Tiempo estimado para completar la actividad: 4 días
Propietario del componente operable: HW
Perfil de habilidad: ingeniero de implementación
Completa las siguientes tareas para restablecer los dispositivos y sistemas que se ejecutan en el entorno aislado de Google Distributed Cloud (GDC).
6.1. Índice
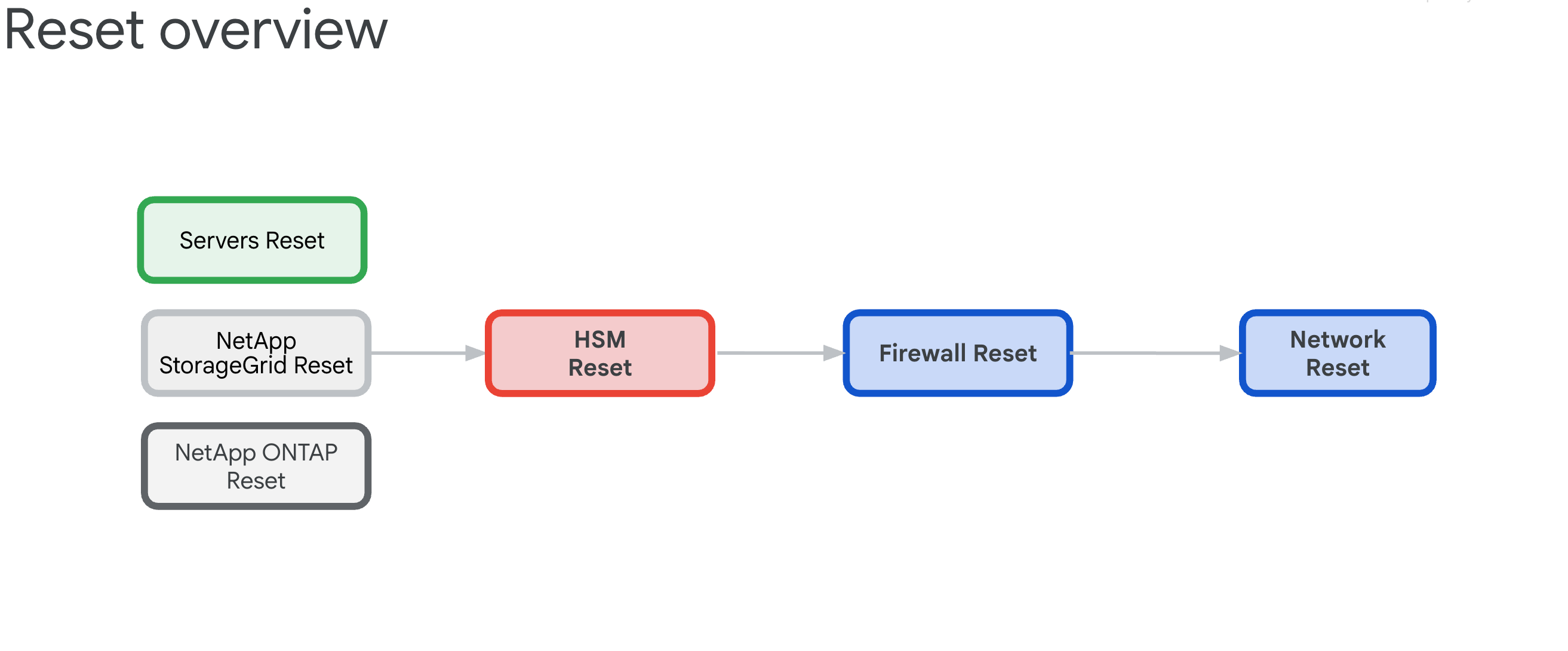
- Resumen del procedimiento de restablecimiento
- Restablecimiento del servidor de HPE
- Restablecimiento de NetApp StorageGRID
- Restablecimiento de NetApp ONTAP
- Restablecimiento del HSM de Thales
- Restablecimiento de firewalls de Palo Alto
- Restablecimiento de los conmutadores de Cisco
- Additional Resources
6.2. Requisitos previos y seguridad
6.2.1. Acceso obligatorio
- Acceso físico: Acceso a la sala de CC con equipo de carro de paro
- Acceso a la red: Conectividad de la interfaz de administración o acceso a la consola
- Credenciales: Acceso de administrador a todos los sistemas
- Copias de seguridad: Copia de seguridad completa de todos los secretos y los datos de configuración
6.2.2. Lista de tareas de seguridad
- [ ] Acceso físico a la infraestructura
- [ ] Se protegieron sin conexión los secretos de Break-glass
- [ ] Copia de seguridad de la infraestructura (si es necesario)
6.3. Descripción general del procedimiento de restablecimiento
El procedimiento de restablecimiento de una zona de celda de GDC existente tiene como objetivo liberar todos los dispositivos de HW de cualquier dependencia y, luego, revertirlos a su estado de fábrica.
6.3.1. Dependencias de infraestructura
Los componentes tienen las siguientes interdependencias que determinan el orden de restablecimiento:
- Los servidores, NetApp ONTAP y NetApp StorageGrid dependen de los dispositivos HSM de Thales, ya que estos proporcionan las claves de encriptación para ILO, discos, arrendatarios y buckets.
- Los dispositivos HSM de Thales dependen de la conectividad de los firewalls de IDP/perímetro y los conmutadores de Cisco.
- Los firewalls perimetrales o IDP dependen de la infraestructura de redes de los conmutadores de Cisco.
- Los conmutadores Cisco deben restablecerse como último recurso, ya que la conectividad se interrumpirá después de restablecerlos.
6.3.2. Restablecer pedido (crítico)
Sigue este orden exacto para evitar bloqueos del sistema:
- Servidores HPE: Primero quita las dependencias del HSM
- NetApp StorageGRID: Borra la encriptación y restablece los nodos
- NetApp ONTAP: Inhabilita el HSM y restablece el clúster
- HSM de Thales: Restablece la configuración de fábrica y borra la raíz de confianza
- Firewalls: Restablece la configuración de fábrica predeterminada
- Switches de Cisco: Restablece al último (interrumpirá la conectividad)
6.4. Borrado seguro de Hewlett Packard Enterprise
Existen tres tipos de operaciones de restablecimiento disponibles, cada una de las cuales sirve como un método alternativo para limpiar la configuración de iLO Key Manager. El objetivo principal es quitar la dependencia del módulo de seguridad de hardware (HSM).
Por lo general, el restablecimiento de fábrica de ILO es suficiente para limpiar la configuración de KMS. Luego, en el próximo inicio, el proceso de inicio del servidor inicializará los parámetros de la BIOS de configuración del servidor, borrará los discos y reinicializará el servidor.
En esta sección, se explica cómo realizar tres tipos de borrado:
Estos secuencias de comandos de borrado usan un archivo CSV de ejemplo llamado example.csv.
Antes de continuar, prepara el siguiente archivo CSV:
root@example-bootstrapper:/home/ubuntu/md# cat example.csv
ip,passd
10.251.248.62,XXXXXXXX
10.251.248.64,XXXXXXXX
10.251.248.66,XXXXXXXX
10.251.248.68,XXXXXXXX
10.251.248.70,XXXXXXXX
10.251.248.72,XXXXXXXX
10.251.248.74,XXXXXXXX
10.251.248.76,XXXXXXXX
6.4.1. Restablecimiento de la configuración de fábrica de iLO
Completa un restablecimiento de la configuración de fábrica de iLO normal:
Crea un archivo llamado
serversreset.pyy agrega la siguiente secuencia de comandos de Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='serversreset.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'Default'} url = '/redfish/v1/Managers/1/Actions/Oem/Hpe/HpeiLO.ResetToFactoryDefaults/' with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+url,data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Ejecuta el siguiente comando y reemplaza
example.csvpor tu archivo CSV:python3 serversreset.py -csv example.csvEl resultado debe ser similar al siguiente:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}}
6.4.2. Pasos manuales adicionales de iLO
Realiza un restablecimiento manual de iLO con la IU de iLO:
Selecciona iLO > Administración > Administrador de claves > Borrar configuración.
En la consola del BIOS, selecciona System Utilities > System Configuration > Embedded Raid > Administration > Reset To Default.
Establece las interfaces para que solo se realicen netboots para LOM1. Todos los nodos de GPU NO tienen tarjetas LOM1, sino que tienen tarjetas Intel.
Establece la red de iLO en DHCP.
