Visual Question Answering (VQA) lets you provide an image to the model and ask a question about the image's contents. In response to your question you get one or more natural language answers.
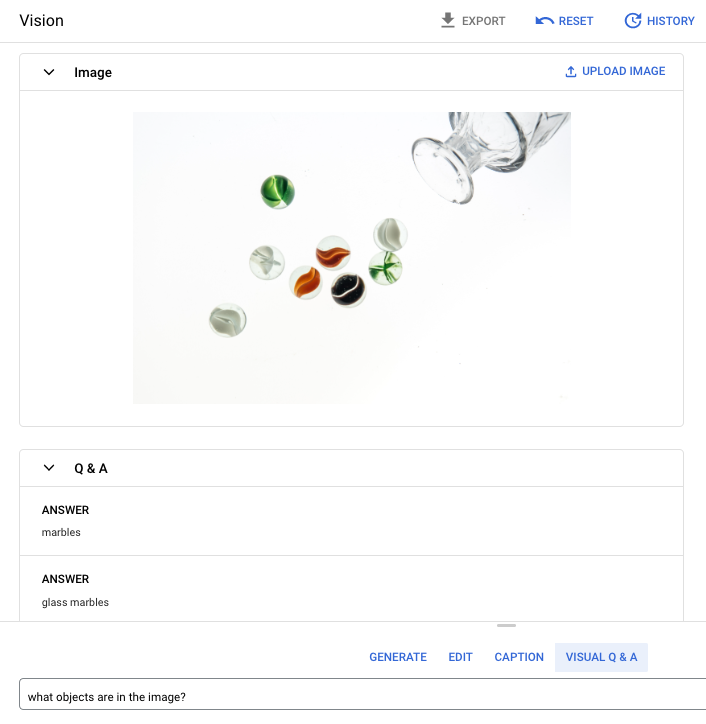
Prompt question: What objects are in the image?
Answer 1: marbles
Answer 2: glass marbles
Languages supported
VQA is available in the following languages:
- English (en)
Performance and limitations
The following limits apply when you use this model:
| Limits | Value |
|---|---|
| Maximum number of API requests (short-form) per minute per project | 500 |
| Maximum number of tokens returned in response (short-form) | 64 tokens |
| Maximum number of tokens accepted in request (VQA short-form only) | 80 tokens |
The following service latency estimates apply when you use this model. These values are meant to be illustrative and are not a promise of service:
| Latency | Value |
|---|---|
| API requests (short-form) | 1.5 seconds |
Locations
A location is a region you can specify in a request to control where data is stored at rest. For a list of available regions, see Generative AI on Vertex AI locations.
Responsible AI safety filtering
The image captioning and Visual Question Answering (VQA) feature model doesn't support user-configurable safety filters. However, the overall Imagen safety filtering occurs on the following data:
- User input
- Model output
As a result, your output may differ from the sample output if Imagen applies these safety filters. Consider the following examples.
Filtered input
If the input is filtered, the response is similar to the following:
{
"error": {
"code": 400,
"message": "Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.DebugInfo",
"detail": "[ORIGINAL ERROR] generic::invalid_argument: Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394 [google.rpc.error_details_ext] { message: \"Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394\" }"
}
]
}
}
Filtered output
If the number of responses returned is less than the sample count you specify,
this means the missing responses are filtered by Responsible AI. For example,
the following is a response to a request with "sampleCount": 2, but one of the
responses is filtered out:
{
"predictions": [
"cappuccino"
]
}
If all the output is filtered, the response is an empty object similar to the following:
{}
Use VQA on an image (short-form responses)
Use the following samples to ask a question and get an answer about an image.
REST
For more information about imagetext model requests, see the
imagetext model API reference.
Before using any of the request data, make the following replacements:
- PROJECT_ID: Your Google Cloud project ID.
- LOCATION: Your project's region. For example,
us-central1,europe-west2, orasia-northeast3. For a list of available regions, see Generative AI on Vertex AI locations. - VQA_PROMPT: The question you want to get answered about your image.
- What color is this shoe?
- What type of sleeves are on the shirt?
- B64_IMAGE: The image to get captions for. The image must be specified as a base64-encoded byte string. Size limit: 10 MB.
- RESPONSE_COUNT: The number of answers you want to generate. Accepted integer values: 1-3.
HTTP method and URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict
Request JSON body:
{
"instances": [
{
"prompt": "VQA_PROMPT",
"image": {
"bytesBase64Encoded": "B64_IMAGE"
}
}
],
"parameters": {
"sampleCount": RESPONSE_COUNT
}
}
To send your request, choose one of these options:
curl
Save the request body in a file named request.json,
and execute the following command:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict"
PowerShell
Save the request body in a file named request.json,
and execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict" | Select-Object -Expand Content
"sampleCount": 2 and "prompt": "What is this?". The response returns
two prediction string answers.
{
"predictions": [
"cappuccino",
"coffee"
]
}
Python
Before trying this sample, follow the Python setup instructions in the Vertex AI quickstart using client libraries. For more information, see the Vertex AI Python API reference documentation.
To authenticate to Vertex AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
In this sample you use the load_from_file method to reference a local file as
the base Image to get information about. After you specify the base
image, you use the ask_question method on the
ImageTextModel and print the answers.
Use parameters for VQA
When you get VQA responses there are several parameters you can set depending on your use case.
Number of results
Use the number of results parameter to limit the amount of responses returned
for each request you send. For more information, see the imagetext (VQA)
model API reference.
Seed number
A number you add to a request to make generated responses deterministic. Adding
a seed number with your request is a way to assure you get the same prediction
(responses) each time. However, the answers aren't
necessarily returned in the same order. For more information, see the
imagetext (VQA) model API reference.
What's next
- View videos describing Vertex AI foundation models including Imagen, the text-to-image foundation model that lets you generate and edit images:
- Read blog posts describing Imagen on Vertex AI and Generative AI on Vertex AI: