 | 說明 |
|---|---|
container_name |
容器名稱 |
pod_name |
Pod 的名稱 |
namespace_name |
Pod 的命名空間 |
location |
代管節點的叢集所在區域或可用區 |
cluster_name |
代管節點的叢集名稱 |
project |
叢集所屬專案的 ID |
設定自訂指標篩選條件
您可以調整 Config Sync 匯出至 Prometheus、Cloud Monitoring 和 Google 內部監控服務的自訂指標。調整自訂指標,微調納入的指標或設定不同的後端。
如要修改自訂指標,請建立並編輯名為 otel-collector-custom 的 ConfigMap。使用這個 ConfigMap 可確保 Config Sync 不會還原您所做的任何修改。如果您修改 otel-collector 或 otel-collector-google-cloud ConfigMap,Config Sync 會還原所有變更。
如需調整這個 ConfigMap 的範例,請參閱開放原始碼 Config Sync 說明文件中的「自訂指標篩選」。
瞭解 pipeline_error_observed 指標
pipeline_error_observed 指標可協助您快速找出未同步或包含未與所需狀態調解資源的 RepoSync 或 RootSync CR。
如果 RootSync 或 RepoSync 成功完成同步,所有元件 (
rendering、source、sync、readiness) 的指標值都會是 0。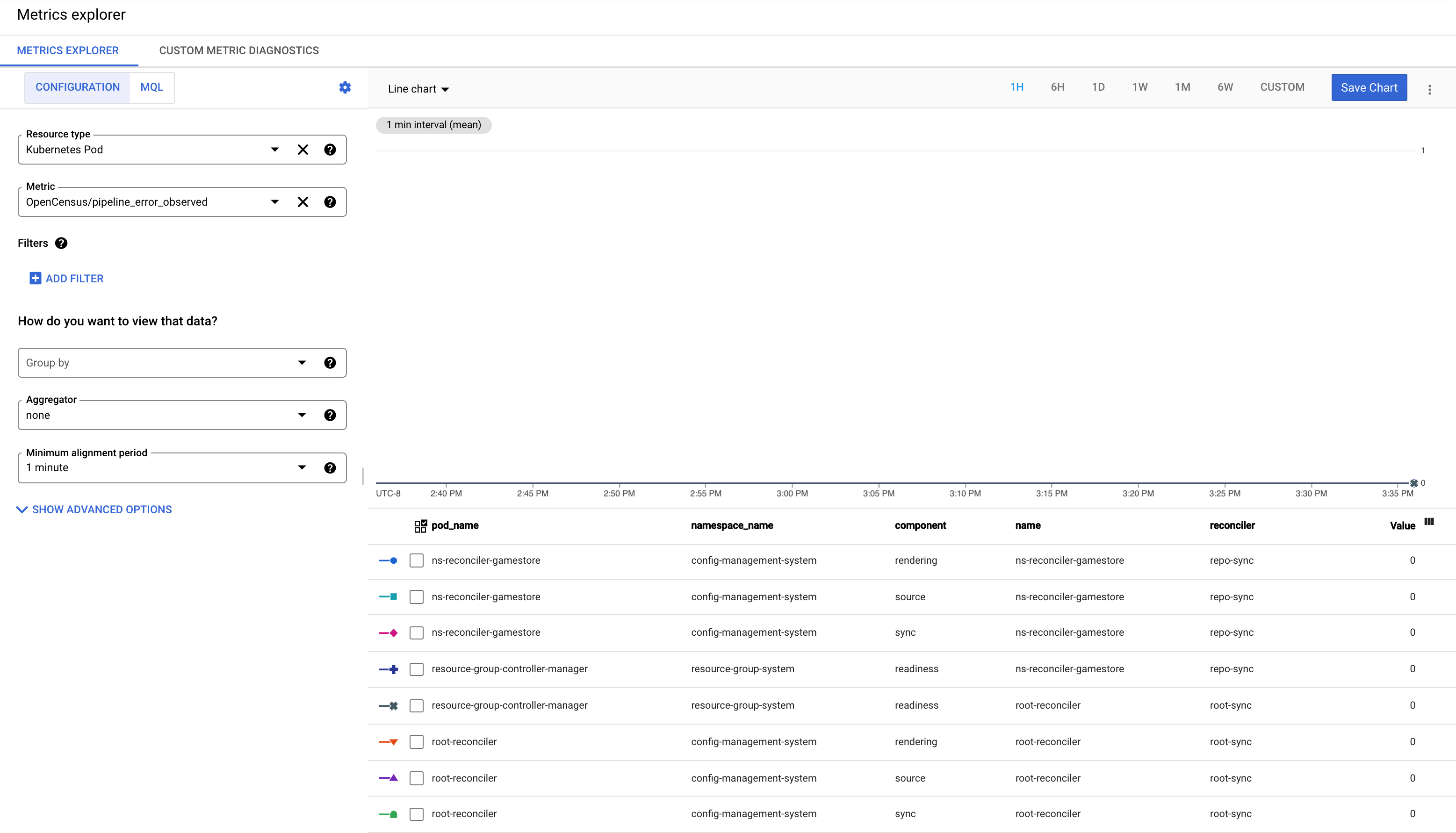
如果最新提交的內容無法通過自動算繪,系統會觀察到元件
rendering的指標值為 1。如果簽出最新提交內容時發生錯誤,或最新提交內容包含無效設定,則系統會觀察到元件
source的指標值為 1。如果資源無法套用至叢集,系統會觀察元件
sync的指標,值為 1。如果套用資源後無法達到所需狀態,系統會觀察元件
readiness的指標,並將值設為 1。舉例來說,Deployment 會套用至叢集,但對應的 Pod 未順利建立。
後續步驟
- 進一步瞭解如何監控 RootSync 和 RepoSync 物件。
- 瞭解如何使用 Config Sync SLI。