6.4.3. Restablecimiento del BIOS
Sigue estos pasos para restablecer el BIOS:
Crea un archivo llamado
biosreset.pyy agrega la siguiente secuencia de comandos de Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='biosreset.py', \ description='reset BIOS to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/systems/1/bios/Actions/Bios.ResetBios/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Ejecuta el siguiente comando y reemplaza
example.csvpor tu archivo CSV:python3 biosreset.py -csv example.csvEl resultado debe ser similar al siguiente:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.SystemResetRequired'}]}}Después de ejecutar el comando, los servidores estarán encendidos. Debes ejecutar la siguiente secuencia de comandos para apagar todos los servidores:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='power-ilo.py', \ description='power off server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'PushPowerButton'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post( 'https://' + row['ip'] + '/redfish/v1/systems/1/Actions/ComputerSystem.Reset/', data=json.dumps(payload), headers=headers, verify=False, auth=('administrator', row['passd'])) systemData = system.json() if 'Success' in systemData['error']['@Message.ExtendedInfo'][0][ 'MessageId']: print(f"ilo with ip {row['ip']} succeeded") #print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: print(err)Apaga los servidores de forma manual:
python3 power-ilo.py -csv ~/servers.csv- (Opcional) Para verificar el estado, usa la siguiente secuencia de comandos:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='ilostatus.py', \ description='check power status of server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.get('https://'+row['ip']+'/redfish/v1/Systems/1',headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(f"ilo with ip {row['ip']} has power status of {systemData['PowerState']}") if 'Success' in systemData['error']['@Message.ExtendedInfo'][0]['MessageId']: print(f"ilo with ip {row['ip']} succeeded") print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: passEjecuta el siguiente comando:
python3 ilostatus.py -csv ~/servers.csvEl resultado debe ser similar al siguiente:
ilo with ip 172.22.112.96 has power status of Off ilo with ip 172.22.112.97 has power status of Off ilo with ip 172.22.112.98 has power status of Off ilo with ip 172.22.112.100 has power status of Off ilo with ip 172.22.112.101 has power status of Off ilo with ip 172.22.112.102 has power status of Off6.4.4. Borrado seguro
Presiona F10 en la pantalla POST del servidor. Se iniciará Intelligent Provisioning.
Después de que se inicie Intelligent Provisioning, haz clic en la flecha hacia abajo que sigue a First Time Setup Wizard para omitir el asistente.
En Skip Wizard Prompt, haz clic en Yes.
Haz clic en Perform Maintenance.
Haz clic en One Button Secure Erase.
Aparece un mensaje que indica que no tienes privilegios suficientes. Haz clic en Acceder y, luego, ingresa las credenciales de administrador.
Haz clic en Listo.
Haz clic en Enviar.
Confirma que quieres realizar el borrado seguro y, luego, escribe ERASE.
Haz clic en BORRAR.
Haz clic en Sí para confirmar la decisión.
Haz clic en Launch Now en la sección Jobs queue.
En aproximadamente 2 minutos o menos, sigue la instrucción para hacer clic en Aceptar.
La máquina se reiniciará. No toques nada durante unos 10 a 15 minutos.
Una vez que se complete el borrado seguro, vuelve al BIOS haciendo clic durante el POST de inicio F9.
Navega a Embedded Applications > Integrated Management Log (IML) > View IML > OK. Se muestra el mensaje Borrado seguro con un botón completado:

Crea un archivo llamado
serversreset.pyy agrega la siguiente secuencia de comandos de Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='secureerase.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'SystemROMAndiLOErase': True , 'UserDataErase': True} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/Systems/1/Actions/Oem/Hpe/HpeComputerSystemExt.SecureSystemErase/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Ejecuta el siguiente comando y reemplaza
example.csvpor tu archivo CSV:python serversreset.py -csv example.csvDespués de ejecutar el comando, los servidores estarán apagados. Debes encender el servidor de forma manual.
6.5. Cómo restablecer el dispositivo NetApp StorageGRID
6.5.1. Requisitos previos
Antes de restablecer tu dispositivo NetApp StorageGRID, asegúrate de leer lo siguiente: - Si el sistema se habilitó con encriptación de nodos o de unidades, debes seguir los pasos que se describen en Cómo inhabilitar la encriptación del sitio del HSM. De lo contrario, continúa con el restablecimiento del sistema StorageGRID.
6.5.2. Inhabilita la encriptación del sitio del HSM de StorageGRID en los nodos del controlador de almacenamiento
Para obtener las IPs de los nodos del controlador de almacenamiento (dos IPs para cada nodo de almacenamiento), haz lo siguiente:
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Si el sistema StorageGRID se habilitó anteriormente con un HSM, se debe quitar el cifrado antes de restablecer la configuración de fábrica. Realiza estos pasos para cada nodo de almacenamiento antes de restablecer el dispositivo. De lo contrario, es posible que se bloqueen los discos y el sistema.
Accede al sitio de Object Storage y navega a la lista de nodos que se encuentra en la barra lateral.
Haz clic en el nombre del nodo de almacenamiento.
Navega a la pestaña SANtricity System Manager.
Navega a Configuración > Sistema > Administración de llaves de seguridad.

Selecciona Inhabilitar la administración de claves externas y escribe la frase de contraseña para descargar la clave de copia de seguridad.
6.5.3. Restablecimiento de la configuración de fábrica del nodo de administración de StorageGRID y del nodo de procesamiento de almacenamiento
Para obtener las IPs de los nodos de administrador, haz lo siguiente:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
Para obtener las IPs de los nodos de procesamiento de Storage, haz lo siguiente:
$ kubectl get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Para restablecer la configuración de fábrica del dispositivo StorageGRID, debes completar los siguientes pasos para cada nodo (nodos de almacenamiento y de administrador) del sitio:
Recupera las IPs de administración de cada nodo. Esto se puede obtener de cell.yaml, buscando
ObjectStorageStorageNodeyObjectStorageAdminNode. También se pueden encontrar en los recursos del nodo del clúster de administrador raíz.Recupera la contraseña y conéctate al nodo con SSH:
Si el nodo no tiene instalado StorageGRID, usa
admin/bycastoroot/netapp1!como nombre de usuario y contraseña, respectivamente. Usa el puerto SSH 8022 si ssh no funciona.Si el nodo tiene instalado StorageGRID, pero no se configuró el sitio, usa
admin/bycastoroot/bycastcomo nombre de usuario y contraseña, respectivamente.Si el sitio está configurado y el nodo forma parte de él, haz lo siguiente:
Recupera la frase de contraseña de aprovisionamiento. Este se almacena en un secreto llamado
grid-secret, que se puede encontrar en el archivo cell.yaml. De manera opcional, se puede ejecutar el siguiente comando. Asegúrate de decodificar la contraseña en Base64:echo $(kubectl get secret -n gpc-system grid-secret -ojsonpath="{.data.grid-management-provisioning-password}" | base64 -d)En la IU del sitio de Object Storage, navega a Mantenimiento > Sistema > Paquete de recuperación para descargar el paquete de recuperación después de ingresar la frase de contraseña de aprovisionamiento.

Después de la descarga, extrae el archivo tar. Este contendrá otro archivo tarball:
GIDXXXXX_REV1_SAID.zip. Extrae ese archivo tar.gz para encontrar el archivoPasswords.txt. UsaPasswordpara el acceso raíz y por SSH, y omiteSSH Access Password.Archivo de muestra:
Password Data for Grid ID: 546285, Revision: 1 Revision Prepared on: 2022-06-13 20:49:56 +0000 Server "root" and "admin" Account Passwords Server Name Password SSH Access Password ____________________________________________________________ alatl14-gpcstgeadm01 <removed> <removed> alatl14-gpcstgeadm02 <removed> <removed> alatl14-gpcstgecn01 <removed> n/a alatl14-gpcstgecn02 <removed> n/a alatl14-gpcstgecn03 <removed> n/a
Abre una consola en serie para el nodo o conéctate a él con SSH:
ssh -o ProxyCommand=None -o StrictHostKeyChecking=no \ -o UserKnownHostsFile=/dev/null admin@<node-management-ip>Ingresa las credenciales para acceder. Para obtener privilegios de sudo, escribe
su -y, luego, ingresa la contraseña de administrador que obtuviste en el segundo paso.Ingresa el comando
sgareinstally presionaypara continuar con el restablecimiento del dispositivo.Si la encriptación estaba habilitada en el dispositivo, después de que se complete el restablecimiento, sigue estos pasos para borrar los grupos de discos y la caché de SSD.
6.5.4. Borra los grupos de discos y la caché de SSD en los nodos del controlador de almacenamiento
Para obtener las IPs de los nodos del controlador de almacenamiento (dos IPs para cada nodo de almacenamiento), haz lo siguiente:
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Si se habilitó la encriptación en el dispositivo y se restablecieron los nodos después de seguir la última sección, los grupos de discos deben borrarse junto con el borrado de las unidades. Esto debe hacerse antes de reiniciar el sitio para que pueda crear nuevos grupos de discos. Sigue estos pasos para cada nodo de almacenamiento (controlador de almacenamiento e2860) del sitio (también conocido como controllerAManagementIP):
Abre un navegador web para visitar
https://<storage-node-controller-ip>:8443y, luego, ingresa las credenciales. Si no tienes acceso a las credenciales de SANtricity, sigue estos pasos.Navega a Almacenamiento > Grupos de volúmenes y grupos.
Borra la caché de SSD:
Selecciona el caché de SSD para destacarlo.
Selecciona el menú desplegable Uncommon Tasks y haz clic en Borrar.

Borra el grupo de discos:
Selecciona el grupo de discos para destacarlo.
Selecciona el menú desplegable Uncommon Tasks y haz clic en Borrar.

Intenta crear un nuevo grupo de discos. Aparece un diálogo que bloquea la creación y solicita que se borren las unidades.

Como las unidades habilitadas para seguridad no asignadas no se pueden usar para crear grupos, primero debes borrarlas. Haz clic en el botón de opción Sí, quiero seleccionar las unidades que deseo borrar para la operación y, luego, selecciona todas las unidades que deseas borrar. Confirma la operación de borrado y haz clic en Aceptar. No continúes con la creación de un grupo nuevo.
Sigue los pasos que se describen en la sección sobre cómo quitar la encriptación de nodos.
6.5.5. Quita el cifrado de nodos en los nodos de administrador y los nodos de procesamiento de almacenamiento de StorageGRID
Para obtener las IPs de los nodos de administrador, haz lo siguiente:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
Para obtener las IPs de los nodos de procesamiento de Storage, haz lo siguiente:
$ kr get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Si la encriptación estaba habilitada en el dispositivo y los nodos se restablecieron después de seguir estos pasos, y los grupos de discos y la caché de SSD se borraron con estos pasos, realiza los siguientes pasos en cada nodo para quitar la encriptación del nodo:
Navega a la IU del instalador de dispositivos de StorageGRID.
Ve a Configure Hardware > Node Encryption.
Haz clic en Borrar clave de KMS y borrar datos.

Una vez que se active el borrado, se reiniciará el control, lo que puede tardar alrededor de 15 minutos.
6.5.6. Reinstala StorageGRID
Reinicia cada nodo de forma manual.
Abre una consola serial en el nodo, captura el menú del cargador de arranque GRUB y selecciona StorageGRID Appliance: Force StorageGRID reinstall.

6.5.7. Obtén credenciales de SANtricity
Abre una consola serial en cualquiera de los controladores de SANtricity.
Usa las siguientes credenciales para acceder:
- Nombre de usuario:
spri - contraseña:
SPRIentry
- Nombre de usuario:
Una vez que accedas, verás un menú como este:
Service Interface Main Menu ============================== 1)Display IP Configuration 2)Change IP Configuration 3)Reset Storage Array Administrator Password 4)Display 7-segment LED codes 5)Disable SAML 6)Unlock remote admin account Q)Quit Menu Enter Selection: 3 Are you sure that you want to reset the Storage Array Password ? (Y/N): Y Storage Array Password reset successfulAccede a los controladores de SANtricity y estará disponible el restablecimiento de la contraseña.
6.6. Cómo restablecer el dispositivo NetApp ONTAP
6.6.1. Requisitos previos
Antes de restablecer tu dispositivo NetApp ONTAP, asegúrate de leer lo siguiente:
Si el sistema se habilitó previamente con un módulo de seguridad de hardware (HSM), debes seguir los pasos que se describen en Cómo inhabilitar el módulo de seguridad de hardware antes de restablecer los sistemas ONTAP.
Esta es una operación destructiva que borra todos los datos de CipherTrust Manager, incluidas, sin limitaciones, las claves, las copias de seguridad, las claves de copias de seguridad y los registros del sistema.
Asegúrate de tener una copia de seguridad válida de CipherTrust Manager de todos los datos y las claves de copia de seguridad.
Si hay un HSM integrado disponible, no se restablece como parte de esta operación.
Opcional: Se recomienda volver a inicializar un HSM integrado después de esta operación para configurarlo como la raíz de confianza.
Si se usó un dispositivo de entrada de PIN (PED) remoto, se debe volver a conectar después de completar la operación.
Esta operación puede demorar hasta 15 minutos. Asegúrate de tener una batería de respaldo.
6.6.2. Inhabilita el módulo de seguridad de hardware
Si el sistema se habilitó anteriormente con un HSM, realiza estos pasos antes de restablecer los sistemas ONTAP. De lo contrario, es posible que se bloqueen los discos y el sistema. Ejecuta los siguientes comandos en el clúster de ONTAP:
Establece el nivel de privilegio en avanzado:
set -privilege advancedEnumera la clave de datos del disco y las claves de autenticación de los Estándares Federales de Procesamiento de la Información (FIPS) que utiliza:
storage encryption disk showPara cada disco del sistema, establece el ID de la clave de autenticación de datos y FIPS del nodo en el MSID predeterminado 0x0:
storage encryption disk modify -disk * -fips-key-id 0x0 storage encryption disk modify -disk * -data-key-id 0x0Confirma que la operación se realizó correctamente con lo siguiente:
storage encryption disk show-statusRepite el comando
show-statushasta que recibasDisks Begun == Disks Done. Este resultado significa que la operación se completó.cluster1:: storage encryption disk show-status FIPS Latest Start Execution Disks Disks Disks Node Support Request Timestamp Time (sec) Begun Done Successful ------- ------- -------- ------------------ ---------- ------ ------ ---------- cluster1 true modify 1/18/2022 15:29:38 3 14 5 5 1 entry was displayed.Quita la configuración del administrador de claves externo:
Si la conexión HSM está activa, ve directamente al paso f. Si la conexión del HSM no funciona, ve al paso b.
cluster1::> security key-manager external show-statusEjecuta
set -priv diagpara ir al mododiag.Ejecuta el siguiente comando para mostrar todas las claves de encriptación del volumen.
debug smdb table kmip_external_key_cache_mdb_v2 showRecopila la propiedad
vserver-id.Ejecuta el siguiente comando para todos los servidores de claves para borrar las claves:
debug smdb table kmip_external_key_cache_mdb_v2 delete -vserver-id <vserver-id> -key-id * -key-server <key-server endpoint>.Borra todos los volúmenes con la interfaz de usuario (IU) de ONTAP o bórralos manualmente desde la consola.
Si borras desde la consola, debes ignorar los volúmenes raíz de los nodos. Por lo general, tienen el nombre
vol0y uno de los nodos comovserver. Por lo general, no se permite borrar ningún volumen que tenga un nodo comovserver, y no se debe borrar.Si no se pueden borrar otros volúmenes que no sean
vol0, del paso anterior, desde la IU, intenta usar la CLI:cluster1::> vol offline -volume volume_to_be_deleted -vserver vserve-id cluster1::> vol delete -volume volume_to_be_deleted -vserver vserver-idPara acceder a un clúster de almacenamiento desde la IU, obtén el nombre de usuario y la contraseña del secreto con los siguientes comandos, reemplazando CELL_ID por el ID único de la celda que estás instalando:
kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_username}' | base64 --decode kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_password}' | base64 --decodeLuego, ve a Volúmenes, selecciona todos y haz clic en Borrar. Debes repetir este paso varias veces para cada página. Nota: Puedes ignorar sin problema un error que indique que no se pudo borrar un volumen. Consulta la base de conocimiento de NetApp para obtener más detalles.
ag-stge-clus-01::*> vol show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- ag-ad-stge01-01 vol0 aggr0_ag_ad_stge01_01 online RW 151.3GB 84.97GB 40% ag-ad-stge01-02 vol0 aggr0_ag_ad_stge01_02 online RW 151.3GB 86.69GB 39% ag-ad-stge02-01 vol0 aggr0_ag_ad_stge02_01 online RW 151.3GB 83.62GB 41% ag-ad-stge02-02 vol0 aggr0_ag_ad_stge02_02 online RW 151.3GB 85.97GB 40% ag-ad-stge03-01 vol0 aggr0_ag_ad_stge03_01 online RW 151.3GB 89.19GB 37% ag-ad-stge03-02 vol0 aggr0_ag_ad_stge03_02 online RW 151.3GB 88.74GB 38%
Después de borrar todos los volúmenes, ejecuta el siguiente comando para purgar la cola de recuperación:
recovery-queue purge-all -vserver <vserver>.Ejecuta el siguiente comando para borrar el administrador de claves externo:
clusterl::> security key-manager external remove-servers -vserver <CLUSTER_NAME> -key-servers <IP1:PORT,IP2:PORT,...>. Después de este paso, es posible que recibas el siguiente error:Error: command failed: The key server at "172.22.112.192" contains authentication keys that are currently in use and not available from any other configured key server.Este error indica que hay claves restantes. Para borrar las llaves restantes, sigue estos pasos:
Para mostrar las claves restantes, ejecuta el siguiente comando:
security key-manager key queryEl resultado es similar al siguiente ejemplo.
Node: ag-ad-stge01-01 Vserver: ag-stge-clus-01 Key Manager: 172.22.112.192:5696 Key Manager Type: KMIP Key Manager Policy: - Key Tag Key Type Encryption Restored ------------------------------------ -------- ------------ -------- ag-ad-stge01-01 NSE-AK AES-256 true Key ID: 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Toma nota del valor del ID de clave del resultado anterior. Usa el comando
security key-manager key delete -key-idy el valor de ID de clave para borrar las claves restantes:security key-manager key delete -key-id 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Repite los pasos i y j para borrar las claves restantes. Cuando termines, el resultado será similar al siguiente ejemplo:
ag-stge-clus-01::*> security key-manager key query No matching keys found.6.6.3. Cómo restablecer nodos de ONTAP
Para restablecer los nodos de ONTAP, haz lo siguiente:
Reinicia el nodo para acceder al menú de inicio con el comando
system node rebooten el símbolo del sistema. Nota: Puedes ignorar sin riesgo las advertencias de reinicio del sistema.Ejemplos:
ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge03-02". Use the "network interface show -curr-node ag-ad-stge03-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Connection to 172.22.115.134 closed.ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 Error: command failed: Taking node "ag-ad-stge02-02" out of service might result in a data service failure and client disruption for the entire cluster. If possible, bring an additional node online to improve the resiliency of the cluster and to ensure continuity of service. Verify the health of the node using the "cluster show" command, then try the command again, or provide "-ignore-quorum-warnings" to bypass this check. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge02-02". Use the "network interface show -curr-node ag-ad-stge02-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Connection to 172.22.115.132 closed.Si estás en el menú
LOADER, ingresaboot_ontappara continuar con el reinicio. Durante el proceso de reinicio, presionaCtrl-Cpara mostrar el menú de arranque cuando se te solicite. El nodo muestra las siguientes opciones para el menú de arranque:(1) Normal Boot. (2) Boot without /etc/rc. (3) Change password. (4) Clean configuration and initialize all disks. (5) Maintenance mode boot. (6) Update flash from backup config. (7) Install new software first. (8) Reboot node. (9) Configure Advanced Drive Partitioning Selection (1-9)?Selecciona la opción
(9) Configure Advanced Drive Partitioning. El nodo muestra las siguientes opciones:* Advanced Drive Partitioning Boot Menu Options * ************************************************* (9a) Destroy aggregates, unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. (9f) Remove disk ownership.Selecciona la opción
9ay, luego, ingresanocuando se te solicite la finalización. El nodo vuelve a mostrar la siguiente opción después de9a:(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. ```Ejecuta la operación
9apara todos los nodos de almacenamiento que existen en el clúster antes de continuar.Para cada nodo, ejecuta la opción
9by, luego, ingresayespara confirmar.(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu.Si hay un par de HA, se mostrará el siguiente mensaje. Asegúrate de que todos los nodos del clúster hayan completado el paso 9a antes de ejecutar el paso 9b en ellos.
Selection (9a-9f)?: 9b 9b Option (9a) MUST BE COMPLETED on BOTH nodes in an HA pair (and DR/DR-AUX partner nodes if applicable) prior to starting option (9b). Has option (9a) been completed on all the nodes (yes/no)? yes yes
Cuando se muestre el mensaje
Welcome to the cluster setup wizard, se habrá completado el restablecimiento.
6.7. Cómo restablecer el Thales k570
Para restablecer el Thales k570, comienza por restablecer la configuración de fábrica de Ciphertrust Manager y, luego, restablece el HSM de Luna.
6.7.1. Restablecimiento de la configuración de fábrica del sistema
Crea un directorio de trabajo temporal para las credenciales del HSM:
TMPPWDDIR=/run/user/$(id --user)/hsm mkdir -p $TMPPWDDIR chmod 700 $TMPPWDDIREstablece una conexión SSH al HSM:
export ADMIN_SSH_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[].metadata.name | tr -d '"' | grep "ssh"` kubectl get secret $ADMIN_SSH_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.ssh-privatekey}' \ | base64 --decode > $TMPPWDDIR/hsm-ssh-privatekey chmod 0600 $TMPPWDDIR/hsm-ssh-privatekey ssh -i $TMPPWDDIR/hsm-ssh-privatekey ksadmin@$HSM_MGMT_IPSi esto no es posible, conéctate con un cable serial desde tu computadora al puerto de la consola. Ejecuta el siguiente comando en otra pestaña para obtener la contraseña de
ksadmin.export KSADMIN_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[]metadata.name | tr -d '"' | grep "ksadmin"` kubectl get secret $KSADMIN_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.password}' \ | base64 --decodeUna vez que accedas a la consola serial, verás una solicitud de acceso. Ingresa el nombre de usuario como
ksadminy pega la contraseña del comando anterior.Antes de ejecutar el comando
factory-reset, haz lo siguiente:Evita reiniciar el sistema durante este tiempo, ya que la reconexión implica un reinicio múltiple del sistema y no se puede deshacer.
Asegúrate de tener una batería de respaldo.
Ejecuta el siguiente comando para restablecer la configuración de fábrica:
sudo /opt/keysecure/ks_reset_to_factory.shEl proceso de restablecimiento tarda alrededor de 10 minutos en completarse.
6.7.2. Restablecimiento del HSM de Luna
El restablecimiento de la configuración de fábrica del sistema no borra la raíz de confianza de los HSM. Ejecuta los siguientes comandos para restablecer el HSM de Luna:
Desde el host de CipherTrust Manager, ya sea a través de SSH o de la consola serial, ejecuta el siguiente comando:
/usr/safenet/lunaclient/bin/lunacmlunacm:> hsm factoryResetBorra el directorio de trabajo temporal del programa de arranque:
rm $TMPPWDDIR
6.8. Restablecer firewalls
Si deseas obtener instrucciones para restablecer la configuración de fábrica de tus firewalls, consulta Restablecimiento de fábrica del firewall.
6.9. Cómo restablecer los conmutadores de Cisco
Sigue estos pasos para restablecer los conmutadores de Cisco. Ten en cuenta que estas instrucciones también se aplican a los cambios de almacenamiento, como stgesw.
- Accede a los conmutadores.
Escribe, borra y vuelve a cargar los interruptores:
write erase reloadSi los parámetros de configuración ya se establecieron y tienes un directorio
cellcfgdisponible, puedes seguir los pasos de Limpieza previa al vuelo.Verifica que los conmutadores estén en el aprovisionamiento automático de encendido (POAP).
Si el conmutador se restablece correctamente, debería aparecer el siguiente mensaje cuando te conectes a él con el servidor de la consola:
Abort Power On Auto Provisioning [yes - continue with normal setup, skip - bypass password and basic configuration, no - continue with Power On Auto Provisioning] (yes/skip/no)[no]:
6.10. Recursos adicionales sobre el proceso de restablecimiento
Para obtener más información sobre el proceso de restablecimiento, consulta los siguientes recursos:
https://docs.netapp.com/us-en/ontap/system-admin/manage-node-boot-menu-task.htmlhttps://docs.netapp.com/us-en/ontap/encryption-at-rest/return-seds-unprotected-mode-task.html